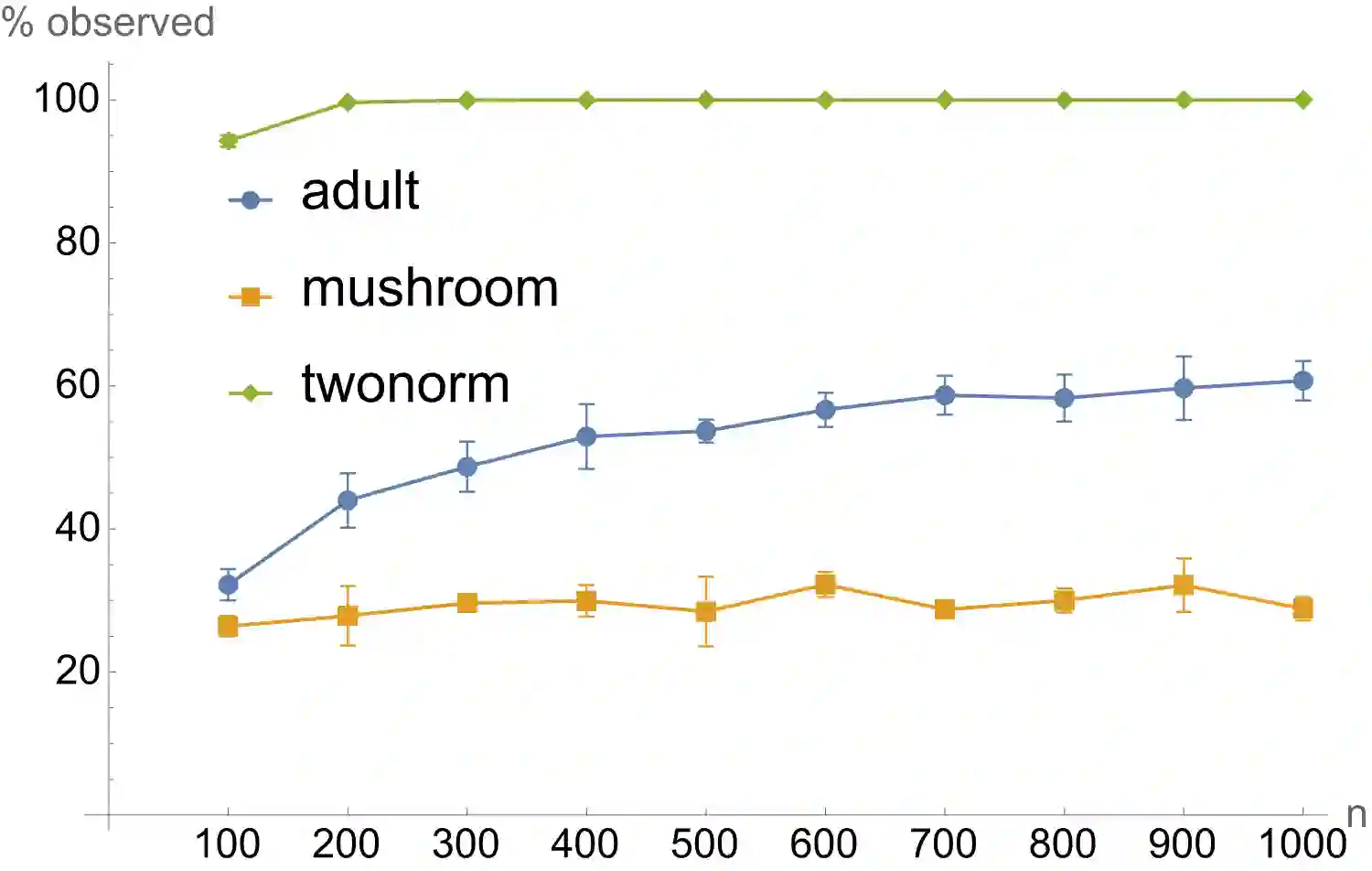
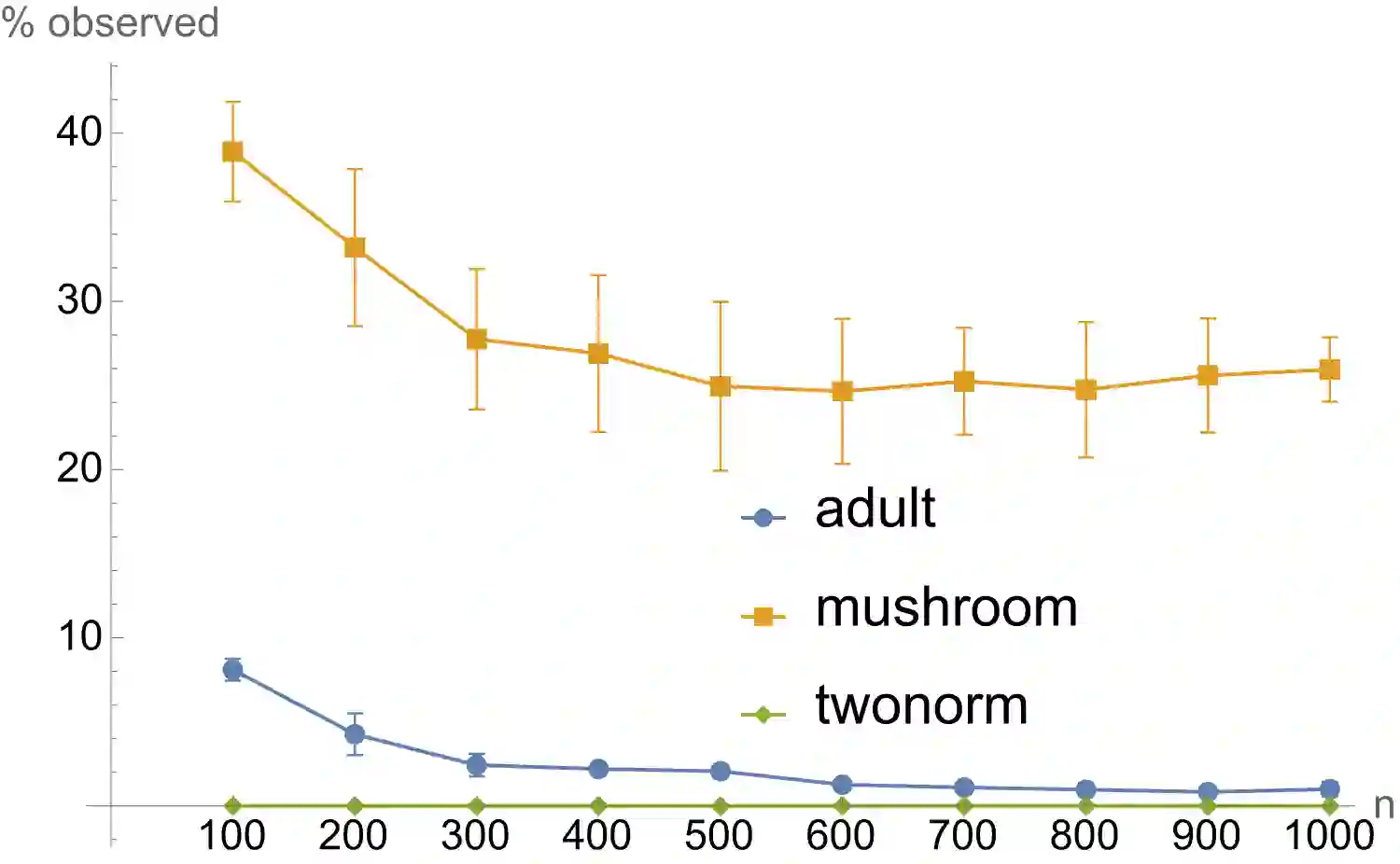
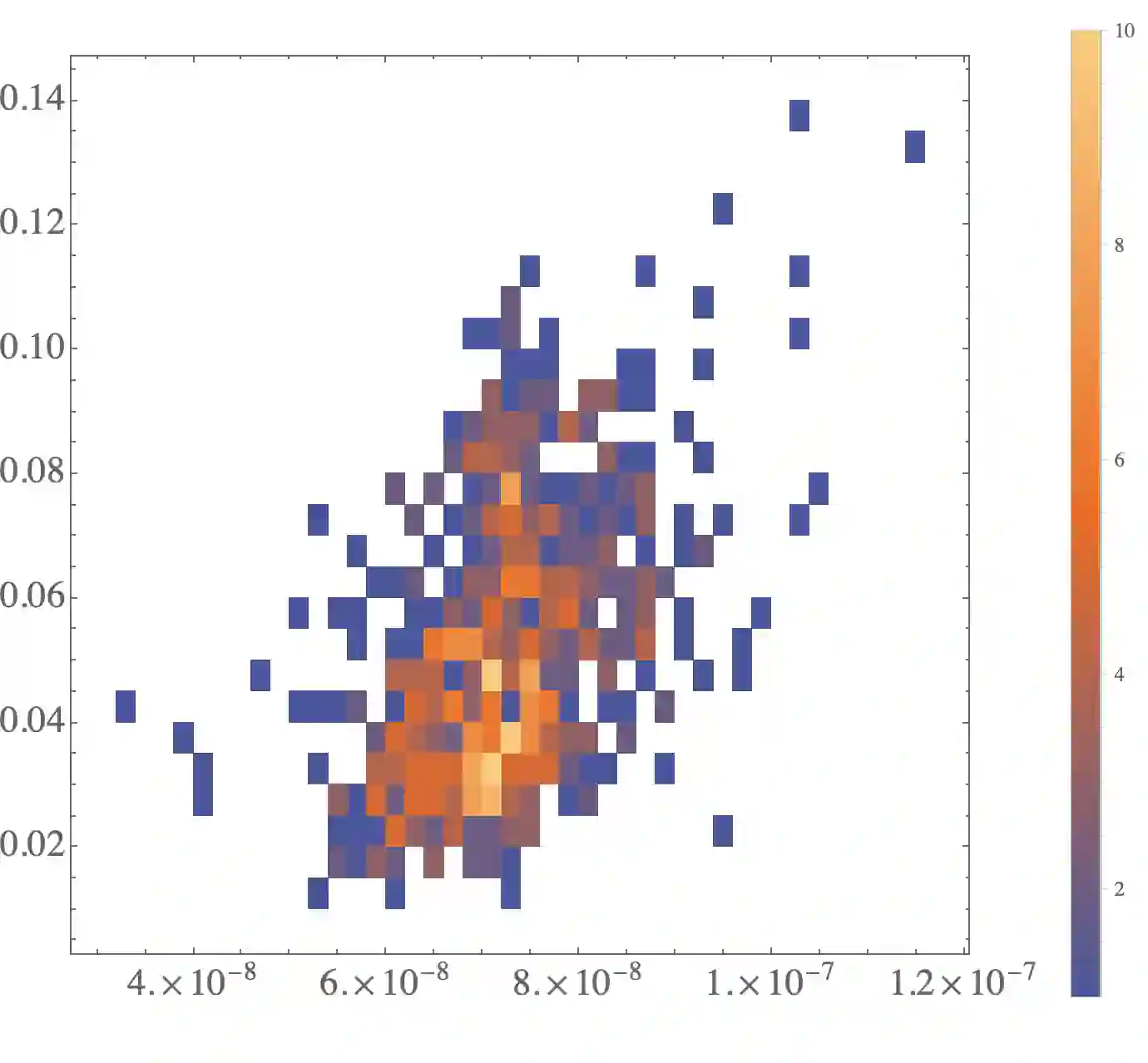
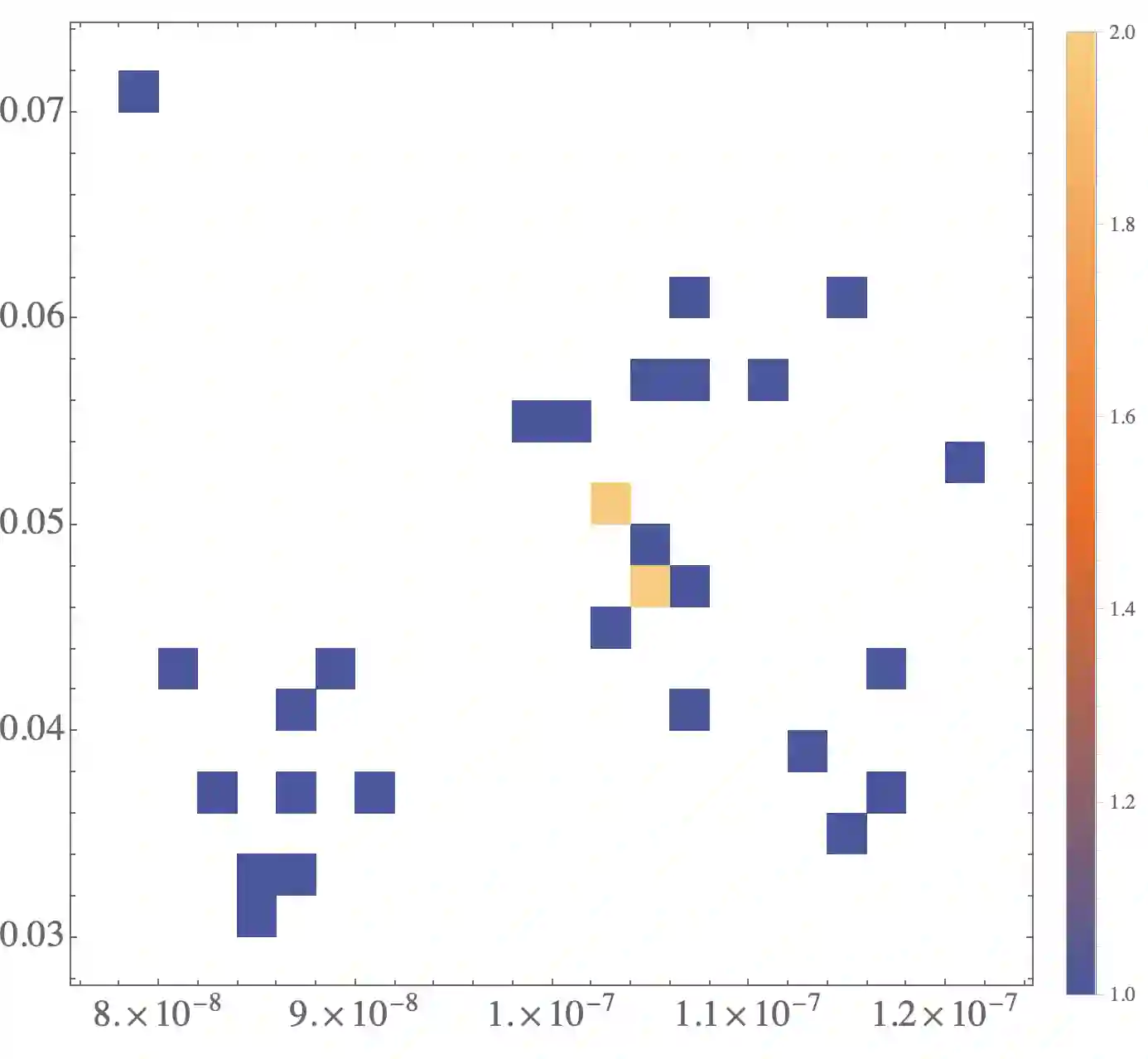
The evaluation of noisy binary classifiers on unlabeled data is treated as a streaming task: given a data sketch of the decisions by an ensemble, estimate the true prevalence of the labels as well as each classifier's accuracy on them. Two fully algebraic evaluators are constructed to do this. Both are based on the assumption that the classifiers make independent errors. The first is based on majority voting. The second, the main contribution of the paper, is guaranteed to be correct. But how do we know the classifiers are independent on any given test? This principal/agent monitoring paradox is ameliorated by exploiting the failures of the independent evaluator to return sensible estimates. A search for nearly error independent trios is empirically carried out on the \texttt{adult}, \texttt{mushroom}, and \texttt{two-norm} datasets by using the algebraic failure modes to reject evaluation ensembles as too correlated. The searches are refined by constructing a surface in evaluation space that contains the true value point. The algebra of arbitrarily correlated classifiers permits the selection of a polynomial subset free of any correlation variables. Candidate evaluation ensembles are rejected if their data sketches produce independent estimates too far from the constructed surface. The results produced by the surviving ensembles can sometimes be as good as 1\%. But handling even small amounts of correlation remains a challenge. A Taylor expansion of the estimates produced when independence is assumed but the classifiers are, in fact, slightly correlated helps clarify how the independent evaluator has algebraic `blind spots'.
翻译:针对未标注数据上噪声二分类器的评估被视作一种流式任务:基于集成分类器决策的数据摘要,估计标签的真实分布以及每个分类器在其上的准确率。为此,构建了两种完全代数化的评估器。两者均基于分类器误差独立的假设。第一种基于多数投票。第二种(本文的主要贡献)保证结果正确。但如何验证分类器在任意测试集上独立?这一主事/代理监控悖论通过利用独立评估器未能返回合理估计的失败模式得到缓解。通过在 \texttt{adult}、\texttt{mushroom} 和 \texttt{two-norm} 数据集上系统搜索近似误差独立的三元组,利用代数失效模式剔除相关性过高的评估集成。进一步在评估空间中构建包含真实值点的曲面以优化搜索。任意相关分类器的代数方法允许选择不含任何相关变量的多项式子集。若候选评估集成产生的独立估计偏离该曲面过远,则予以剔除。存活集成产生的结果有时可接近 1% 的误差。但处理即使是少量相关性仍构成挑战。对假设独立但分类器实际轻微相关时产生的估计进行泰勒展开,有助于阐明独立评估器在代数上的“盲区”。