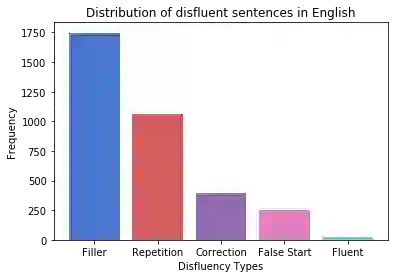
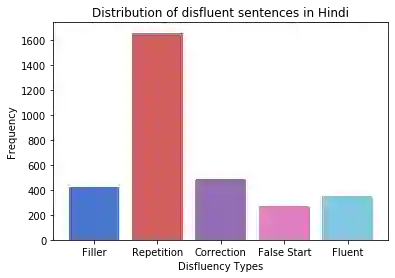
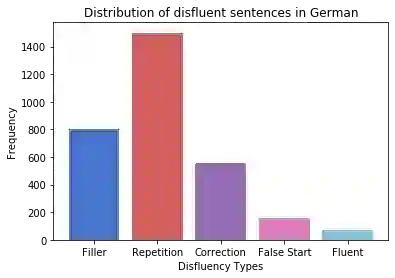
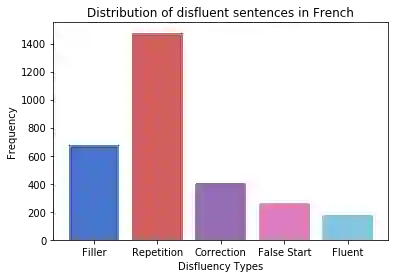
Disfluency correction (DC) is the process of removing disfluent elements like fillers, repetitions and corrections from spoken utterances to create readable and interpretable text. DC is a vital post-processing step applied to Automatic Speech Recognition (ASR) outputs, before subsequent processing by downstream language understanding tasks. Existing DC research has primarily focused on English due to the unavailability of large-scale open-source datasets. Towards the goal of multilingual disfluency correction, we present a high-quality human-annotated DC corpus covering four important Indo-European languages: English, Hindi, German and French. We provide extensive analysis of results of state-of-the-art DC models across all four languages obtaining F1 scores of 97.55 (English), 94.29 (Hindi), 95.89 (German) and 92.97 (French). To demonstrate the benefits of DC on downstream tasks, we show that DC leads to 5.65 points increase in BLEU scores on average when used in conjunction with a state-of-the-art Machine Translation (MT) system. We release code to run our experiments along with our annotated dataset here.
翻译:不流畅修正(Disfluency Correction, DC)是指从口语话语中移除填充词、重复和修正等不流畅元素,以生成可读且可解释文本的过程。DC是对自动语音识别(ASR)输出进行后续处理的关键步骤,其输出结果将输入下游语言理解任务。现有DC研究主要集中于英语,这归因于缺乏大规模开源数据集。为实现多语言不流畅修正,我们构建了涵盖四种重要印欧语系语言(英语、印地语、德语和法语)的高质量人工标注DC语料库。我们针对所有四种语言提供了当前最优DC模型的详尽分析结果,其F1分数分别为:英语97.55、印地语94.29、德语95.89、法语92.97。为证明DC对下游任务的益处,我们展示了当与当前最优机器翻译(MT)系统结合使用时,DC使BLEU分数平均提升5.65分。我们在此公开发布用于复现实验的代码及标注数据集。