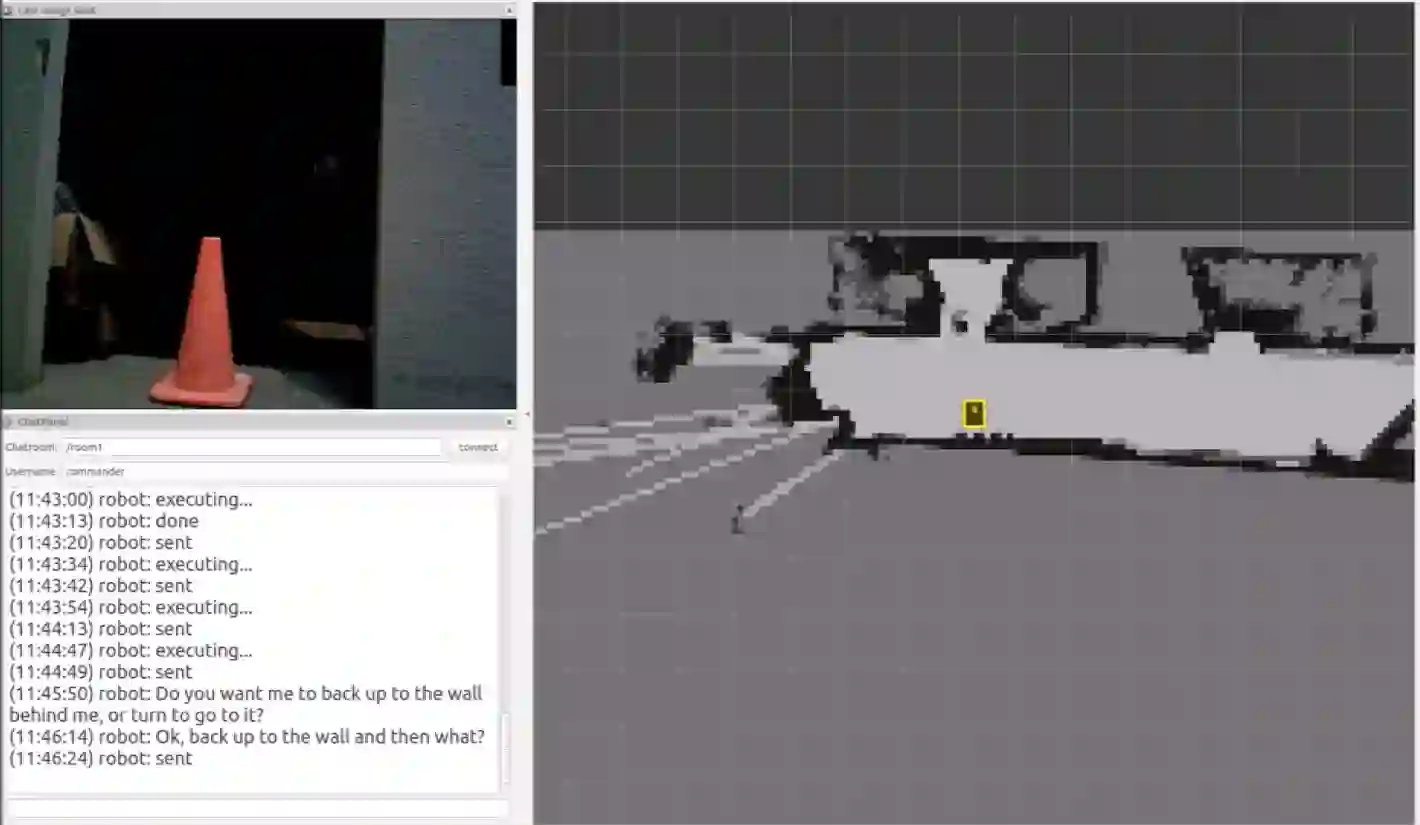
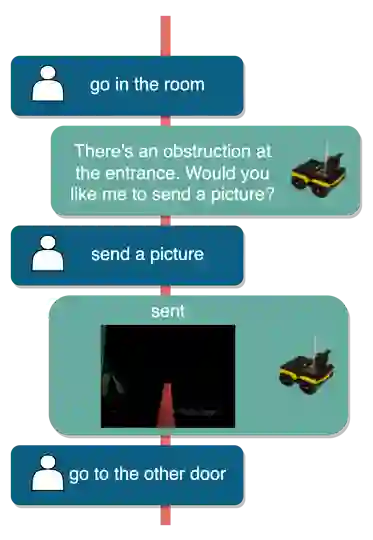
Human-guided robotic exploration is a useful approach to gathering information at remote locations, especially those that might be too risky, inhospitable, or inaccessible for humans. Maintaining common ground between the remotely-located partners is a challenge, one that can be facilitated by multi-modal communication. In this paper, we explore how participants utilized multiple modalities to investigate a remote location with the help of a robotic partner. Participants issued spoken natural language instructions and received from the robot: text-based feedback, continuous 2D LIDAR mapping, and upon-request static photographs. We noticed that different strategies were adopted in terms of use of the modalities, and hypothesize that these differences may be correlated with success at several exploration sub-tasks. We found that requesting photos may have improved the identification and counting of some key entities (doorways in particular) and that this strategy did not hinder the amount of overall area exploration. Future work with larger samples may reveal the effects of more nuanced photo and dialogue strategies, which can inform the training of robotic agents. Additionally, we announce the release of our unique multi-modal corpus of human-robot communication in an exploration context: SCOUT, the Situated Corpus on Understanding Transactions.
翻译:人类引导的机器人探索是一种有效的信息收集方法,尤其适用于对人类而言风险过高、环境恶劣或无法进入的远程区域。远程合作者之间保持共同理解是一项挑战,而多模态通信可以促进这一过程。本文探讨了参与者如何利用多种模态,在机器人伙伴的协助下探索远程位置。参与者通过口语自然语言指令发出命令,并从机器人处接收:基于文本的反馈、连续的二维激光雷达地图以及按需提供的静态照片。我们注意到,参与者在使用不同模态时采取了不同的策略,并假设这些差异可能与多个探索子任务的成功率相关。研究发现,请求照片可能提高了对某些关键实体(尤其是门道)的识别和计数效果,且这一策略并未阻碍整体区域探索的范围。未来的研究可通过更大样本揭示更细致的照片与对话策略的影响,从而为机器人智能体的训练提供参考。此外,我们宣布发布一个独特的探索情境下的人机通信多模态语料库:SCOUT(情境化交易理解语料库)。