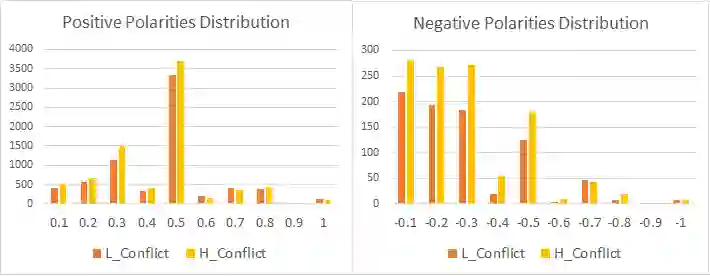
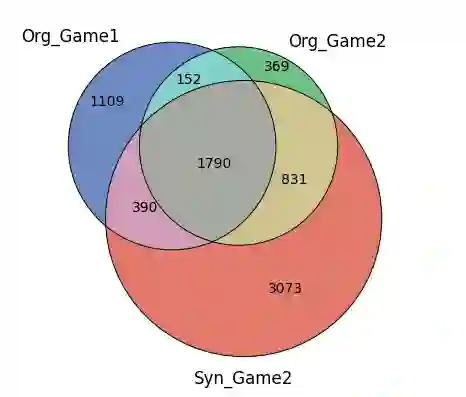
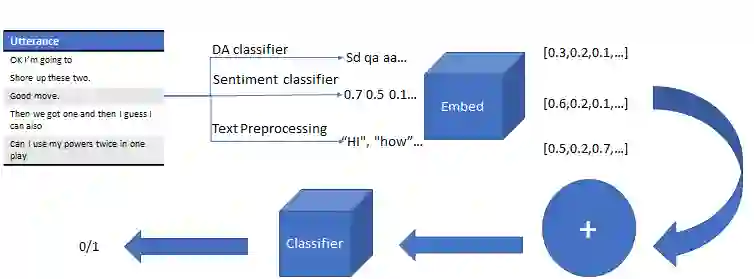
Conflict prediction in communication is integral to the design of virtual agents that support successful teamwork by providing timely assistance. The aim of our research is to analyze discourse to predict collaboration success. Unfortunately, resource scarcity is a problem that teamwork researchers commonly face since it is hard to gather a large number of training examples. To alleviate this problem, this paper introduces a multi-feature embedding (MFeEmb) that improves the generalizability of conflict prediction models trained on dialogue sequences. MFeEmb leverages textual, structural, and semantic information from the dialogues by incorporating lexical, dialogue acts, and sentiment features. The use of dialogue acts and sentiment features reduces performance loss from natural distribution shifts caused mainly by changes in vocabulary. This paper demonstrates the performance of MFeEmb on domain adaptation problems in which the model is trained on discourse from one task domain and applied to predict team performance in a different domain. The generalizability of MFeEmb is quantified using the similarity measure proposed by Bontonou et al. (2021). Our results show that MFeEmb serves as an excellent domain-agnostic representation for meta-pretraining a few-shot model on collaborative multiparty dialogues.
翻译:对话中的冲突预测对于设计能够通过及时协助支持成功团队协作的虚拟智能体至关重要。本研究旨在分析话语以预测协作成功。然而,资源稀缺是团队协作研究者普遍面临的问题,因为收集大量训练样本存在困难。为缓解该问题,本文提出一种多特征嵌入方法(MFeEmb),可提升基于对话序列训练的冲突预测模型的泛化能力。MFeEmb通过融合词汇特征、对话行为特征和情感特征,充分利用对话中的文本、结构和语义信息。对话行为与情感特征的引入有效减少了主要由词汇变化引起的自然分布偏移导致的性能损失。本文在域适应问题中验证了MFeEmb的性能:模型在一个任务领域的话语上训练后,应用于预测不同领域的团队表现。采用Bontonou等人(2021)提出的相似度度量方法对MFeEmb的泛化能力进行量化评估。结果表明,MFeEmb可作为优秀的领域无关表示,用于协作多轮对话中少样本模型的元预训练。