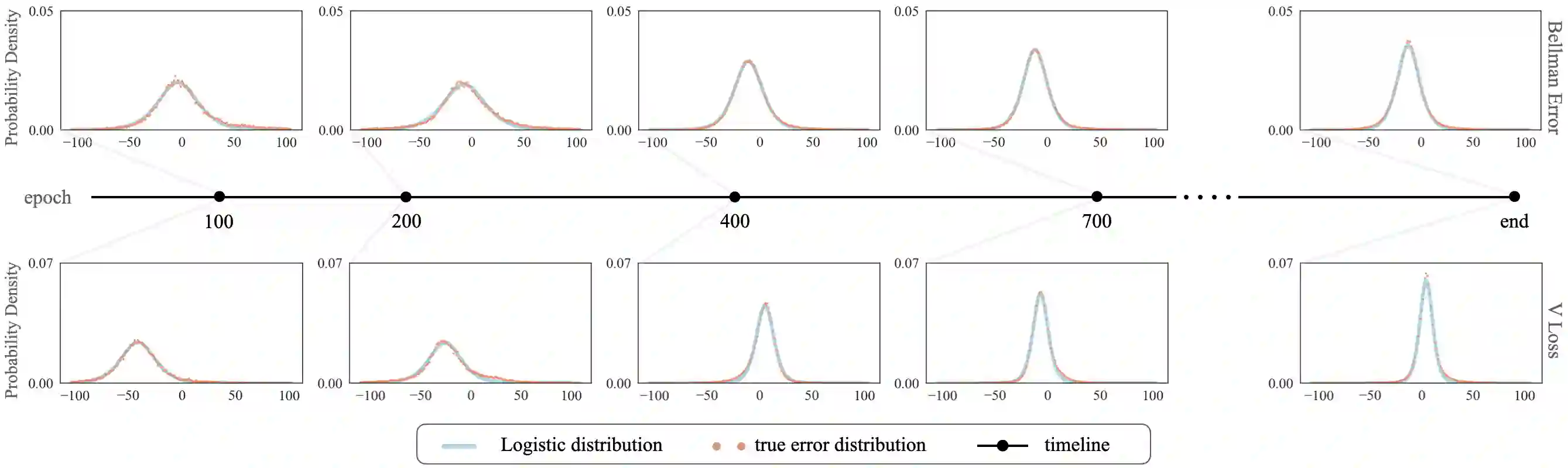
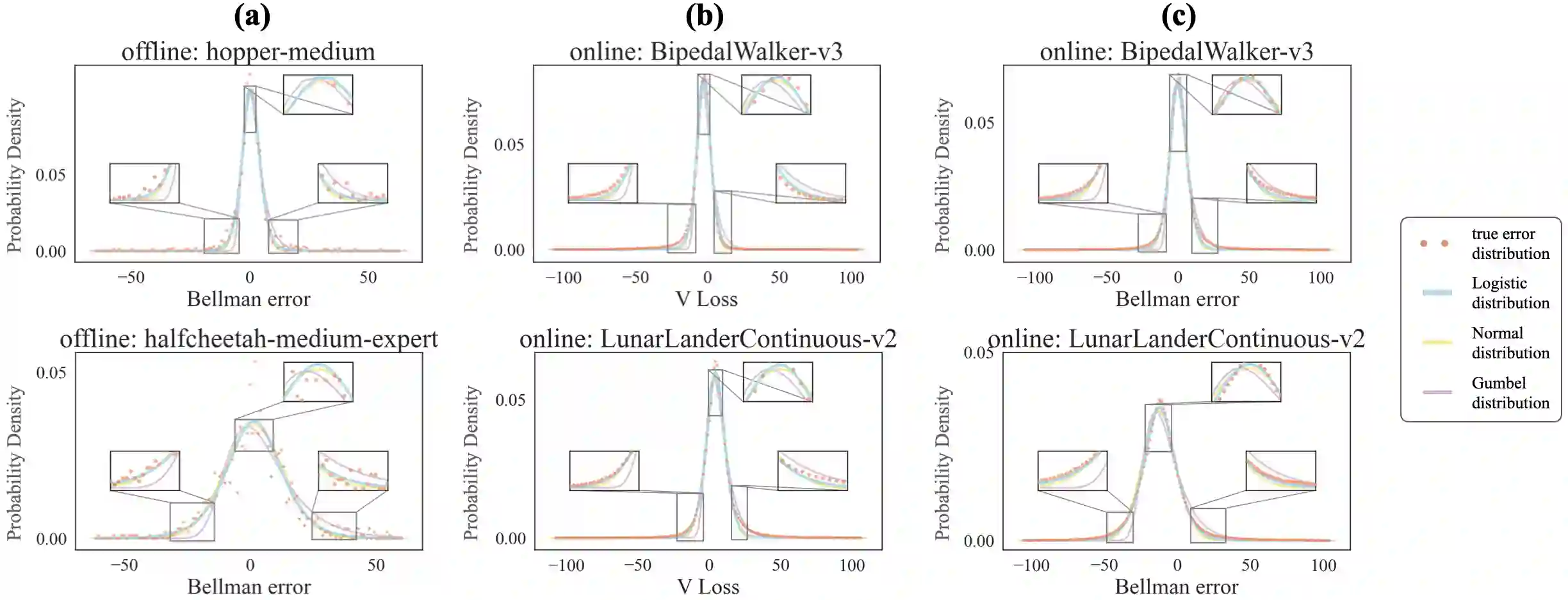
Modern reinforcement learning (RL) can be categorized into online and offline variants. As a pivotal aspect of both online and offline RL, current research on the Bellman equation revolves primarily around optimization techniques and performance enhancement rather than exploring the inherent structural properties of the Bellman error, such as its distribution characteristics. This study investigates the distribution of the Bellman approximation error in both online and offline settings through iterative exploration of the Bellman equation. We observed that both in online RL and offline RL, the Bellman error conforms to a Logistic distribution. Building upon this discovery, this study employed the Logistics maximum likelihood function (LLoss) as an alternative to the commonly used MSE Loss, assuming that Bellman errors adhere to a normal distribution. We validated our hypotheses through extensive numerical experiments across diverse online and offline environments. In particular, we applied corrections to the loss function across various baseline algorithms and consistently observed that the loss function with Logistic corrections outperformed the MSE counterpart significantly. Additionally, we conducted Kolmogorov-Smirnov tests to confirm the reliability of the Logistic distribution. This study's theoretical and empirical insights provide valuable groundwork for future investigations and enhancements centered on the distribution of Bellman errors.
翻译:现代强化学习可分为在线与离线两种变体。作为在线与离线强化学习的关键方面,当前对贝尔曼方程的研究主要围绕优化技术和性能提升展开,而非探索贝尔曼误差的内在结构性质(如分布特征)。本研究通过迭代探索贝尔曼方程,在在线与离线设定下系统考察了贝尔曼近似误差的分布。我们观察到,无论是在线强化学习还是离线强化学习,贝尔曼误差均服从逻辑分布。基于此发现,本研究采用逻辑分布的最大似然函数替代常用的MSE损失(该损失默认贝尔曼误差服从正态分布)。通过在不同在线与离线环境下的广泛数值实验,我们验证了这一假设。特别是,我们在多种基线算法中应用了修正后的损失函数,并一致观察到采用逻辑分布修正的损失函数性能显著优于MSE损失。此外,我们通过柯尔莫哥洛夫-斯米尔诺夫检验进一步证实了逻辑分布的可靠性。本研究的理论与实证发现为未来围绕贝尔曼误差分布展开的探索与改进提供了宝贵的基础框架。