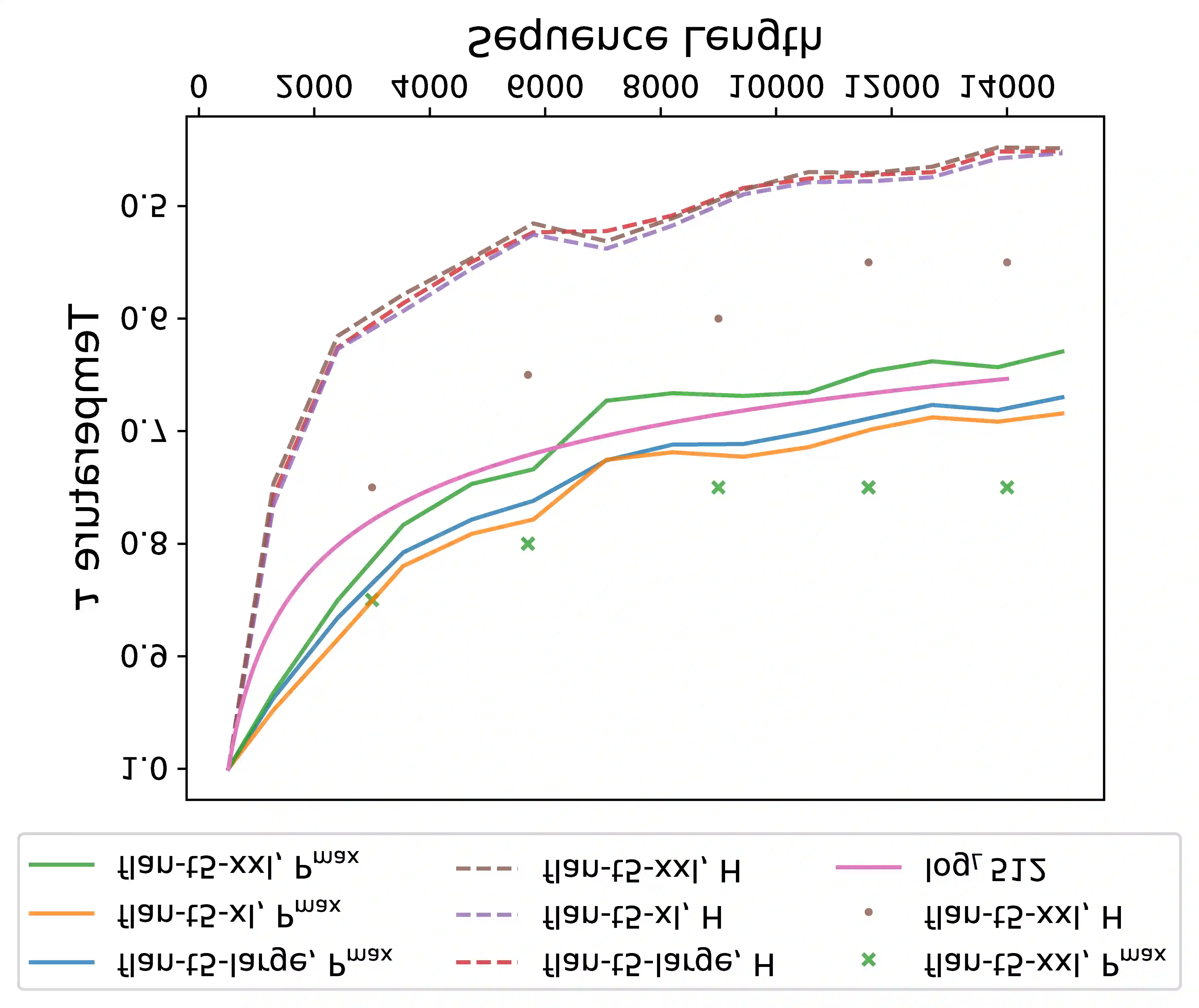
An ideal length-extrapolatable Transformer language model can handle sequences longer than the training length without any long sequence fine-tuning. Such long-context utilization capability highly relies on a flexible positional embedding design. Upon investigating the flexibility of existing large pre-trained Transformer language models, we find that the T5 family deserves a closer look, as its positional embeddings capture rich and flexible attention patterns. However, T5 suffers from the dispersed attention issue: the longer the input sequence, the flatter the attention distribution. To alleviate the issue, we propose two attention alignment strategies via temperature scaling. Our findings improve the long-context utilization capability of T5 on language modeling, retrieval, and multi-document question answering without any fine-tuning, suggesting that a flexible positional embedding design and attention alignment go a long way toward Transformer length extrapolation.\footnote{\url{https://github.com/chijames/Attention-Alignment-Transformer-Length-Extrapolation}}
翻译:理想的长度可外推Transformer语言模型无需长序列微调,即可处理超过训练长度的序列。此类长上下文利用能力高度依赖于柔性的位置嵌入设计。通过考察现有大型预训练Transformer语言模型中位置嵌入的灵活性,我们发现T5系列值得深入探究——其位置嵌入能捕获丰富且灵活注意力模式。然而T5存在注意力分散问题:输入序列越长,注意力分布越平坦。为缓解该问题,我们提出两种基于温度缩放的注意力对齐策略。实验表明,我们的方法在语言建模、检索和多文档问答任务中提升了T5的长上下文利用能力,且无需任何微调,从而证实柔性位置嵌入设计与注意力对齐对实现Transformer长度外推具有关键作用。\footnote{\url{https://github.com/chijames/Attention-Alignment-Transformer-Length-Extrapolation}}