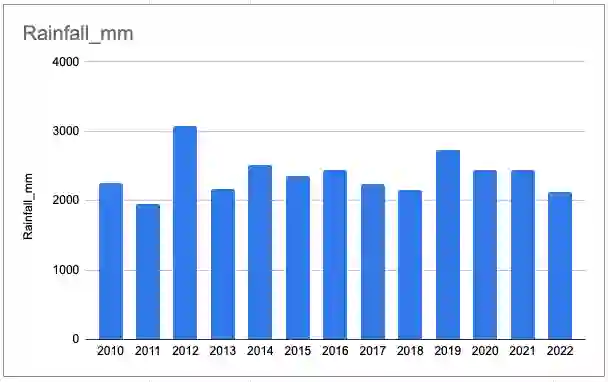
Can large language models assist in data discovery? Data discovery predominantly happens via search on a data portal or the web, followed by assessment of the dataset to ensure it is fit for the intended purpose. The ability of conversational generative AI (CGAI) to support recommendations with reasoning implies it can suggest datasets to users, explain why it has done so, and provide information akin to documentation regarding the dataset in order to support a use decision. We hold 3 workshops with data users and find that, despite limitations around web capabilities, CGAIs are able to suggest relevant datasets and provide many of the required sensemaking activities, as well as support dataset analysis and manipulation. However, CGAIs may also suggest fictional datasets, and perform inaccurate analysis. We identify emerging practices in data discovery and present a model of these to inform future research directions and data prompt design.
翻译:大型语言模型能否协助数据发现?数据发现主要通过数据门户或网络搜索进行,随后评估数据集以确保其适合预期用途。对话式生成式人工智能(CGAI)具备基于推理提供推荐的能力,这意味着它可以向用户推荐数据集,解释推荐理由,并提供类似文档的信息以支持使用决策。我们与数据用户举办了三次工作坊,发现尽管在网络功能方面存在局限性,CGAI能够推荐相关数据集,提供许多所需的感性认知活动,并支持数据集的分析与操作。然而,CGAI也可能推荐虚构的数据集,并进行不准确的分析。我们识别出数据发现中的新兴实践,并构建了一个模型,以指导未来研究方向和数据提示设计。