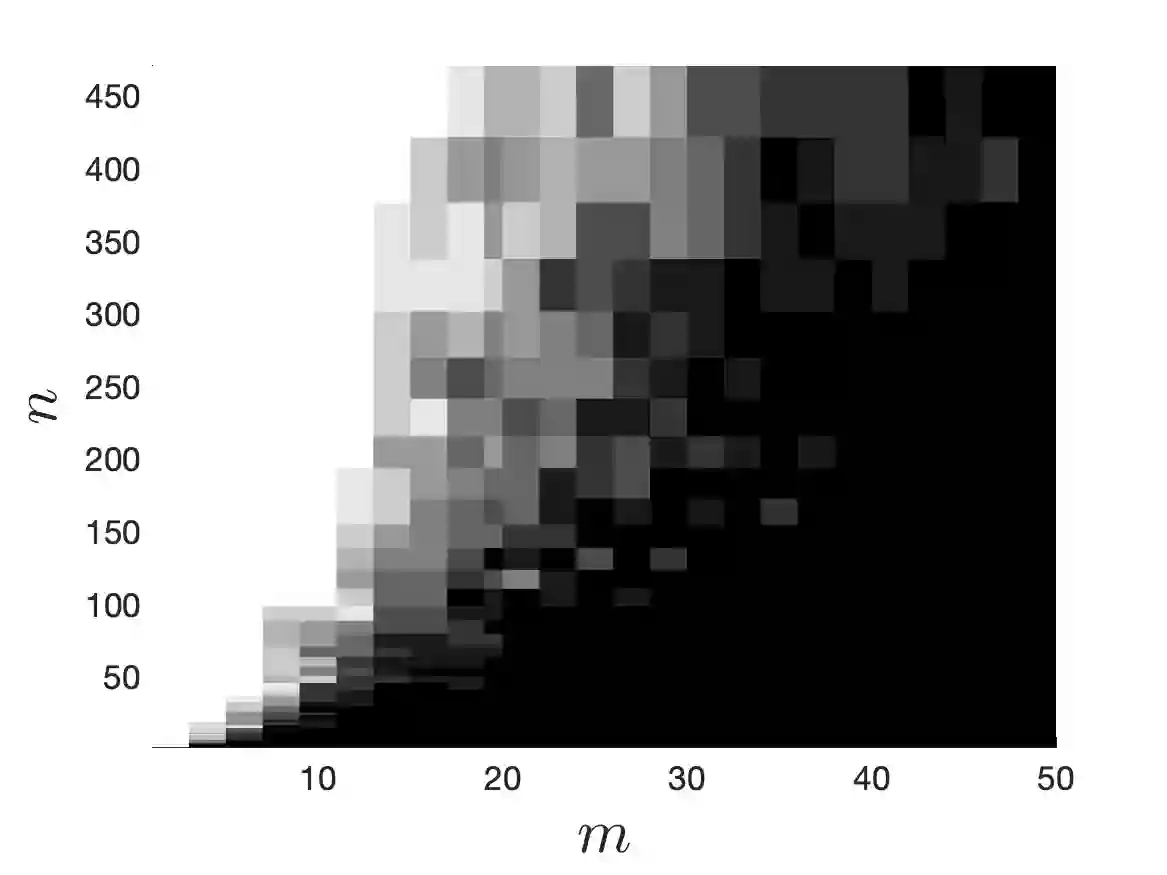
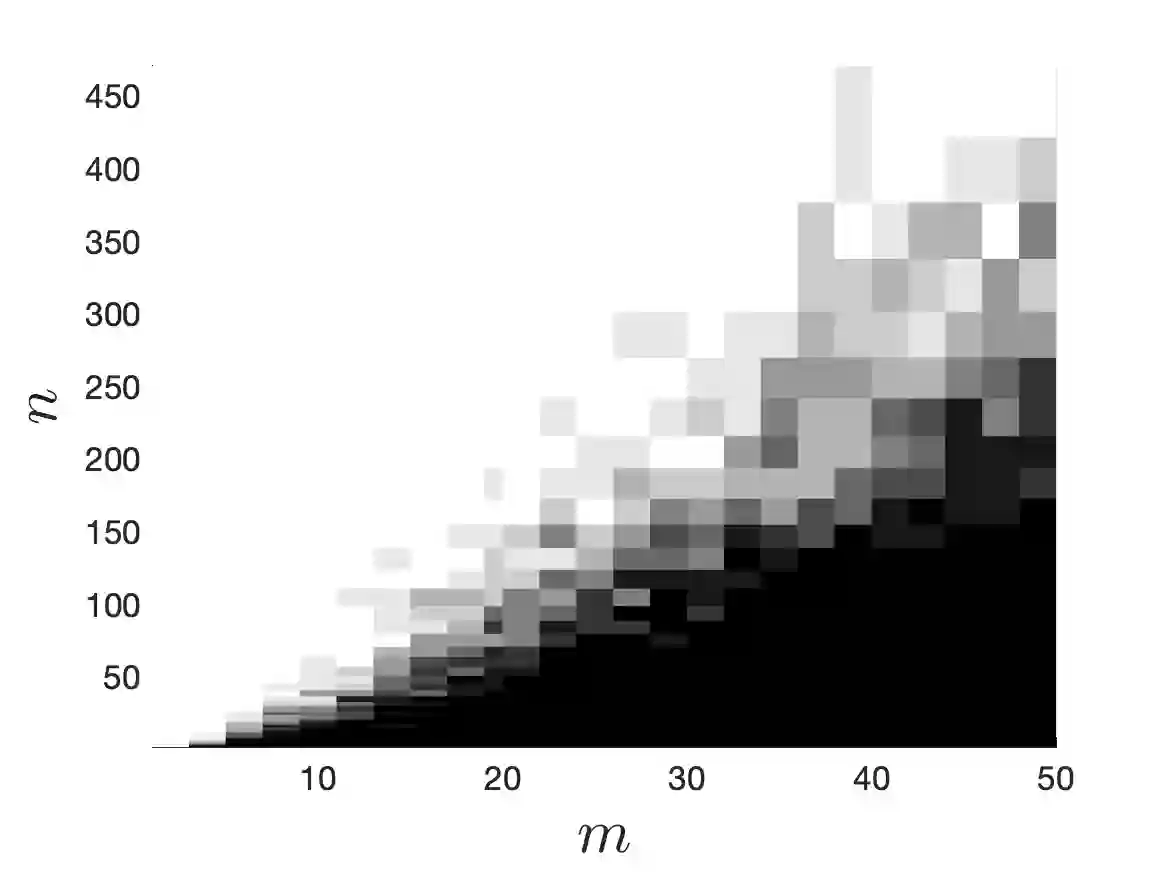
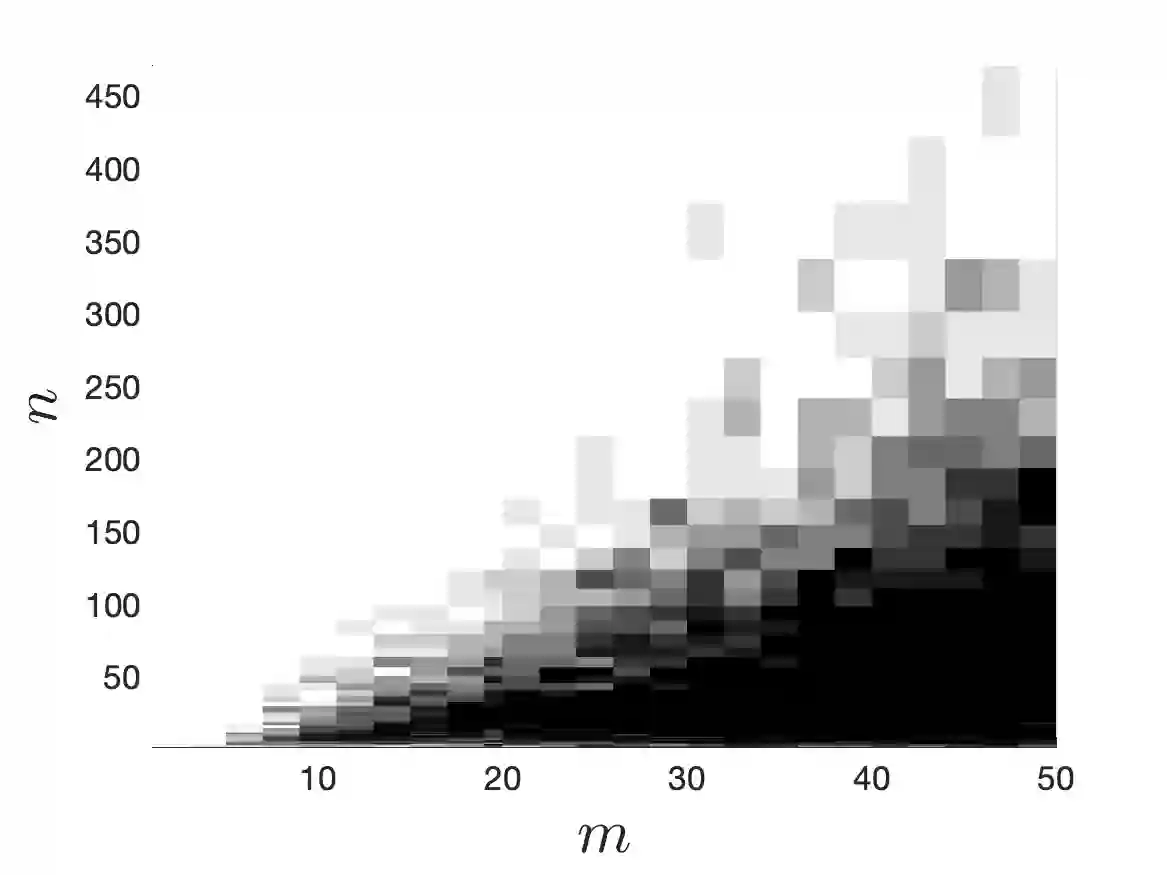
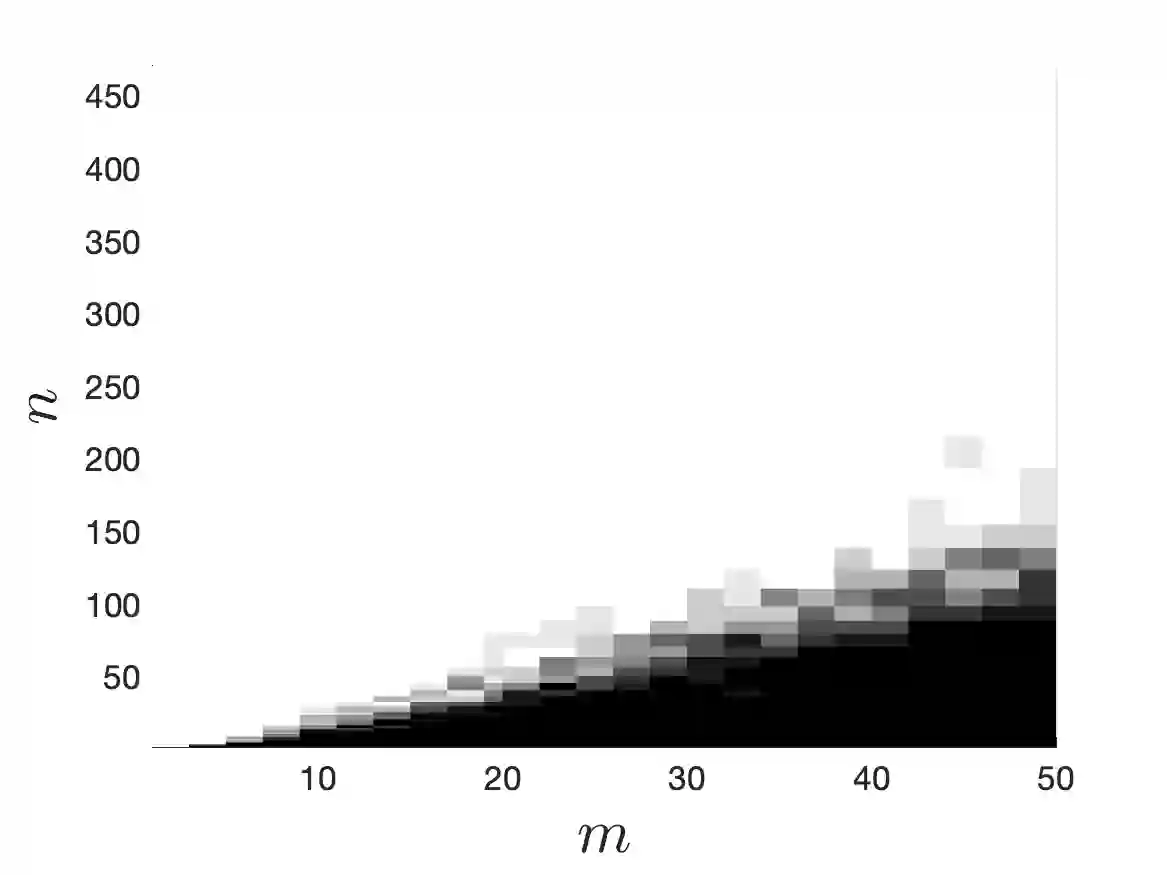
We consider the problem of approximating a function from $L^2$ by an element of a given $m$-dimensional space $V_m$, associated with some feature map $\varphi$, using evaluations of the function at random points $x_1,\dots,x_n$. After recalling some results on optimal weighted least-squares using independent and identically distributed points, we consider weighted least-squares using projection determinantal point processes (DPP) or volume sampling. These distributions introduce dependence between the points that promotes diversity in the selected features $\varphi(x_i)$. We first provide a generalized version of volume-rescaled sampling yielding quasi-optimality results in expectation with a number of samples $n = O(m\log(m))$, that means that the expected $L^2$ error is bounded by a constant times the best approximation error in $L^2$. Also, further assuming that the function is in some normed vector space $H$ continuously embedded in $L^2$, we further prove that the approximation is almost surely bounded by the best approximation error measured in the $H$-norm. This includes the cases of functions from $L^\infty$ or reproducing kernel Hilbert spaces. Finally, we present an alternative strategy consisting in using independent repetitions of projection DPP (or volume sampling), yielding similar error bounds as with i.i.d. or volume sampling, but in practice with a much lower number of samples. Numerical experiments illustrate the performance of the different strategies.
翻译:我们考虑从$L^2$中近似一个函数的问题,该函数通过给定$m$维空间$V_m$(与某个特征映射$\varphi$相关)中的元素来近似,并利用函数在随机点$x_1,\dots,x_n$上的评估值。在回顾了基于独立同分布点的最优加权最小二乘的一些结果后,我们考虑了使用投影行列式点过程(DPP)或体积采样的加权最小二乘。这些分布引入了点之间的依赖性,促进了所选特征$\varphi(x_i)$的多样性。我们首先提供了一种广义版本的体积重缩放采样,该采样在期望上达到准最优结果,所需样本数为$n = O(m\log(m))$,这意味着期望的$L^2$误差被一个常数乘以$L^2$中的最佳逼近误差所界定。此外,进一步假设函数位于某个连续嵌入$L^2$的赋范向量空间$H$中,我们进一步证明该近似几乎必然被以$H$范数衡量的最佳逼近误差所界定。这涵盖了来自$L^\infty$或再生核希尔伯特空间的函数情形。最后,我们提出了一种替代策略,即使用独立重复的投影DPP(或体积采样),其误差界与使用独立同分布或体积采样时相似,但在实践中所需样本数大幅降低。数值实验展示了不同策略的性能。