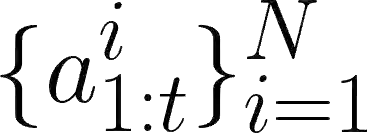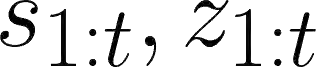Imitation Learning (IL) is a promising paradigm for teaching robots to perform novel tasks using demonstrations. Most existing approaches for IL utilize neural networks (NN), however, these methods suffer from several well-known limitations: they 1) require large amounts of training data, 2) are hard to interpret, and 3) are hard to repair and adapt. There is an emerging interest in programmatic imitation learning (PIL), which offers significant promise in addressing the above limitations. In PIL, the learned policy is represented in a programming language, making it amenable to interpretation and repair. However, state-of-the-art PIL algorithms assume access to action labels and struggle to learn from noisy real-world demonstrations. In this paper, we propose PLUNDER, a novel PIL algorithm that integrates a probabilistic program synthesizer in an iterative Expectation-Maximization (EM) framework to address these shortcomings. Unlike existing PIL approaches, PLUNDER synthesizes probabilistic programmatic policies that are particularly well-suited for modeling the uncertainties inherent in real-world demonstrations. Our approach leverages an EM loop to simultaneously infer the missing action labels and the most likely probabilistic policy. We benchmark PLUNDER against several established IL techniques, and demonstrate its superiority across five challenging imitation learning tasks under noise. PLUNDER policies achieve 95% accuracy in matching the given demonstrations, outperforming the next best baseline by 19%. Additionally, policies generated by PLUNDER successfully complete the tasks 17% more frequently than the nearest baseline.
翻译:模仿学习是一种有前景的范式,可通过演示教会机器人执行新任务。现有大多数模仿学习方法使用神经网络,但这些方法存在若干公认的局限性:1)需要大量训练数据;2)难以解释;3)难以修复和适应。程序化模仿学习这一新兴方向有望克服上述局限。在程序化模仿学习中,学到的策略以编程语言表示,便于解释和修复。然而,现有最先进的程序化模仿学习算法假设能获取动作标签,难以从含噪声的真实世界演示中学习。本文提出PLUNDER算法——一种新型程序化模仿学习算法,它将概率程序合成器集成到迭代期望最大化框架中,以解决上述缺陷。与现有程序化模仿学习方法不同,PLUNDER合成的概率程序化策略特别适用于建模真实世界演示中固有的不确定性。我们的方法利用期望最大化循环同时推断缺失的动作标签和最可能的概率策略。我们将PLUNDER与多种成熟的模仿学习技术进行基准对比,并在含噪声条件下通过五项具有挑战性的模仿学习任务证明其优越性。PLUNDER生成的策略在匹配给定演示方面达到95%的准确率,比次优基线方法高出19%。此外,PLUNDER生成的策略完成任务的成功率比最近的基线方法高出17%。