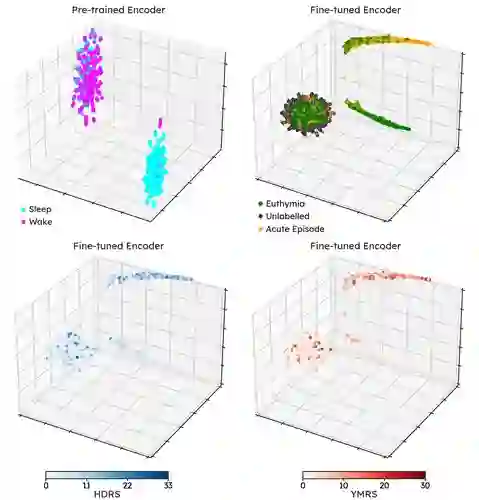
Personal sensing, leveraging data passively and near-continuously collected with wearables from patients in their ecological environment, is a promising paradigm to monitor mood disorders (MDs), a major determinant of worldwide disease burden. However, collecting and annotating wearable data is very resource-intensive. Studies of this kind can thus typically afford to recruit only a couple dozens of patients. This constitutes one of the major obstacles to applying modern supervised machine learning techniques to MDs detection. In this paper, we overcome this data bottleneck and advance the detection of MDs acute episode vs stable state from wearables data on the back of recent advances in self-supervised learning (SSL). This leverages unlabelled data to learn representations during pre-training, subsequently exploited for a supervised task. First, we collected open-access datasets recording with an Empatica E4 spanning different, unrelated to MD monitoring, personal sensing tasks -- from emotion recognition in Super Mario players to stress detection in undergraduates -- and devised a pre-processing pipeline performing on-/off-body detection, sleep-wake detection, segmentation, and (optionally) feature extraction. With 161 E4-recorded subjects, we introduce E4SelfLearning, the largest to date open access collection, and its pre-processing pipeline. Second, we show that SSL confidently outperforms fully-supervised pipelines using either our novel E4-tailored Transformer architecture (E4mer) or classical baseline XGBoost: 81.23% against 75.35% (E4mer) and 72.02% (XGBoost) correctly classified recording segments from 64 (half acute, half stable) patients. Lastly, we illustrate that SSL performance is strongly associated with the specific surrogate task employed for pre-training as well as with unlabelled data availability.
翻译:个人传感技术通过可穿戴设备在自然环境中被动且近乎连续地收集患者数据,为监测情感障碍(MDs)这一全球疾病负担的主要决定因素提供了有前景的研究范式。然而,可穿戴数据的收集与标注资源消耗极大,此类研究通常只能招募数十名患者,这成为现代监督式机器学习方法应用于情感障碍检测的主要障碍之一。本文借助近期自监督学习(SSL)的进展,从可穿戴数据中突破数据瓶颈,推进了情感障碍急性发作期与稳定期的检测。自监督学习利用无标注数据在预训练阶段学习表征,随后用于监督式任务。首先,我们收集了采用Empatica E4设备记录的开放获取数据集,这些数据涵盖与情感障碍监测无关的多种个人传感任务(从《超级马里奥》玩家的情绪识别到大学生的压力检测),并设计了包含佩戴检测、睡眠-觉醒检测、分段及(可选)特征提取的预处理流程。基于161名受试者的E4记录数据,我们推出了迄今最大的开放获取数据集E4SelfLearning及其预处理流程。其次,研究表明自监督学习显著优于全监督式方法:采用我们新提出的E4专用Transformer架构(E4mer)或经典基线模型XGBoost时,自监督学习对64名患者(半数急性发作期、半数稳定期)记录片段的正确分类率达81.23%,而全监督式E4mer为75.35%、XGBoost为72.02%。最后,我们阐明自监督学习性能与预训练采用的特定代理任务及无标注数据的可用性密切相关。