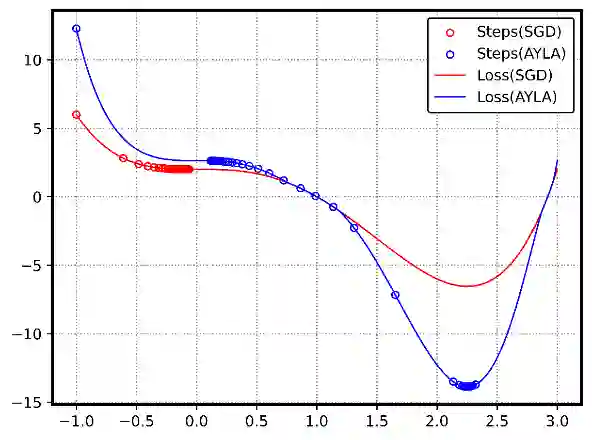
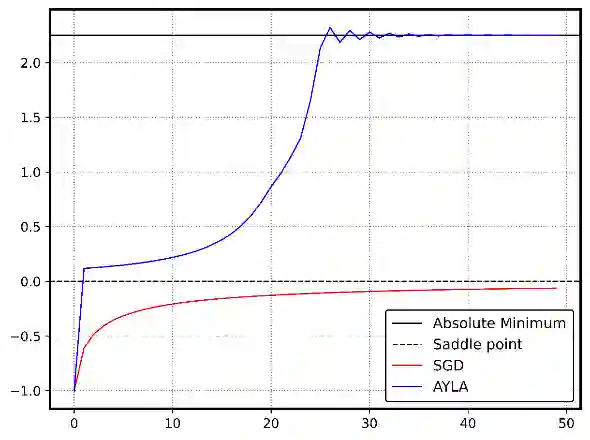
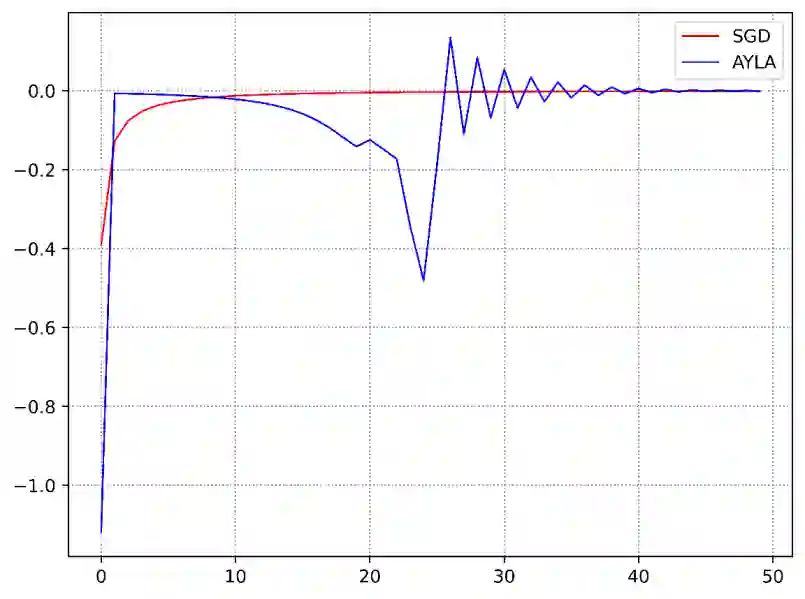
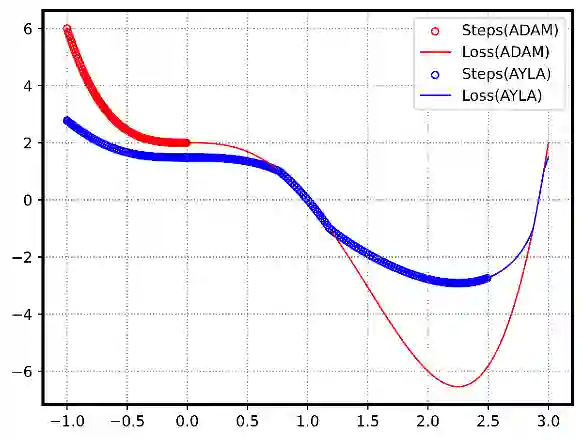
Stochastic Gradient Descent (SGD) and its variants, such as ADAM, are foundational to deep learning optimization, adjusting model parameters using fixed or adaptive learning rates based on loss function gradients. However, these methods often face challenges in balancing adaptability and efficiency in non-convex, high-dimensional settings. This paper introduces AYLA, a novel optimization technique that enhances training dynamics through loss function transformations. By applying a tunable power-law transformation, AYLA preserves critical points while scaling loss values to amplify gradient sensitivity, accelerating convergence. We further propose a dynamic (effective) learning rate that adapts to the transformed loss, improving optimization efficiency. Empirical tests on finding minimum of a synthetic non-convex polynomial, a non-convex curve-fitting dataset, and digit classification (MNIST) demonstrate that AYLA surpasses SGD and ADAM in convergence speed and stability. This approach redefines the loss landscape for better optimization outcomes, offering a promising advancement for deep neural networks and can be applied to any optimization method and potentially improve the performance of it.
翻译:随机梯度下降及其变体(如ADAM)是深度学习优化的基础方法,它们基于损失函数梯度,采用固定或自适应学习率调整模型参数。然而,这些方法在非凸高维场景中常面临适应性与效率难以平衡的挑战。本文提出一种新型优化技术AYLA,通过损失函数变换增强训练动态。该方法采用可调幂律变换,在保持临界点不变的同时缩放损失值以放大梯度敏感性,从而加速收敛。我们进一步提出动态有效学习率机制,使其适应变换后的损失函数以提升优化效率。在合成非凸多项式最小值求解、非凸曲线拟合数据集及手写数字分类任务上的实验表明,AYLA在收敛速度与稳定性方面均优于SGD与ADAM。该方法通过重塑损失景观获得更优的优化结果,为深度神经网络提供了具有前景的改进方案,且可适配于任意优化方法并潜在提升其性能。