
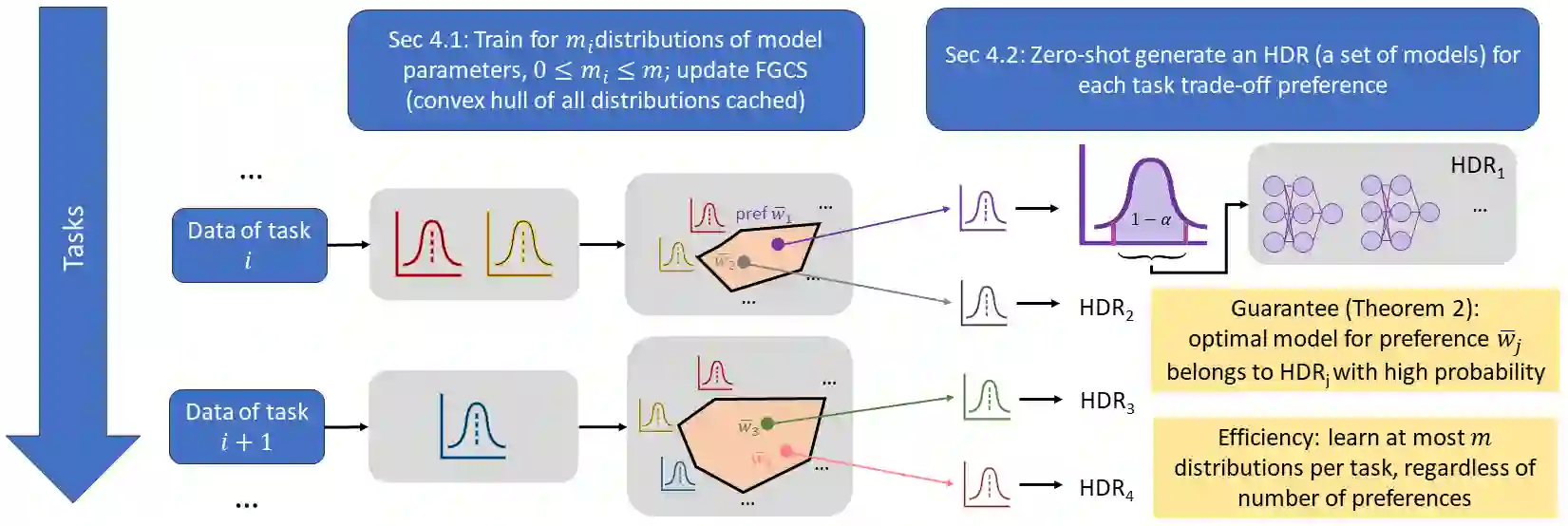
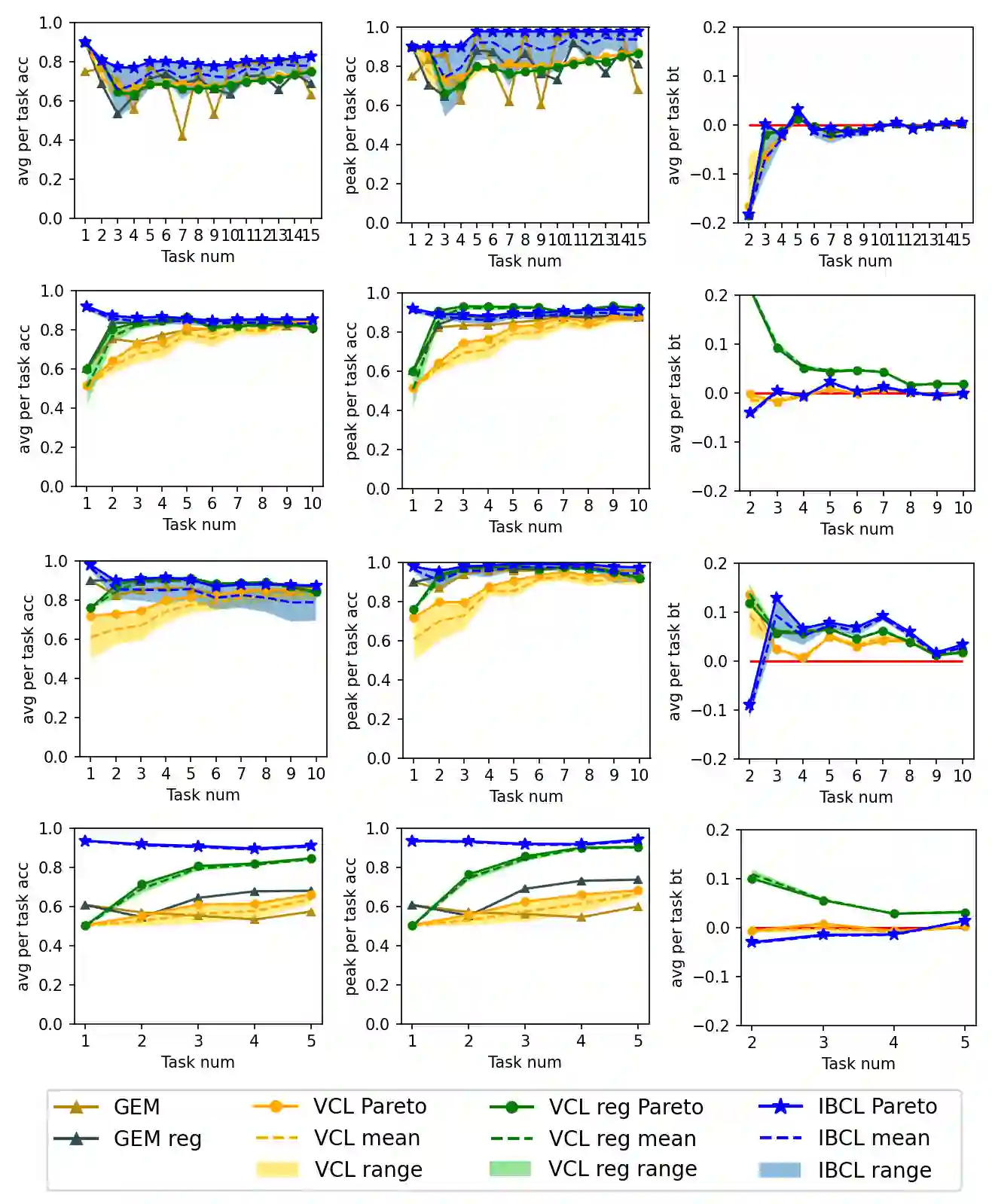
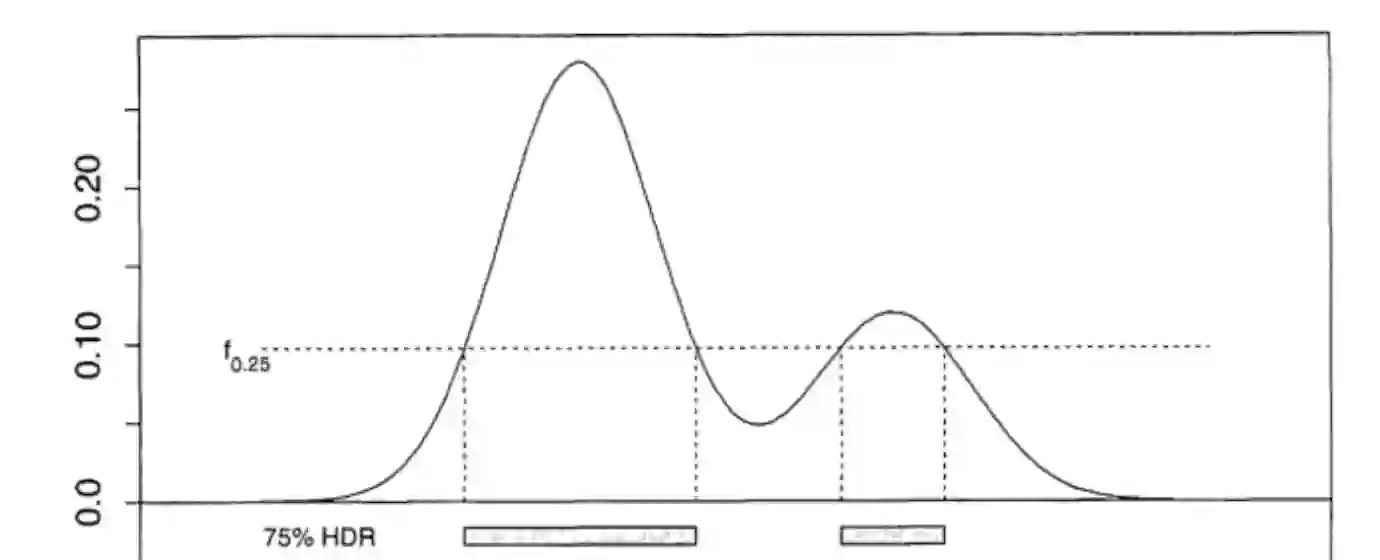
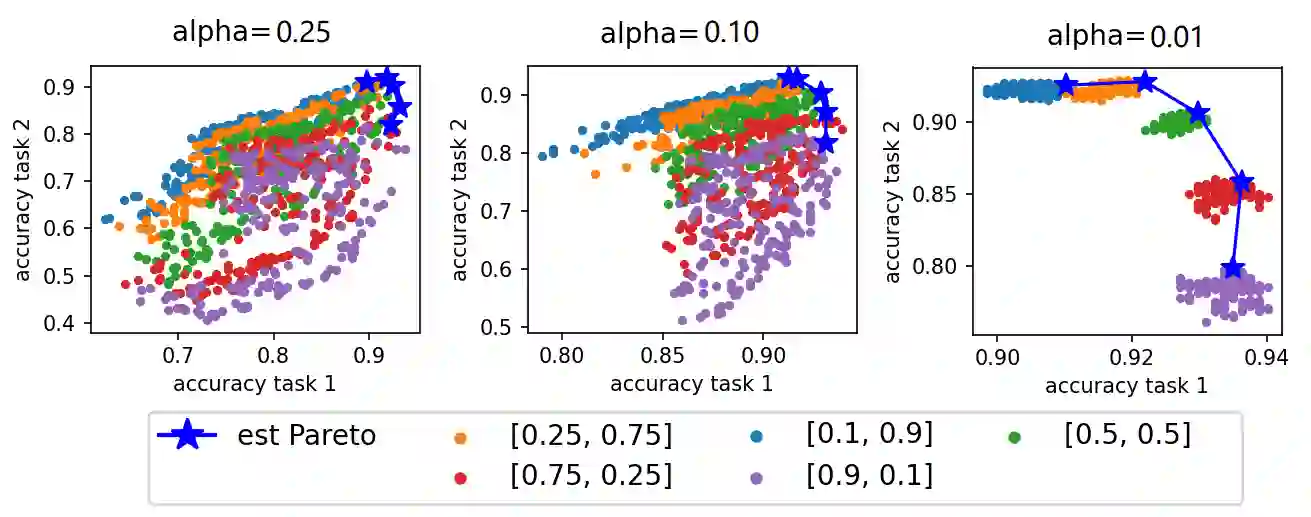
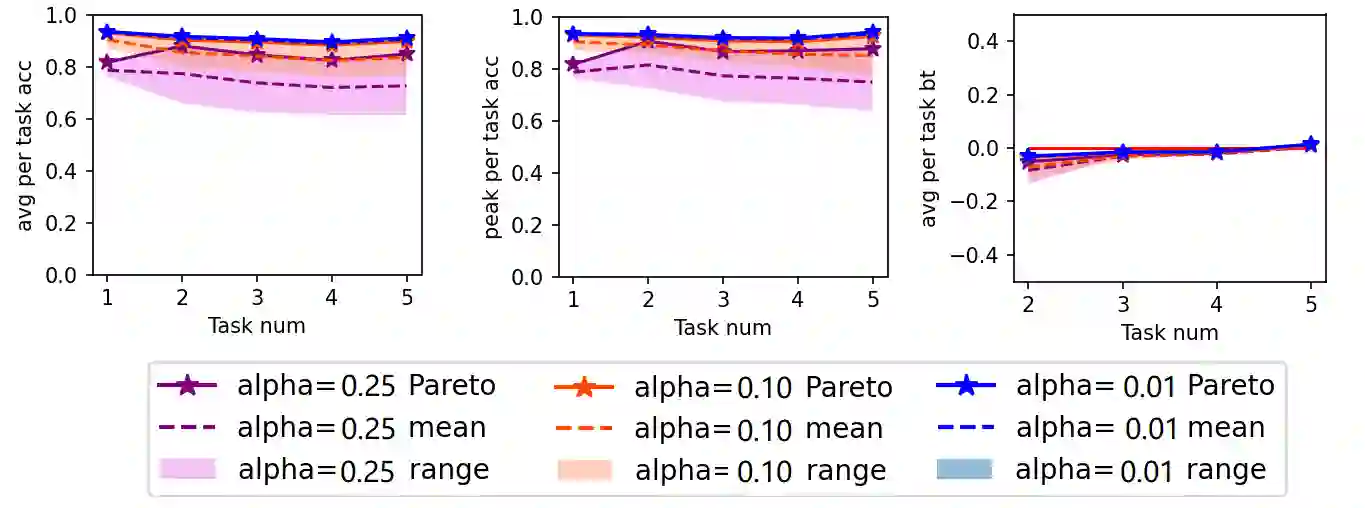
Like generic multi-task learning, continual learning has the nature of multi-objective optimization, and therefore faces a trade-off between the performance of different tasks. That is, to optimize for the current task distribution, it may need to compromise performance on some previous tasks. This means that there exist multiple models that are Pareto-optimal at different times, each addressing a distinct task performance trade-off. Researchers have discussed how to train particular models to address specific trade-off preferences. However, existing algorithms require training overheads proportional to the number of preferences -- a large burden when there are multiple, possibly infinitely many, preferences. As a response, we propose Imprecise Bayesian Continual Learning (IBCL). Upon a new task, IBCL (1) updates a knowledge base in the form of a convex hull of model parameter distributions and (2) obtains particular models to address task trade-off preferences with zero-shot. That is, IBCL does not require any additional training overhead to generate preference-addressing models from its knowledge base. We show that models obtained by IBCL have guarantees in identifying the Pareto optimal parameters. Moreover, experiments on standard image classification and NLP tasks support this guarantee. Statistically, IBCL improves average per-task accuracy by at most 23\% and peak per-task accuracy by at most 15\% with respect to the baseline methods, with steadily near-zero or positive backward transfer. Most importantly, IBCL significantly reduces the training overhead from training 1 model per preference to at most 3 models for all preferences.
翻译:如同通用的多任务学习,持续学习具有多目标优化的特性,因此面临不同任务性能之间的权衡。即为了优化当前任务分布,可能需要牺牲某些先前任务的性能。这意味着存在多个在不同时间点达到帕累托最优的模型,每个模型应对不同的任务性能权衡。研究者们已探讨如何训练特定模型以应对具体的权衡偏好,但现有算法所需的训练开销与偏好数量成正比——当存在多个乃至无穷多个偏好时,这一负担将极为沉重。为此,我们提出不精确贝叶斯持续学习(IBCL)。面对新任务时,IBCL(1)以模型参数分布的凸包形式更新知识库,(2)零样本获取应对任务权衡偏好的特定模型。即IBCL无需额外训练开销即可从其知识库生成偏好应对模型。我们证明IBCL获得的模型在识别帕累托最优参数方面具有保证。此外,标准图像分类与NLP任务的实验支持了这一保证。统计上,与基线方法相比,IBCL的平均每任务准确率最高提升23%,峰值每任务准确率最高提升15%,并持续保持接近零或正向的后向迁移。最重要的是,IBCL将训练开销从每个偏好训练1个模型显著降低至所有偏好最多仅需3个模型。
相关内容

Source: Apple - iOS 8

