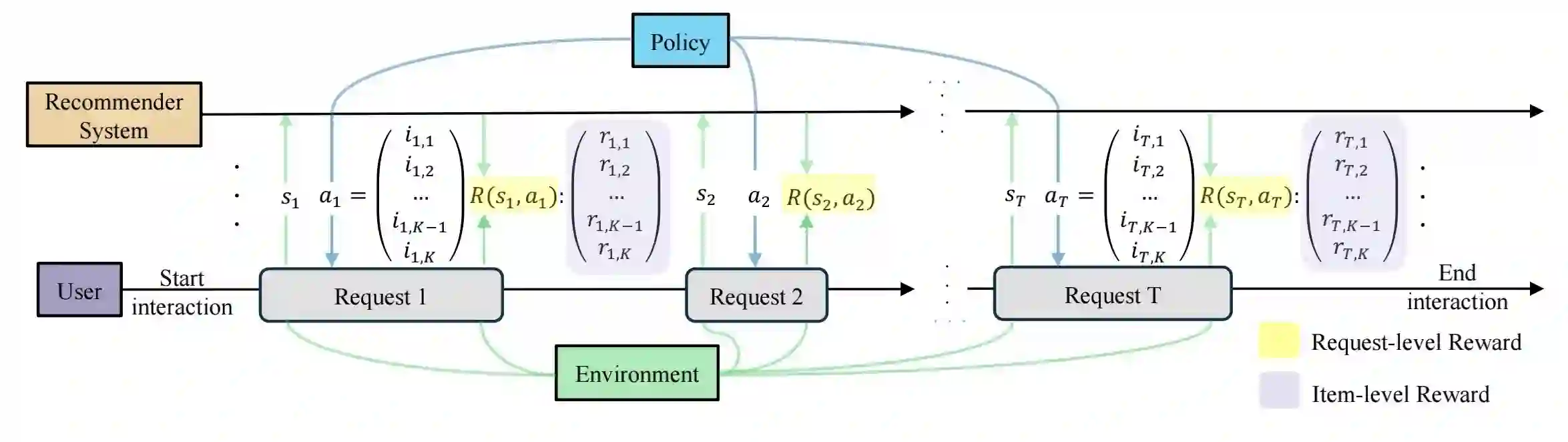
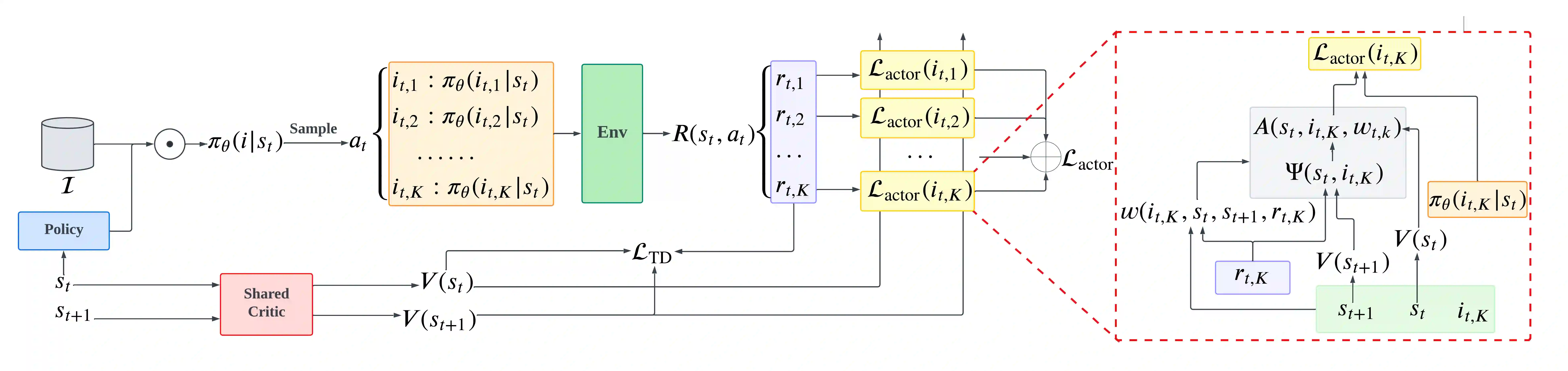
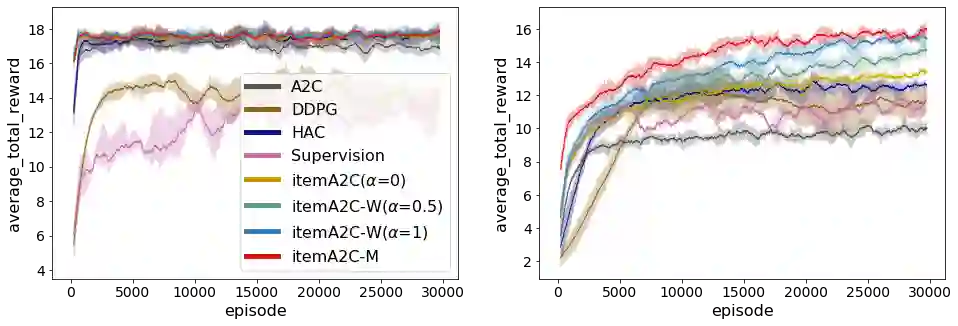
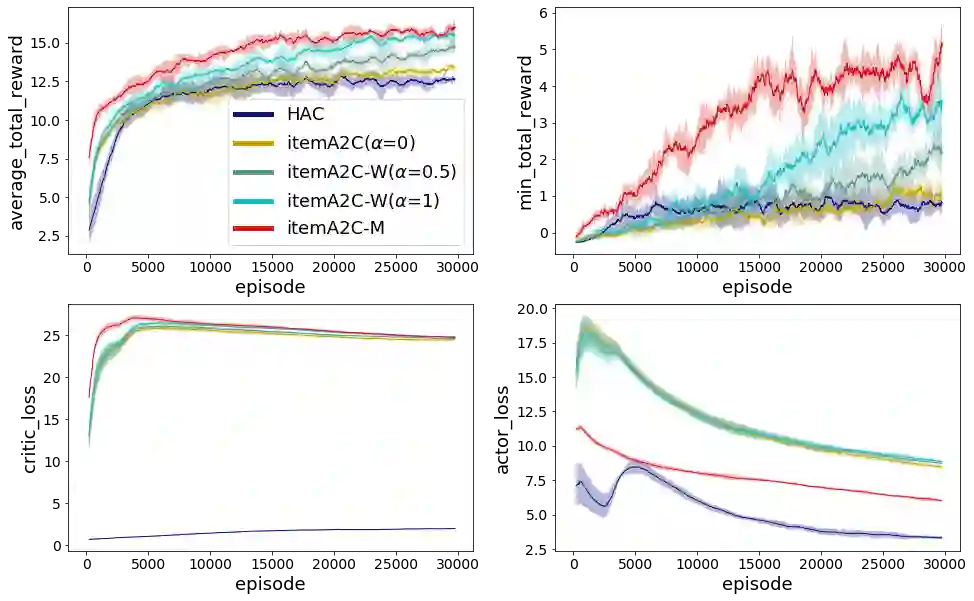
In recommender systems, reinforcement learning solutions have shown promising results in optimizing the interaction sequence between users and the system over the long-term performance. For practical reasons, the policy's actions are typically designed as recommending a list of items to handle users' frequent and continuous browsing requests more efficiently. In this list-wise recommendation scenario, the user state is updated upon every request in the corresponding MDP formulation. However, this request-level formulation is essentially inconsistent with the user's item-level behavior. In this study, we demonstrate that an item-level optimization approach can better utilize item characteristics and optimize the policy's performance even under the request-level MDP. We support this claim by comparing the performance of standard request-level methods with the proposed item-level actor-critic framework in both simulation and online experiments. Furthermore, we show that a reward-based future decomposition strategy can better express the item-wise future impact and improve the recommendation accuracy in the long term. To achieve a more thorough understanding of the decomposition strategy, we propose a model-based re-weighting framework with adversarial learning that further boost the performance and investigate its correlation with the reward-based strategy.
翻译:在推荐系统中,强化学习解决方案已在优化用户与系统交互序列的长期性能方面展现出显著成效。出于实际考量,策略的决策通常被设计为推荐项目列表,以更高效地处理用户频繁且连续的浏览请求。在这种列式推荐场景中,用户状态会在相应的MDP建模中随每次请求更新。然而,这种请求级建模本质上与用户的项目级行为存在不一致性。本研究证明,即使是在请求级MDP框架下,采用项目级优化方法仍能更好地利用项目特征并提升策略性能。我们通过对比标准请求级方法与所提出的项目级演员-评论家框架在仿真实验和在线实验中的表现,为该论断提供了实证支持。此外,研究表明基于奖励的未来分解策略能更精准地表达项目级未来影响,从而在长期内提升推荐准确性。为深入理解这种分解策略,我们进一步提出结合对抗学习的模型级重加权框架以增强性能,并探究其与基于奖励策略之间的关联机制。