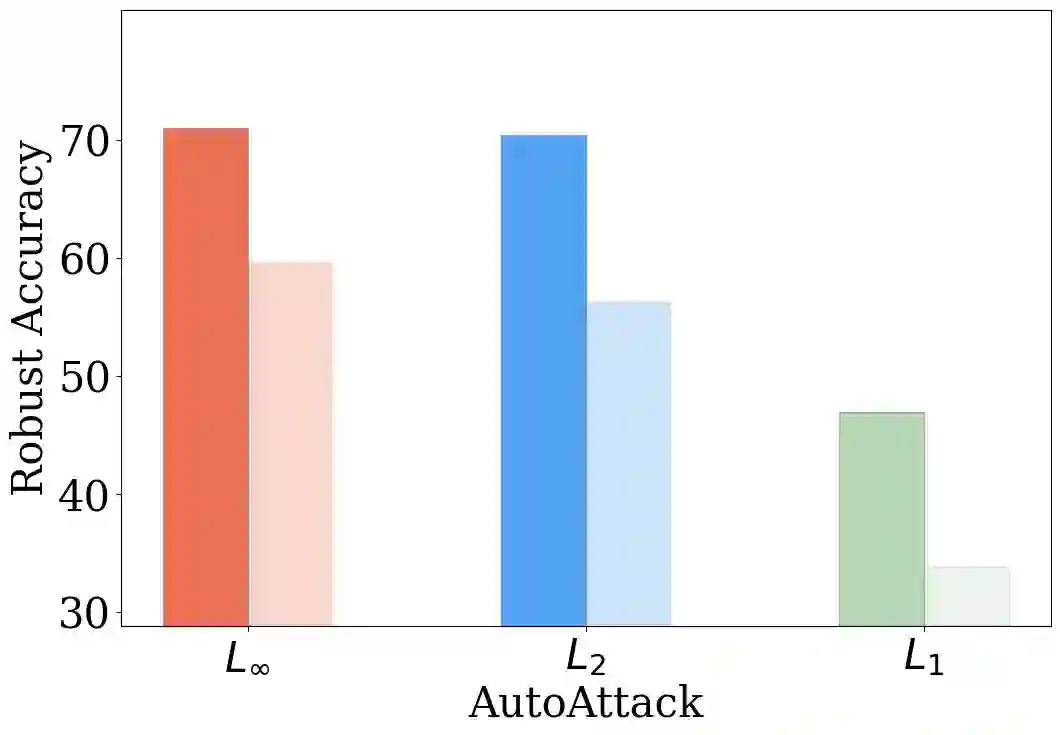
The machine learning community has witnessed a drastic change in the training pipeline, pivoted by those ''foundation models'' with unprecedented scales. However, the field of adversarial training is lagging behind, predominantly centered around small model sizes like ResNet-50, and tiny and low-resolution datasets like CIFAR-10. To bridge this transformation gap, this paper provides a modern re-examination with adversarial training, investigating its potential benefits when applied at scale. Additionally, we introduce an efficient and effective training strategy to enable adversarial training with giant models and web-scale data at an affordable computing cost. We denote this newly introduced framework as AdvXL. Empirical results demonstrate that AdvXL establishes new state-of-the-art robust accuracy records under AutoAttack on ImageNet-1K. For example, by training on DataComp-1B dataset, our AdvXL empowers a vanilla ViT-g model to substantially surpass the previous records of $l_{\infty}$-, $l_{2}$-, and $l_{1}$-robust accuracy by margins of 11.4%, 14.2% and 12.9%, respectively. This achievement posits AdvXL as a pioneering approach, charting a new trajectory for the efficient training of robust visual representations at significantly larger scales. Our code is available at https://github.com/UCSC-VLAA/AdvXL.
翻译:机器学习领域见证了训练流程的剧烈变革,这种变革由那些具有空前规模的“基础模型”所推动。然而,对抗训练领域却相对滞后,主要集中在小规模模型(如ResNet-50)以及小型低分辨率数据集(如CIFAR-10)上。为弥合这一转型差距,本文对对抗训练进行了现代重新审视,探究其在大规模应用时的潜在优势。此外,我们引入了一种高效且有效的训练策略,使得在可负担的计算成本下,能够对巨型模型和网络规模数据进行对抗训练。我们将这一新提出的框架称为AdvXL。实验结果表明,AdvXL在ImageNet-1K上建立了AutoAttack攻击下鲁棒准确率的新最先进记录。例如,通过在DataComp-1B数据集上训练,我们的AdvXL使得原始ViT-g模型在$l_{\infty}$、$l_{2}$和$l_{1}$鲁棒准确率上,分别大幅超越了此前记录11.4%、14.2%和12.9%。这一成就将AdvXL定位为一种开创性方法,为在显著更大规模上高效训练鲁棒视觉表征描绘了新轨迹。我们的代码可在https://github.com/UCSC-VLAA/AdvXL获取。