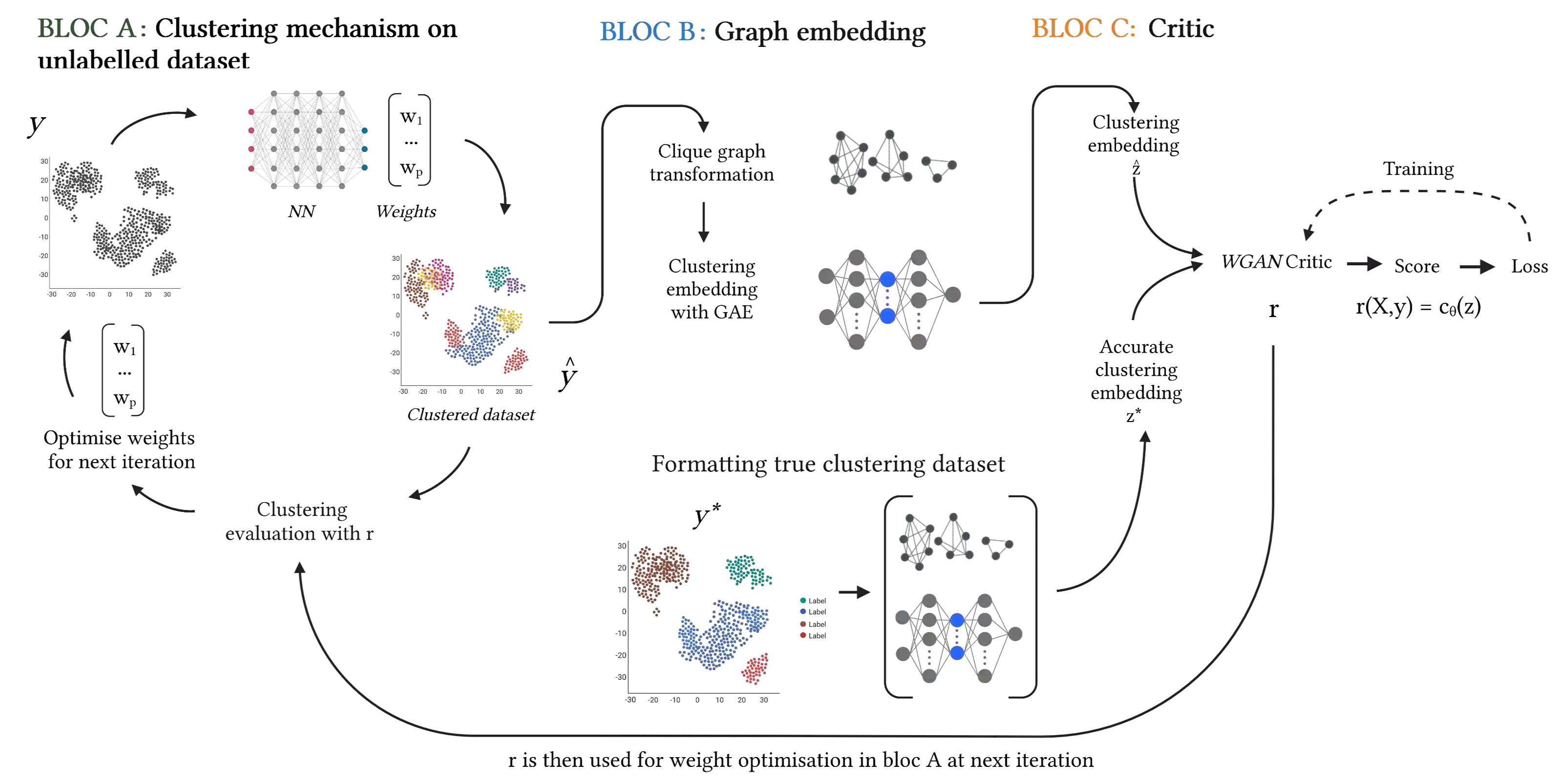
Clustering in high dimension spaces is a difficult task; the usual distance metrics may no longer be appropriate under the curse of dimensionality. Indeed, the choice of the metric is crucial, and it is highly dependent on the dataset characteristics. However a single metric could be used to correctly perform clustering on multiple datasets of different domains. We propose to do so, providing a framework for learning a transferable metric. We show that we can learn a metric on a labelled dataset, then apply it to cluster a different dataset, using an embedding space that characterises a desired clustering in the generic sense. We learn and test such metrics on several datasets of variable complexity (synthetic, MNIST, SVHN, omniglot) and achieve results competitive with the state-of-the-art while using only a small number of labelled training datasets and shallow networks.
翻译:在高维空间中进行聚类是一项困难的任务;在维数灾难的影响下,通常的距离度量可能不再适用。实际上,度量的选择至关重要,且高度依赖于数据集的特性。然而,存在一种单一度量能够正确地对多个不同领域的数据集进行聚类。我们提出了一种框架,用于学习可迁移的度量。我们证明,可以基于标注数据集学习一种度量,然后将其应用于对另一个不同数据集进行聚类,通过使用一个能够从一般意义上表征理想聚类的嵌入空间来实现。我们在多个复杂度不同的数据集(包括合成数据、MNIST、SVHN、omniglot)上学习并测试了此类度量,在使用少量标注训练数据集和浅层网络的情况下,取得了与当前最优方法相竞争的结果。