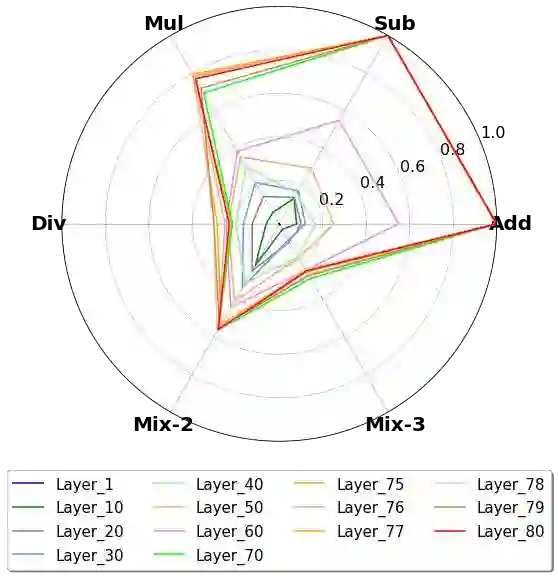
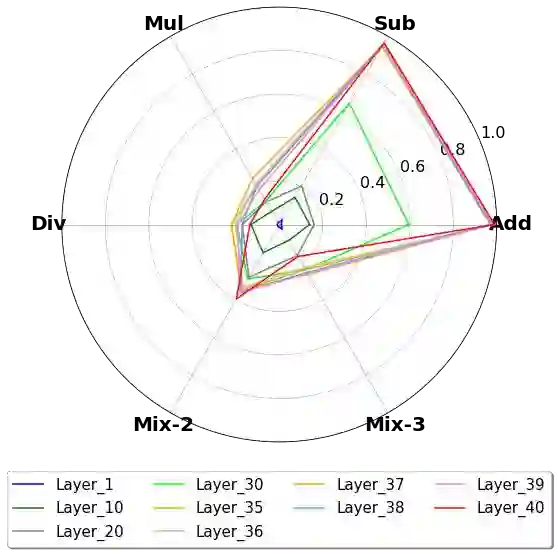
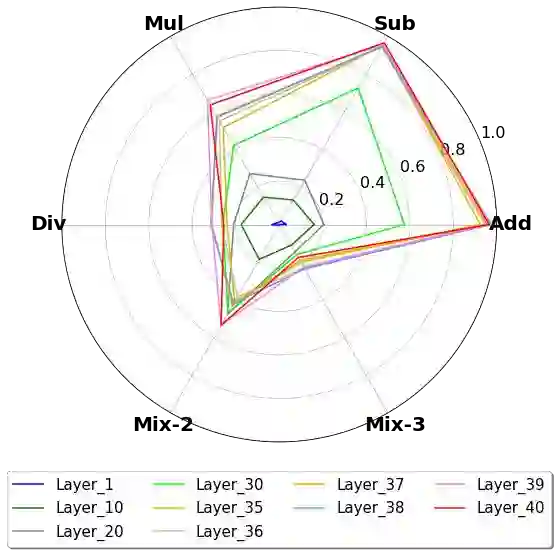
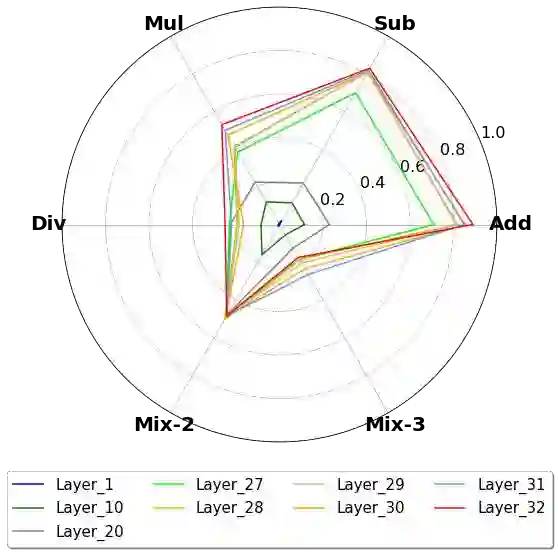
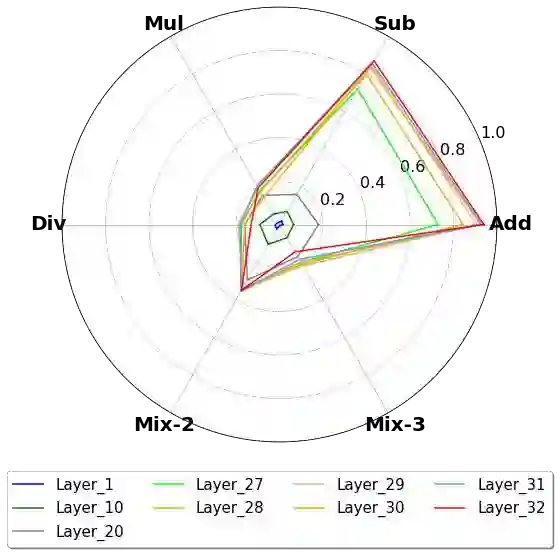
This paper presents an in-depth analysis of Large Language Models (LLMs), focusing on LLaMA, a prominent open-source foundational model in natural language processing. Instead of assessing LLaMA through its generative output, we design multiple-choice tasks to probe its intrinsic understanding in high-order tasks such as reasoning and computation. We examine the model horizontally, comparing different sizes, and vertically, assessing different layers. We unveil several key and uncommon findings based on the designed probing tasks: (1) Horizontally, enlarging model sizes almost could not automatically impart additional knowledge or computational prowess. Instead, it can enhance reasoning abilities, especially in math problem solving, and helps reduce hallucinations, but only beyond certain size thresholds; (2) In vertical analysis, the lower layers of LLaMA lack substantial arithmetic and factual knowledge, showcasing logical thinking, multilingual and recognitive abilities, with top layers housing most computational power and real-world knowledge.
翻译:本文对大语言模型(LLMs)进行了深入分析,重点关注LLaMA——自然语言处理领域一个重要的开源基础模型。不同于通过生成输出评估LLaMA,我们设计多项选择任务来探测其在推理和计算等高级任务中的内在理解能力。我们横向比较不同模型规模,纵向评估不同层级,基于设计的探测任务揭示了若干关键且非寻常的发现:(1)横向来看,扩大模型规模几乎无法自动提升知识储备或计算能力,但能增强推理能力(尤其在数学问题求解中),并有助于减少幻觉,但仅当规模超过特定阈值时; (2)纵向分析表明,LLaMA的低层缺乏足够的算术和事实知识,但展现出逻辑思维、多语言和认知能力,而顶层则集中了大部分计算能力和现实世界知识。