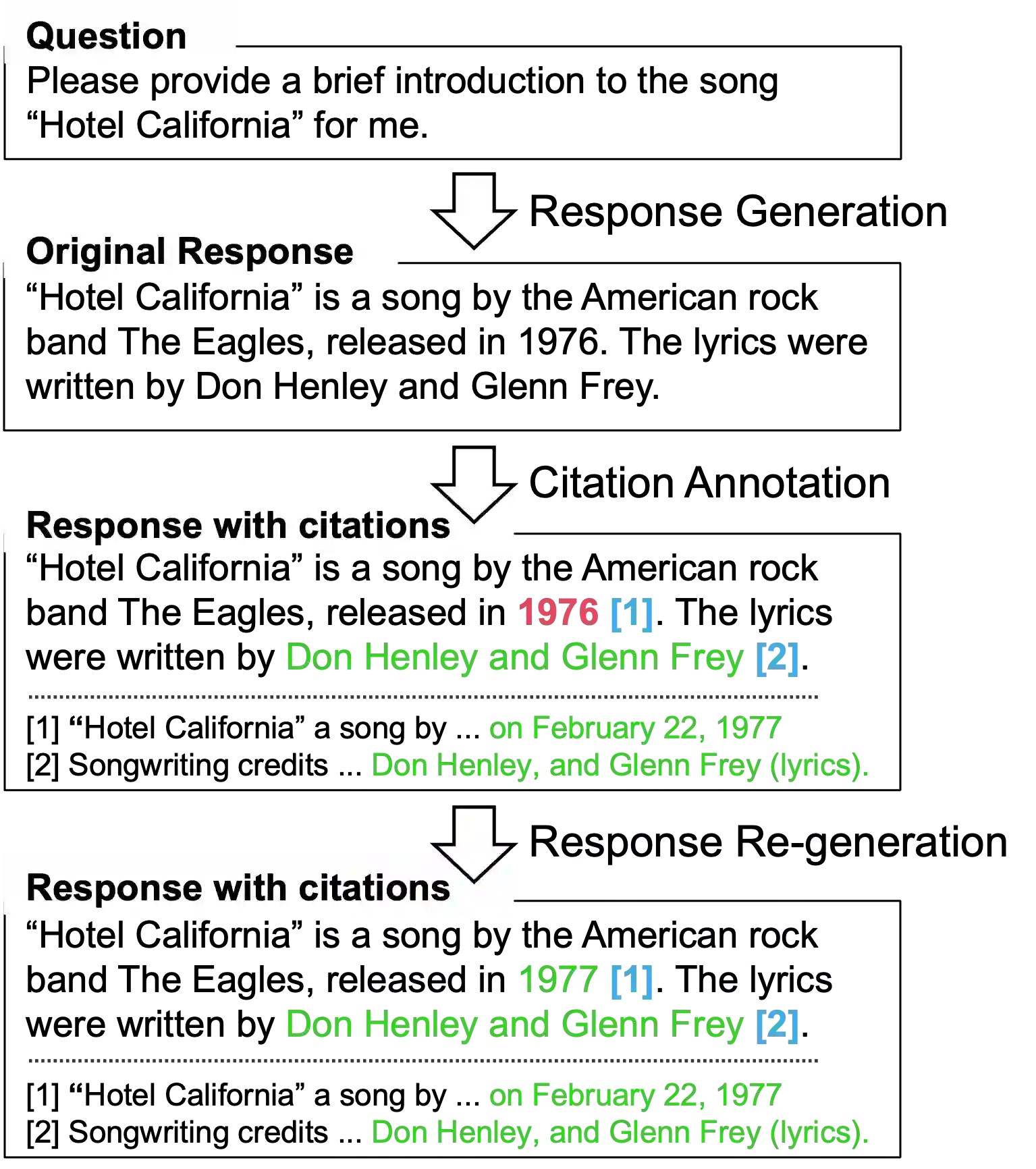
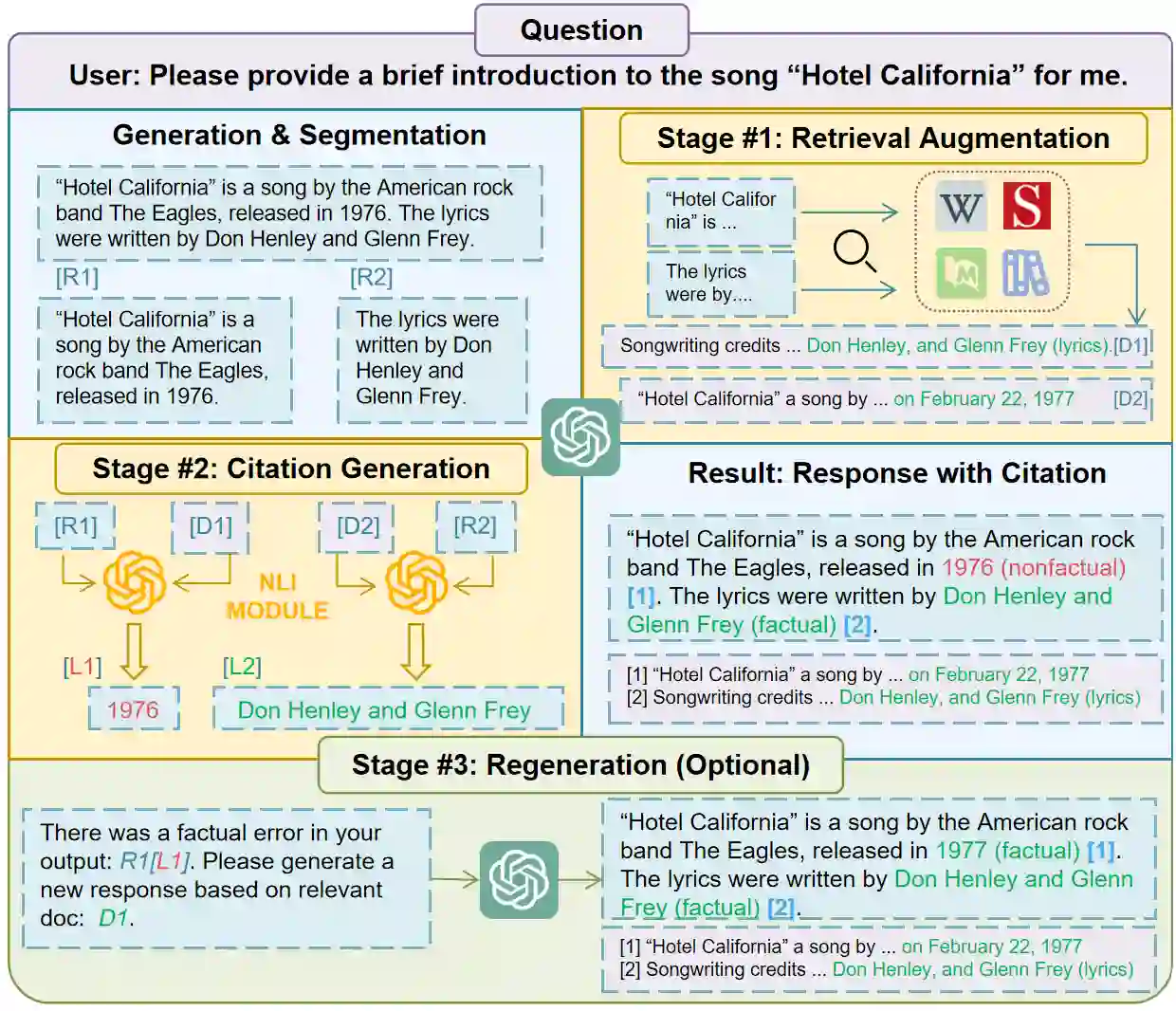
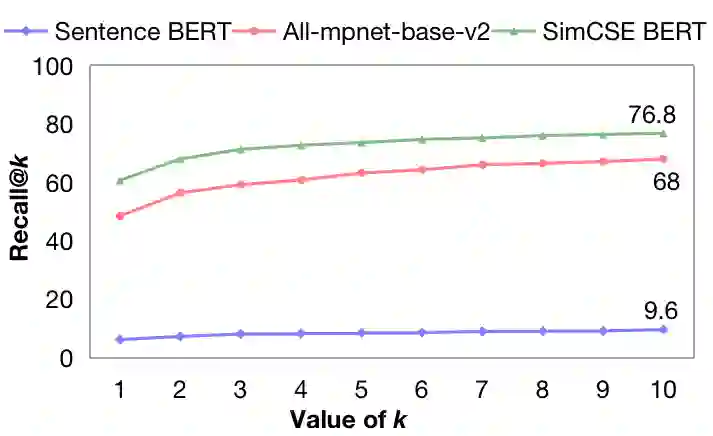
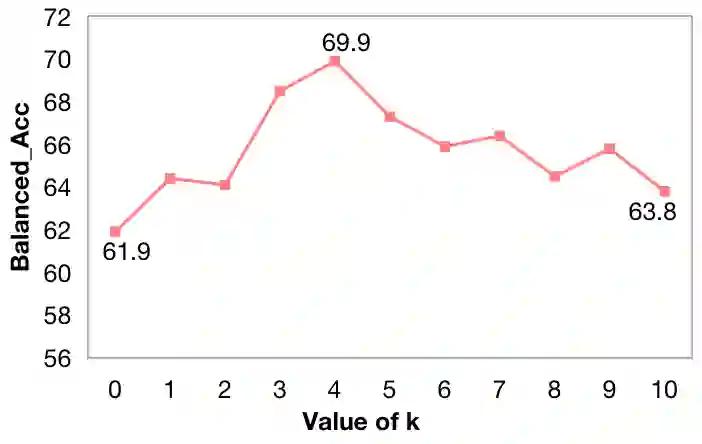
Large language models (LLMs) exhibit powerful general intelligence across diverse scenarios, including their integration into chatbots. However, a vital challenge of LLM-based chatbots is that they may produce hallucinated content in responses, which significantly limits their applicability. Various efforts have been made to alleviate hallucination, such as retrieval augmented generation and reinforcement learning with human feedback, but most of them require additional training and data annotation. In this paper, we propose a novel post-hoc Citation-Enhanced Generation (CEG) approach combined with retrieval argumentation. Unlike previous studies that focus on preventing hallucinations during generation, our method addresses this issue in a post-hoc way. It incorporates a retrieval module to search for supporting documents relevant to the generated content, and employs a natural language inference-based citation generation module. Once the statements in the generated content lack of reference, our model can regenerate responses until all statements are supported by citations. Note that our method is a training-free plug-and-play plugin that is capable of various LLMs. Experiments on various hallucination-related datasets show our framework outperforms state-of-the-art methods in both hallucination detection and response regeneration on three benchmarks. Our codes and dataset will be publicly available.
翻译:大型语言模型(LLMs)在各类场景中展现出强大的通用智能,包括其在聊天机器人中的集成应用。然而,基于LLM的聊天机器人面临一个关键挑战——其生成的回复可能包含虚构内容,这严重限制了其适用性。现有研究已尝试多种方法缓解虚构问题,例如检索增强生成和基于人类反馈的强化学习,但多数方法需要额外训练与数据标注。本文提出一种新颖的事后引用增强生成(CEG)方法,并结合检索增强机制。不同于以往聚焦于生成阶段预防虚构的研究,本方法以事后方式处理该问题:通过检索模块搜索与生成内容相关的支撑文档,并采用基于自然语言推理的引用生成模块。当生成内容中的陈述缺乏引用时,模型可重新生成回复直至所有陈述均获得引用支撑。值得注意的是,本方法是一种无需训练、即插即用的插件,可适配多种LLM。在多个与虚构相关的数据集上的实验表明,本框架在三个基准测试的虚构检测与回复重构任务中均优于现有最先进方法。我们的代码与数据集将公开提供。