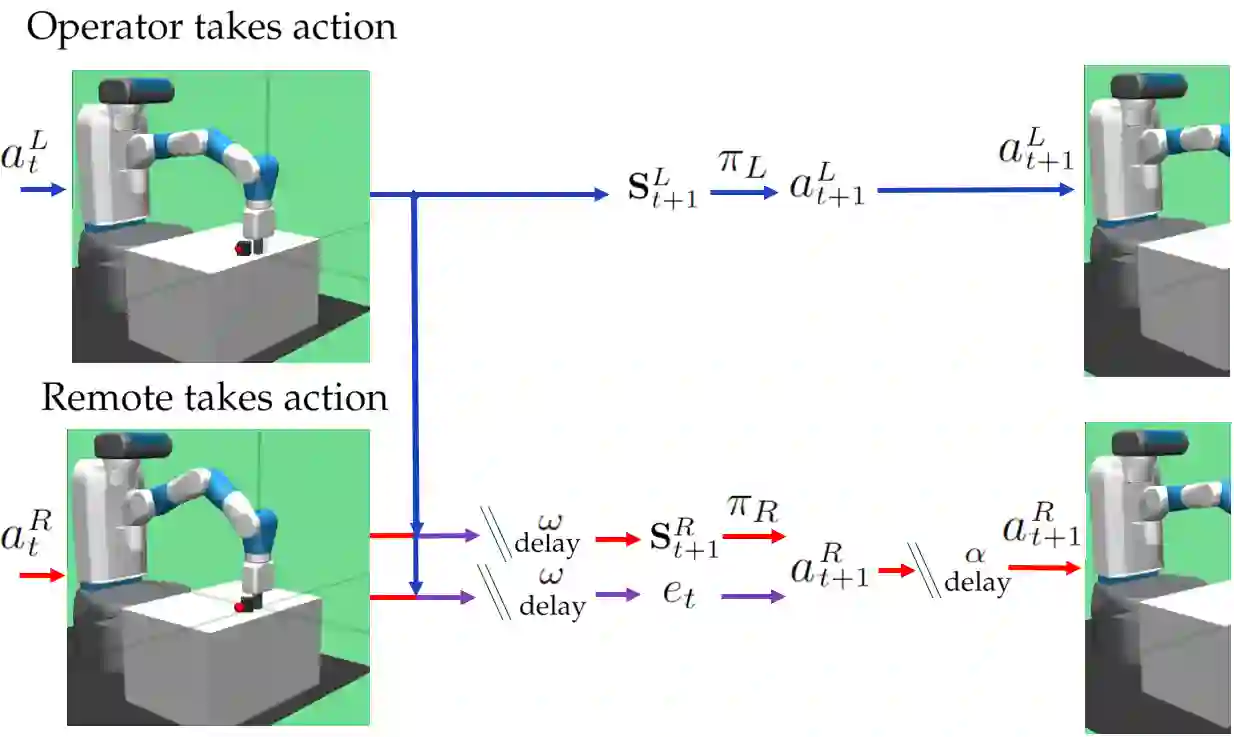
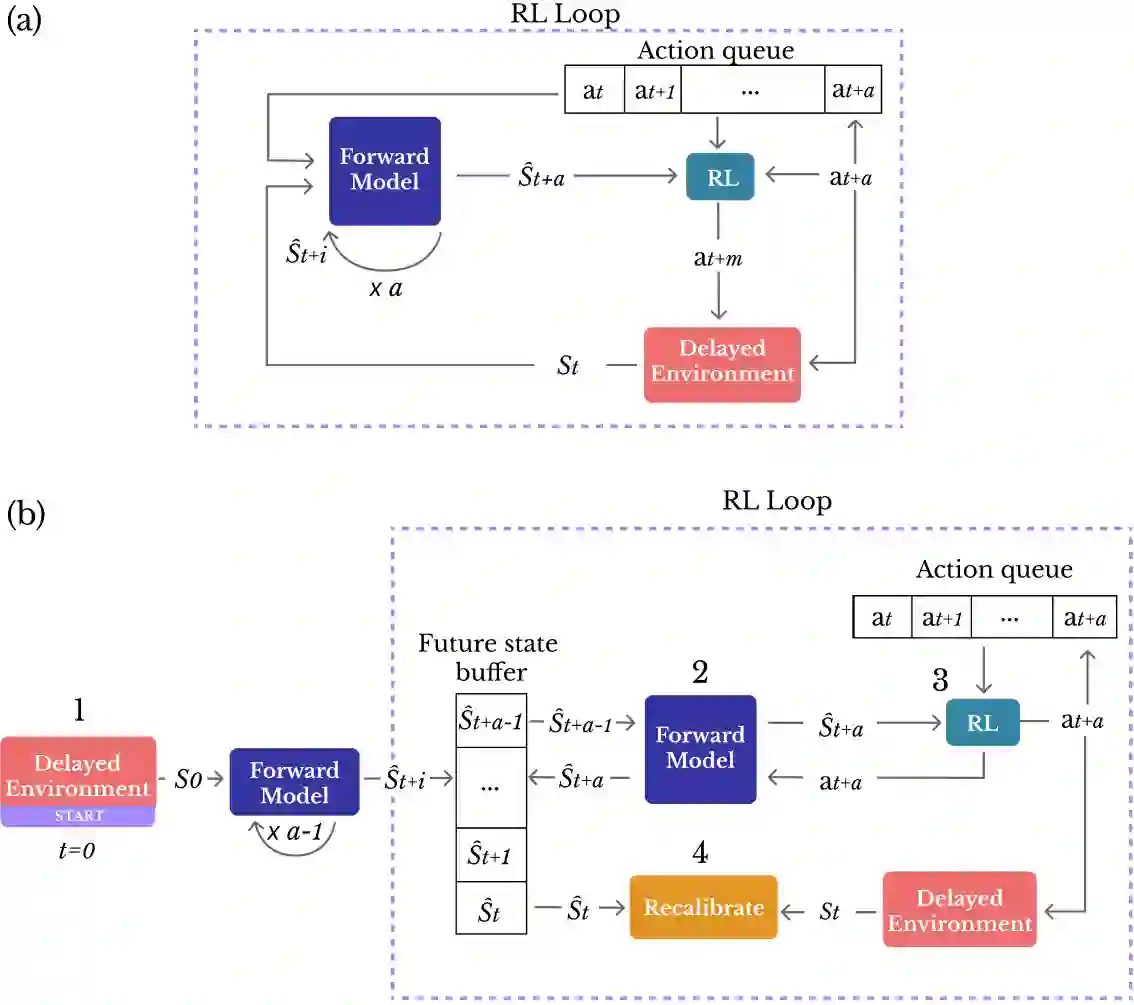
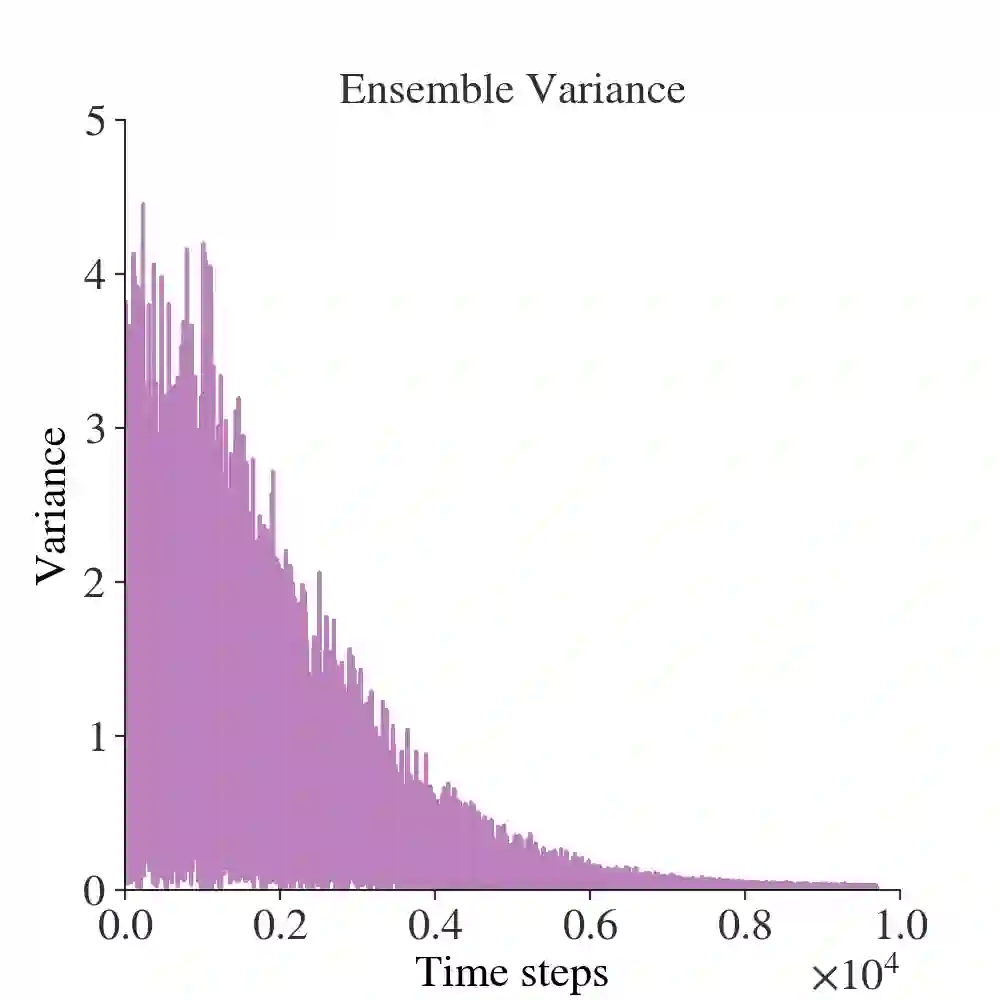
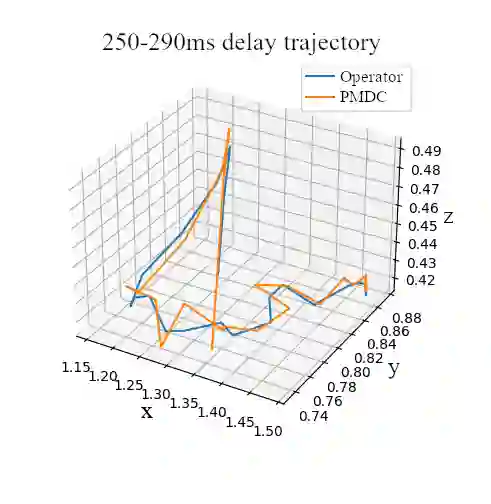
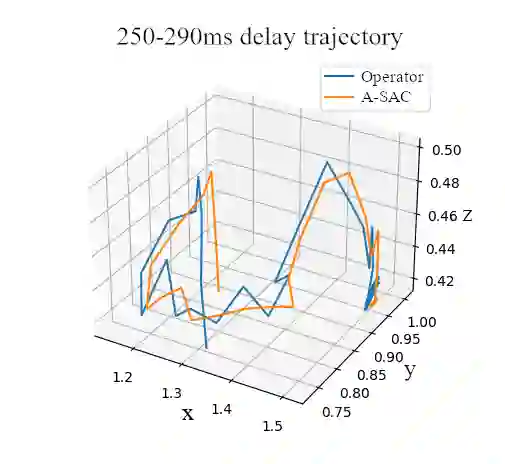
Local-remote systems allow robots to execute complex tasks in hazardous environments such as space and nuclear power stations. However, establishing accurate positional mapping between local and remote devices can be difficult due to time delays that can compromise system performance and stability. Enhancing the synchronicity and stability of local-remote systems is vital for enabling robots to interact with environments at greater distances and under highly challenging network conditions, including time delays. We introduce an adaptive control method employing reinforcement learning to tackle the time-delayed control problem. By adjusting controller parameters in real-time, this adaptive controller compensates for stochastic delays and improves synchronicity between local and remote robotic manipulators. To improve the adaptive PD controller's performance, we devise a model-based reinforcement learning approach that effectively incorporates multi-step delays into the learning framework. Utilizing this proposed technique, the local-remote system's performance is stabilized for stochastic communication time-delays of up to 290ms. Our results demonstrate that the suggested model-based reinforcement learning method surpasses the Soft-Actor Critic and augmented state Soft-Actor Critic techniques. Access the code at: https://github.com/CAV-Research-Lab/Predictive-Model-Delay-Correction
翻译:本地-远程系统允许机器人在太空、核电站等危险环境中执行复杂任务。然而,由于时间延迟会损害系统性能和稳定性,在本地与远程设备之间建立精确的位置映射往往存在困难。增强本地-远程系统的同步性与稳定性对于使机器人能在更大距离及包含时间延迟的高挑战性网络条件下与环境交互至关重要。我们提出一种采用强化学习的自适应控制方法来解决时延控制问题。该自适应控制器通过实时调整控制器参数来补偿随机延迟,并改善本地与远程机械臂之间的同步性。为提升自适应PD控制器的性能,我们设计了一种基于模型的强化学习方法,将多步延迟有效融入学习框架。利用所提出的技术,本地-远程系统可在高达290ms的随机通信时延下保持稳定性能。实验结果表明,所提出的基于模型的强化学习方法优于软演员-评论家及增广状态软演员-评论家技术。代码获取地址:https://github.com/CAV-Research-Lab/Predictive-Model-Delay-Correction