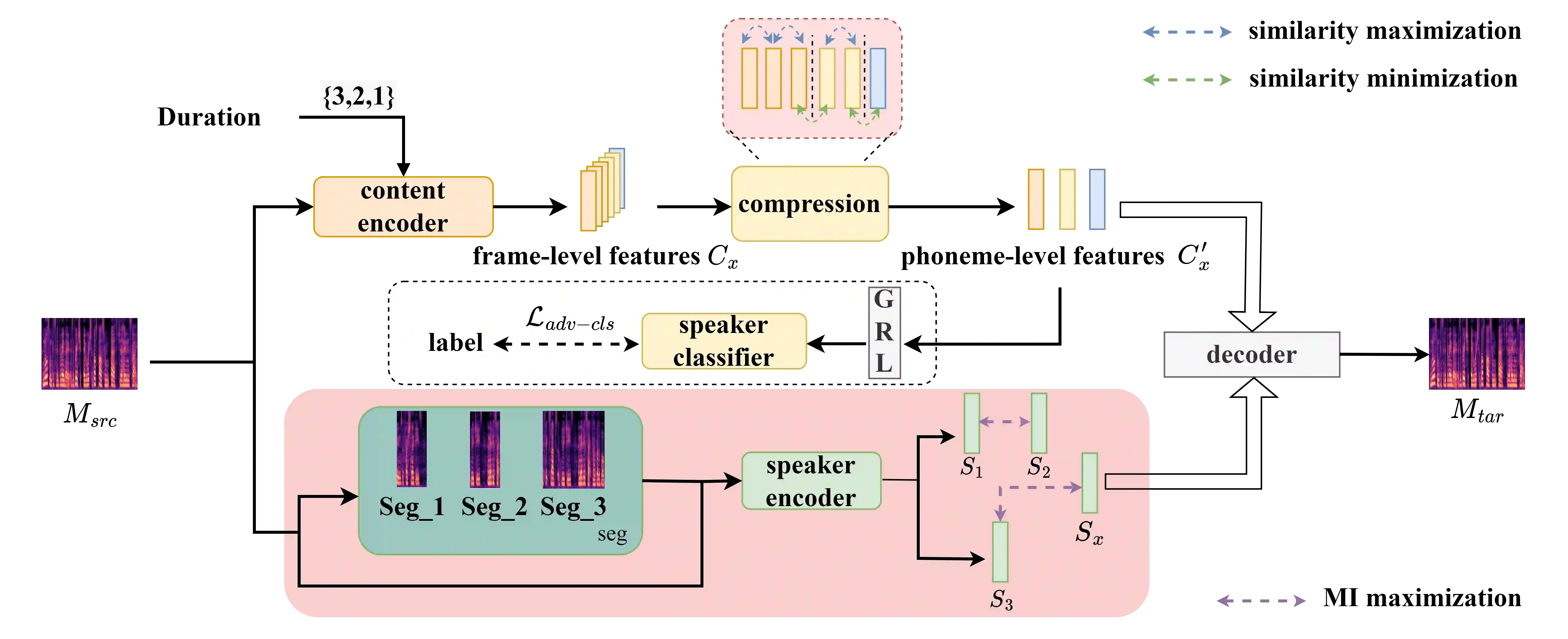
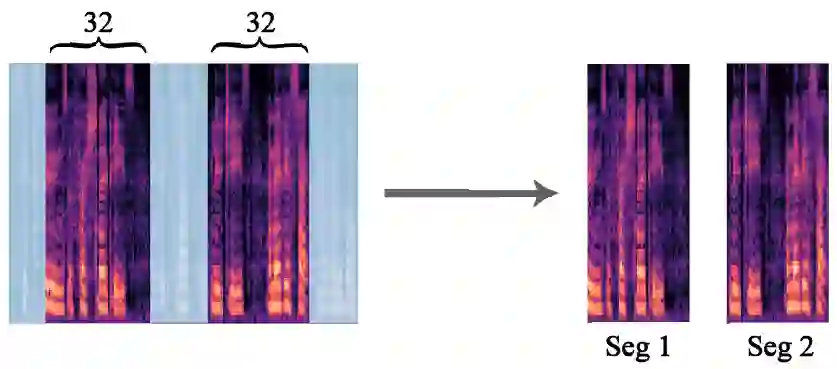
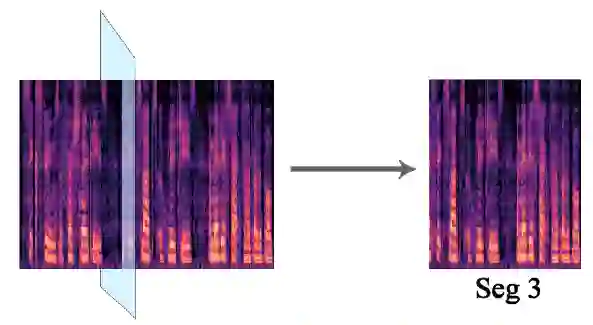
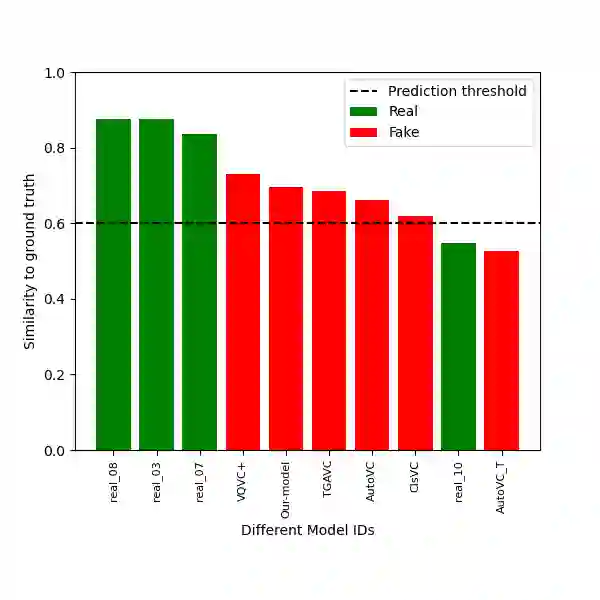
Voice conversion refers to transferring speaker identity with well-preserved content. Better disentanglement of speech representations leads to better voice conversion. Recent studies have found that phonetic information from input audio has the potential ability to well represent content. Besides, the speaker-style modeling with pre-trained models making the process more complex. To tackle these issues, we introduce a new method named "CTVC" which utilizes disentangled speech representations with contrastive learning and time-invariant retrieval. Specifically, a similarity-based compression module is used to facilitate a more intimate connection between the frame-level hidden features and linguistic information at phoneme-level. Additionally, a time-invariant retrieval is proposed for timbre extraction based on multiple segmentations and mutual information. Experimental results demonstrate that "CTVC" outperforms previous studies and improves the sound quality and similarity of converted results.
翻译:语音转换是指保留内容的同时迁移说话人身份。更好的语音表征解耦能带来更优的语音转换效果。近期研究发现,输入音频中的语音信息具有良好表征内容的潜在能力。此外,基于预训练模型的说话人风格建模会使处理过程更为复杂。为解决这些问题,我们提出一种名为"CTVC"的新方法,该方法利用对比学习和时不变检索实现解耦语音表征。具体而言,通过基于相似度的压缩模块促进帧级隐藏特征与音素级语言信息之间的更紧密关联。同时提出基于多重分割与互信息的时不变检索方法进行音色提取。实验结果表明,"CTVC"方法优于现有研究,显著提升了转换结果的音质与相似度。