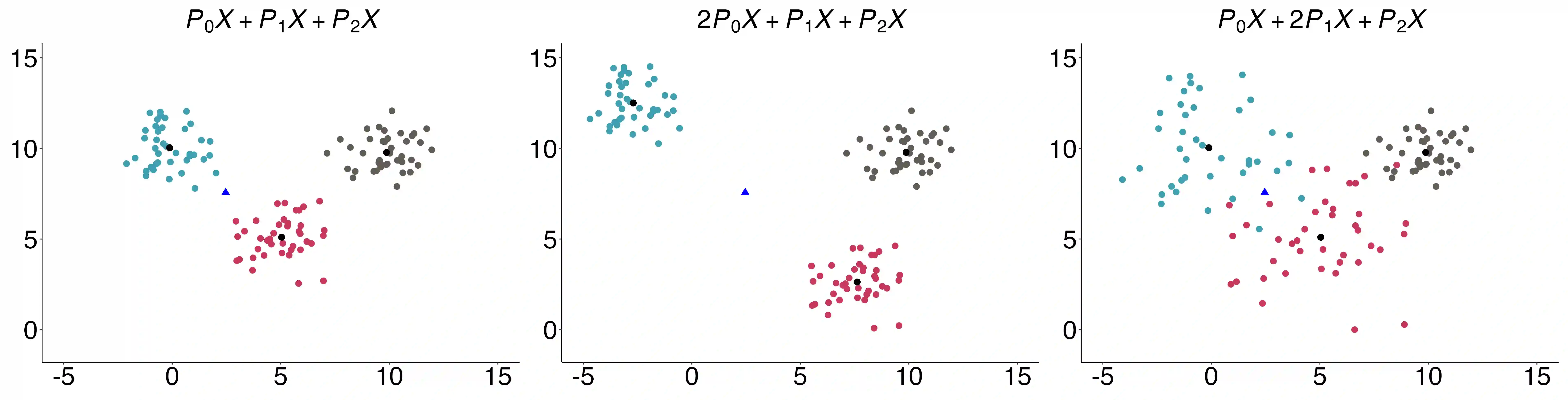
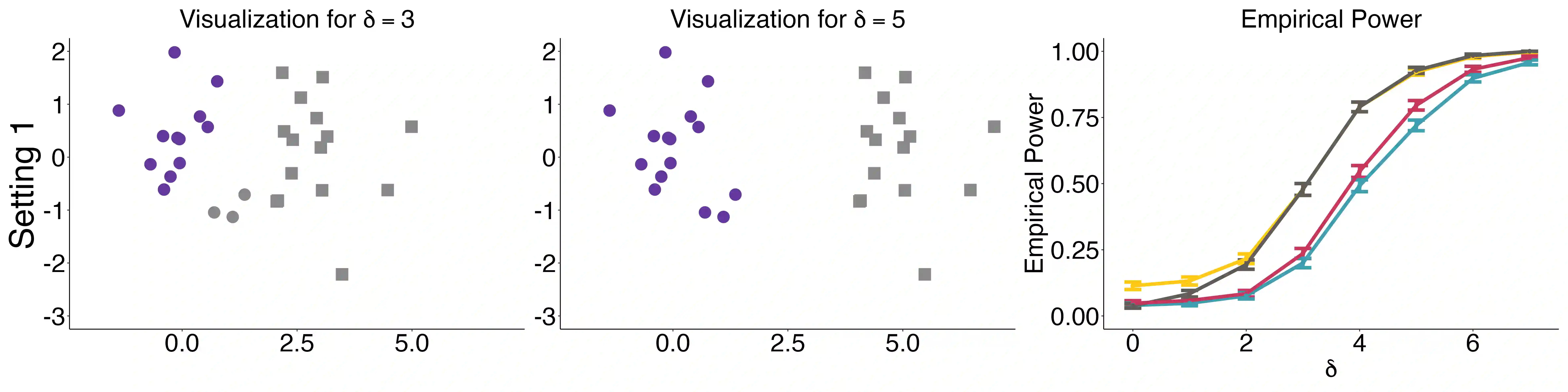
In many modern statistical problems, the limited available data must be used both to develop the hypotheses to test, and to test these hypotheses-that is, both for exploratory and confirmatory data analysis. Reusing the same dataset for both exploration and testing can lead to massive selection bias, leading to many false discoveries. Selective inference is a framework that allows for performing valid inference even when the same data is reused for exploration and testing. In this work, we are interested in the problem of selective inference for data clustering, where a clustering procedure is used to hypothesize a separation of the data points into a collection of subgroups, and we then wish to test whether these data-dependent clusters in fact represent meaningful differences within the data. Recent work by Gao et al. [2022] provides a framework for doing selective inference for this setting, where a hierarchical clustering algorithm is used for producing the cluster assignments, which was then extended to k-means clustering by Chen and Witten [2022]. Both these works rely on assuming a known covariance structure for the data, but in practice, the noise level needs to be estimated-and this is particularly challenging when the true cluster structure is unknown. In our work, we extend this work to the setting of noise with unknown variance, and provide a selective inference method for this more general setting. Empirical results show that our new method is better able to maintain high power while controlling Type I error when the true noise level is unknown.
翻译:在许多现代统计问题中,可用数据有限,必须同时用于提出待检验的假设和检验这些假设——即同时用于探索性数据分析和验证性数据分析。对同一数据集重复用于探索和检验可能导致严重的选择偏差,从而产生大量错误发现。选择性推断是一种框架,允许在相同数据被重复用于探索和检验时仍能进行有效的推断。本文关注数据聚类的选择性推断问题:首先通过聚类过程假设数据点被划分为若干子组,随后检验这些依赖于数据的聚类是否确实反映了数据中的显著差异。Gao等人[2022]的最新研究为该场景提供了选择性推断框架,采用层次聚类算法生成聚类分配,随后Chen和Witten[2022]将其扩展至k均值聚类。这两项研究均依赖于已知数据协方差结构的假设,但在实际中,噪声水平需被估计——当真实聚类结构未知时,这一过程尤为困难。本文将该工作扩展至噪声方差未知的场景,并为这一更一般化的设定提供了选择性推断方法。实证结果表明,当真实噪声水平未知时,本方法能在更好控制第一类错误的同时维持较高的检验功效。