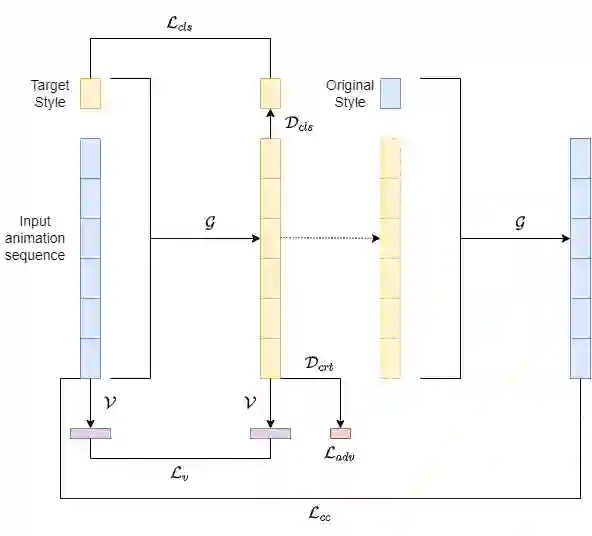
The ability to accurately capture and express emotions is a critical aspect of creating believable characters in video games and other forms of entertainment. Traditionally, this animation has been achieved with artistic effort or performance capture, both requiring costs in time and labor. More recently, audio-driven models have seen success, however, these often lack expressiveness in areas not correlated to the audio signal. In this paper, we present a novel approach to facial animation by taking existing animations and allowing for the modification of style characteristics. Specifically, we explore the use of a StarGAN to enable the conversion of 3D facial animations into different emotions and person-specific styles. We are able to maintain the lip-sync of the animations with this method thanks to the use of a novel viseme-preserving loss.
翻译:精确捕捉和表达情感的能力,是创造电子游戏及其他娱乐形式中可信角色的关键要素。传统上,这种动画通过艺术创作或动作捕捉实现,两者均需耗费时间与人力成本。近年来,音频驱动模型取得了成功,但这些模型在与音频信号无关的区域内常缺乏表现力。本文提出一种新颖的面部动画方法,通过对现有动画进行风格特征修改来实现创新。具体而言,我们探索使用StarGAN将三维面部动画转换为不同情感及个性化风格。借助新型视位保留损失函数,该方法能够保持动画的唇形同步。