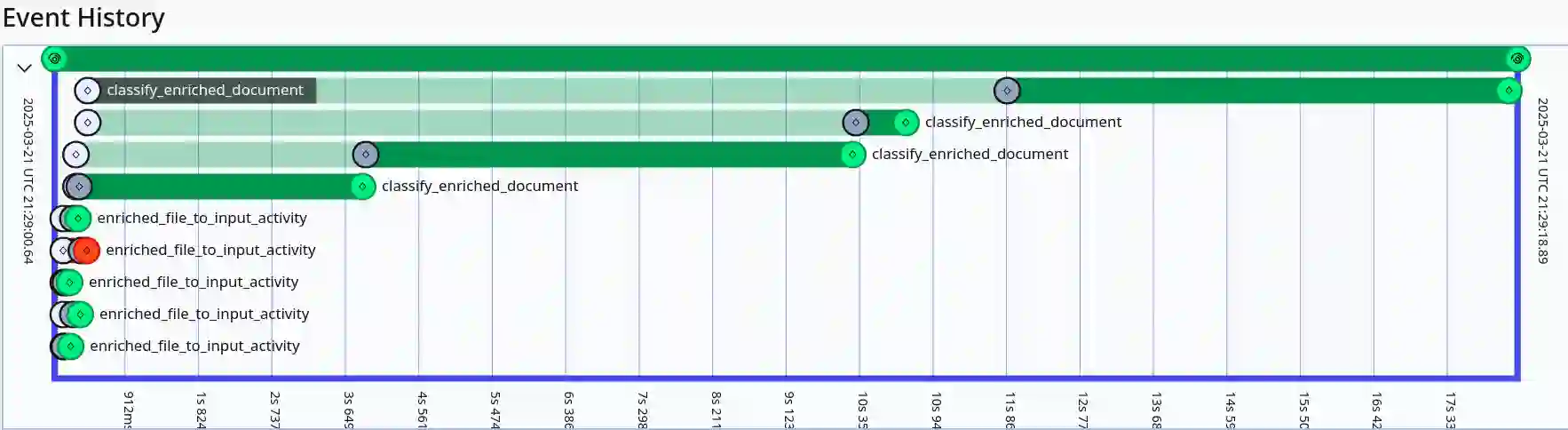
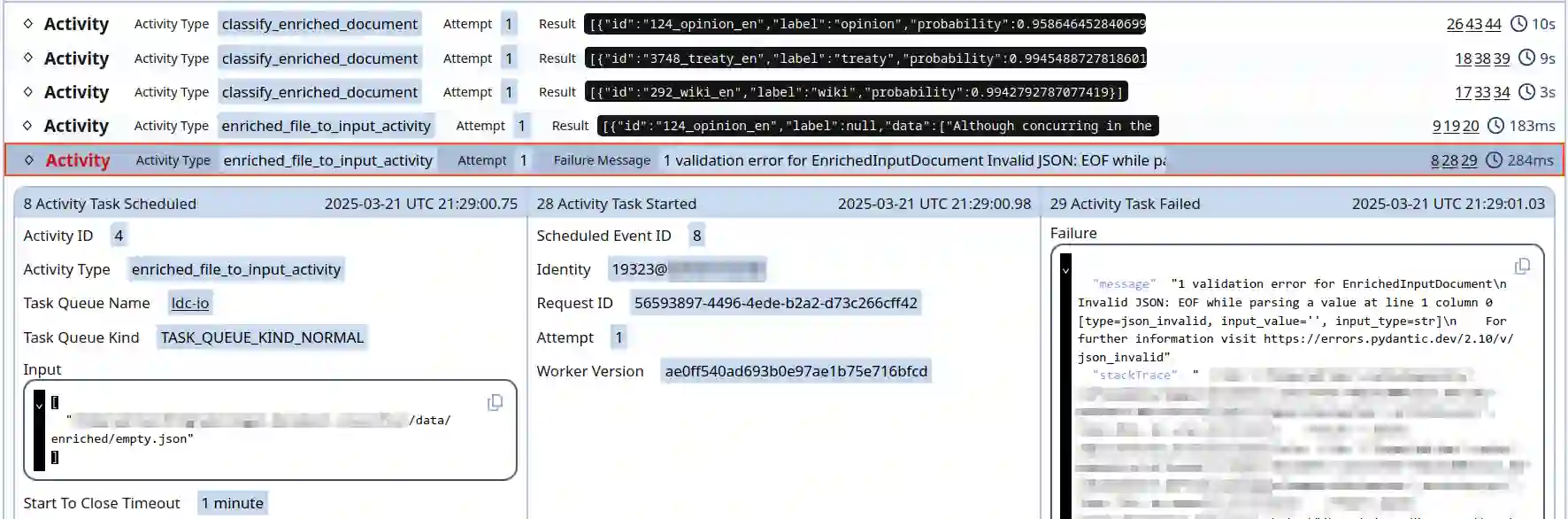
Classifying legal documents is a challenge, besides their specialized vocabulary, sometimes they can be very long. This means that feeding full documents to a Transformers-based models for classification might be impossible, expensive or slow. Thus, we present a legal document classifier based on DeBERTa V3 and a LSTM, that uses as input a collection of 48 randomly-selected short chunks (max 128 tokens). Besides, we present its deployment pipeline using Temporal, a durable execution solution, which allow us to have a reliable and robust processing workflow. The best model had a weighted F-score of 0.898, while the pipeline running on CPU had a processing median time of 498 seconds per 100 files.
翻译:法律文档分类是一项挑战,除了其专业词汇外,有时文档篇幅可能非常冗长。这意味着将完整文档输入基于Transformer的模型进行分类可能无法实现、成本高昂或速度缓慢。因此,我们提出了一种基于DeBERTa V3和LSTM的法律文档分类器,其输入为48个随机选取的短片段(最大128个词元)。此外,我们介绍了使用Temporal(一种持久化执行解决方案)的部署流程,该方案使我们能够建立可靠且稳健的处理工作流。最佳模型的加权F分数达到0.898,而在CPU上运行的流程每处理100个文件的中位时间为498秒。