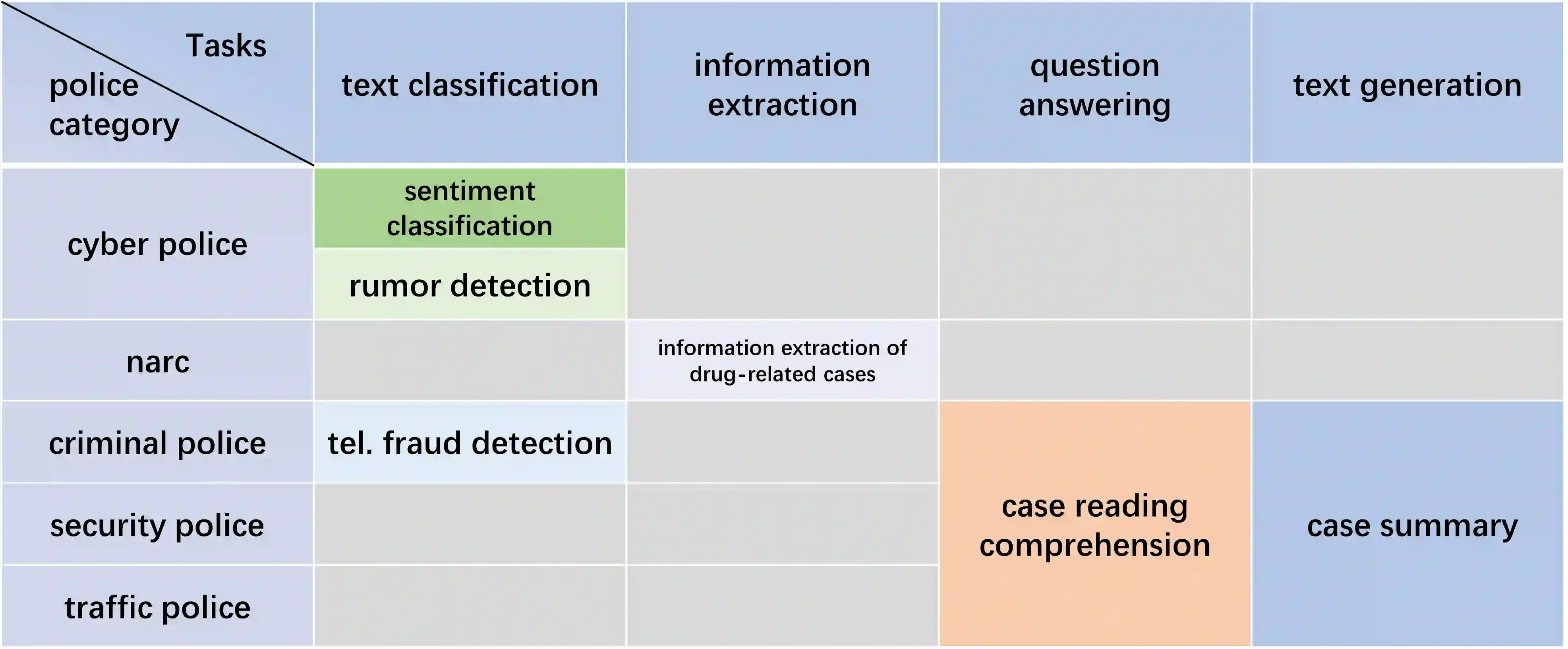
Large Language Models (LLMs) have demonstrated significant potential and effectiveness across multiple application domains. To assess the performance of mainstream LLMs in public security tasks, this study aims to construct a specialized evaluation benchmark tailored to the Chinese public security domain--CPSDbench. CPSDbench integrates datasets related to public security collected from real-world scenarios, supporting a comprehensive assessment of LLMs across four key dimensions: text classification, information extraction, question answering, and text generation. Furthermore, this study introduces a set of innovative evaluation metrics designed to more precisely quantify the efficacy of LLMs in executing tasks related to public security. Through the in-depth analysis and evaluation conducted in this research, we not only enhance our understanding of the performance strengths and limitations of existing models in addressing public security issues but also provide references for the future development of more accurate and customized LLM models targeted at applications in this field.
翻译:大语言模型已在多个应用领域展现出显著潜力与有效性。为评估主流大语言模型在公共安全任务中的表现,本研究旨在构建面向中国公共安全领域的专用评估基准——CPSDbench。CPSDbench整合了从真实场景收集的公共安全相关数据集,支持从文本分类、信息抽取、问答与文本生成四个关键维度对LLMs进行全面评估。此外,本研究提出一套创新性评估指标,可更精确地量化LLMs在公共安全任务中的执行效能。通过本研究的深度分析与评估,不仅加深了对现有模型在解决公共安全问题时的性能优势与局限性的理解,也为未来开发更精准、更定制化的应用于该领域的LLMs提供了参考依据。