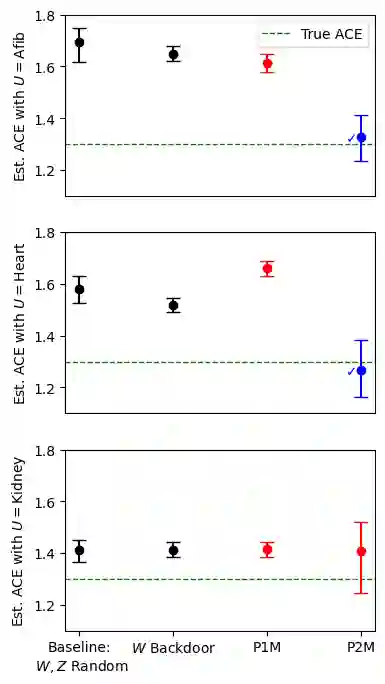
Recent text-based causal methods attempt to mitigate confounding bias by including unstructured text data as proxies of confounding variables that are partially or imperfectly measured. These approaches assume analysts have supervised labels of the confounders given text for a subset of instances, a constraint that is not always feasible due to data privacy or cost. Here, we address settings in which an important confounding variable is completely unobserved. We propose a new causal inference method that splits pre-treatment text data, infers two proxies from two zero-shot models on the separate splits, and applies these proxies in the proximal g-formula. We prove that our text-based proxy method satisfies identification conditions required by the proximal g-formula while other seemingly reasonable proposals do not. We evaluate our method in synthetic and semi-synthetic settings and find that it produces estimates with low bias. This combination of proximal causal inference and zero-shot classifiers is novel (to our knowledge) and expands the set of text-specific causal methods available to practitioners.
翻译:最新的基于文本的因果方法试图通过将非结构化文本数据作为部分或不完美测量的混杂变量的替代指标来减轻混杂偏差。这些方法假设研究者拥有给定文本中混杂变量在部分实例上的监督标签,但由于数据隐私或成本限制,这一约束并不总是可行。本文研究了重要混杂变量完全无法观测的情况。我们提出了一种新的因果推断方法:将预处理文本数据分割,分别利用两个零样本模型从分割数据中推断两个代理变量,并将这些代理变量应用于近端g公式。我们证明,本文提出的基于文本的代理方法满足近端g公式所需的识别条件,而其他看似合理的方案则无法满足。通过合成与半合成数据集评估,发现该方法能产生低偏差估计。这种将近端因果推断与零样本分类器相结合的思路(据我们所知)是新颖的,拓展了研究者可用的文本特定因果方法集合。