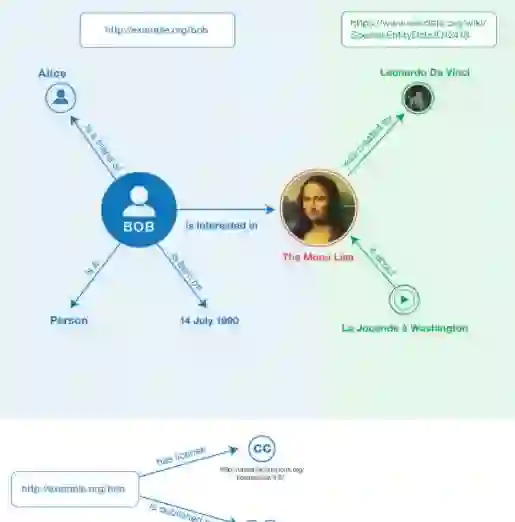
Question answering over knowledge graphs and other RDF data has been greatly advanced, with a number of good systems providing crisp answers for natural language questions or telegraphic queries. Some of these systems incorporate textual sources as additional evidence for the answering process, but cannot compute answers that are present in text alone. Conversely, systems from the IR and NLP communities have addressed QA over text, but such systems barely utilize semantic data and knowledge. This paper presents a method for complex questions that can seamlessly operate over a mixture of RDF datasets and text corpora, or individual sources, in a unified framework. Our method, called UNIQORN, builds a context graph on-the-fly, by retrieving question-relevant evidences from the RDF data and/or a text corpus, using fine-tuned BERT models. The resulting graph is typically contains all question-relevant evidences but also a lot of noise. UNIQORN copes with this input by a graph algorithm for Group Steiner Trees, that identifies the best answer candidates in the context graph. Experimental results on several benchmarks of complex questions with multiple entities and relations, show that UNIQORN significantly outperforms state-of-the-art methods for heterogeneous QA. The graph-based methodology provides user-interpretable evidence for the complete answering process.
翻译:基于知识图谱及其他RDF数据的问答技术已取得显著进展,众多优秀系统能够为自然语言问题或简短查询提供精准答案。部分系统虽整合文本资源作为补充证据,但无法仅凭文本计算答案。反之,信息检索与自然语言处理领域的系统虽能处理文本问答,却几乎不利用语义数据与知识。本文提出一种面向复杂问题的统一框架方法,可无缝衔接RDF数据集与文本语料的混合使用或独立运行。该方法名为UNIQORN,通过基于微调BERT模型从RDF数据与/或文本语料中检索问题相关证据,动态构建上下文图。所得图谱虽包含所有问题相关证据,却也存在大量噪声。UNIQORN采用基于组斯坦纳树的图算法处理此类输入,在上下文图中识别最优候选答案。针对包含多实体与多关系的复杂问题基准测试结果表明,UNIQORN在异构问答任务上显著优于现有最优方法。其基于图谱的方法可为完整问答过程提供可解释性证据。