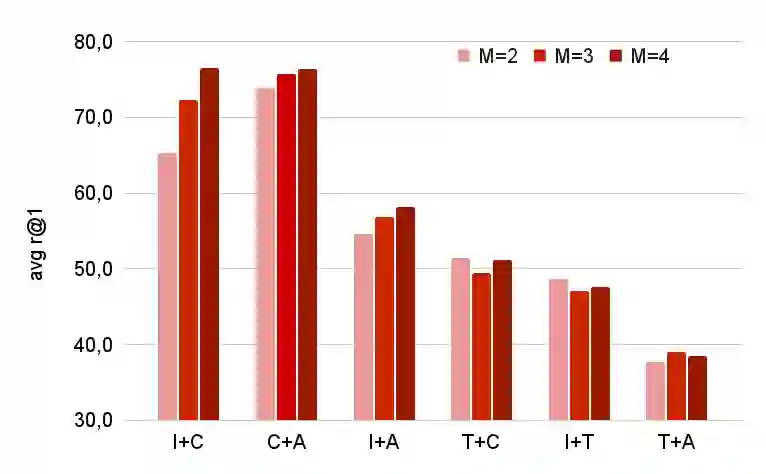
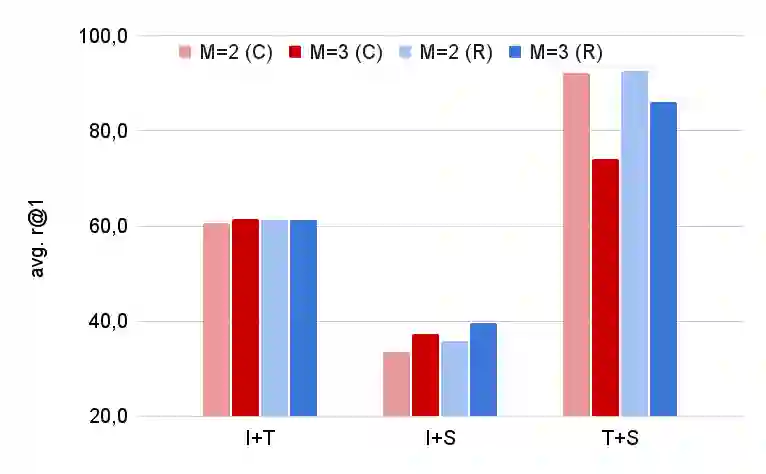
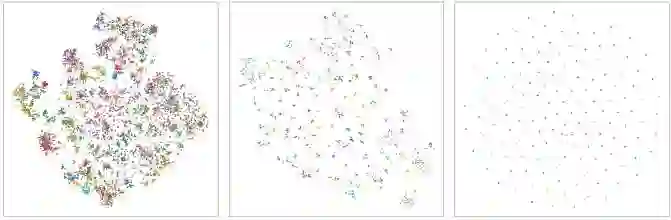
Cross-modal retrieval is the task of retrieving samples of a given modality by using queries of a different one. Due to the wide range of practical applications, the problem has been mainly focused on the vision and language case, e.g. text to image retrieval, where models like CLIP have proven effective in solving such tasks. The dominant approach to learning such coordinated representations consists of projecting them onto a common space where matching views stay close and those from non-matching pairs are pushed away from each other. Although this cross-modal coordination has been applied also to other pairwise combinations, extending it to an arbitrary number of diverse modalities is a problem that has not been fully explored in the literature. In this paper, we propose two different approaches to the problem. The first is based on an extension of the CLIP contrastive objective to an arbitrary number of input modalities, while the second departs from the contrastive formulation and tackles the coordination problem by regressing the cross-modal similarities towards a target that reflects two simple and intuitive constraints of the cross-modal retrieval task. We run experiments on two different datasets, over different combinations of input modalities and show that the approach is not only simple and effective but also allows for tackling the retrieval problem in novel ways. Besides capturing a more diverse set of pair-wise interactions, we show that we can use the learned representations to improve retrieval performance by combining the embeddings from two or more such modalities.
翻译:跨模态检索是指通过一种模态的查询来检索另一种模态样本的任务。由于广泛的实际应用需求,该问题主要集中于视觉与语言领域,例如文本到图像的检索——CLIP等模型已被证明能有效解决此类任务。当前学习协同表示的主流方法是将不同模态投影到同一个公共空间,使得匹配视域对在该空间中保持邻近,而非匹配视域对则相互排斥。尽管这种跨模态协调策略已应用于其他成对模态组合,但在文献中尚未充分探索将其扩展至任意数量多样化模态的问题。本文针对该问题提出两种不同方法:第一种基于CLIP对比学习目标的扩展,可适用于任意数量的输入模态;第二种则跳出对比学习范式,通过将跨模态相似度回归至反映跨模态检索任务两个简单直观约束的目标值来解决协调问题。我们在两个数据集上开展实验,涵盖不同输入模态组合,结果表明该方法不仅简单有效,还能以创新方式解决检索问题。除捕捉更丰富的成对交互外,我们证明可通过组合两个及以上模态的嵌入表示来提升检索性能。