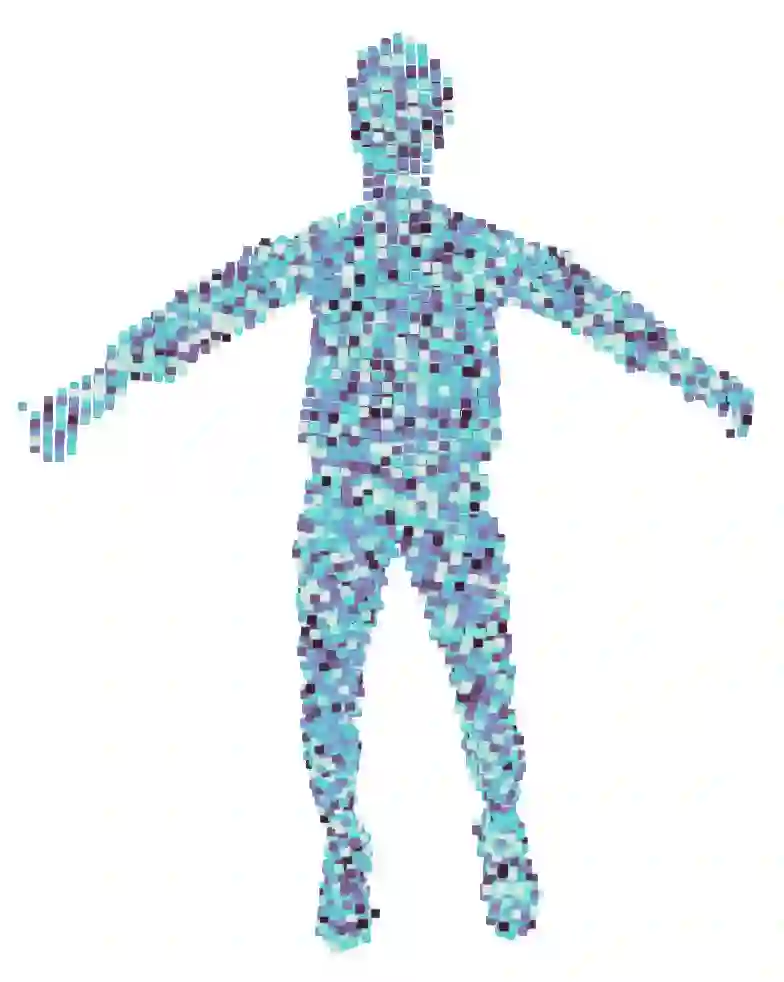
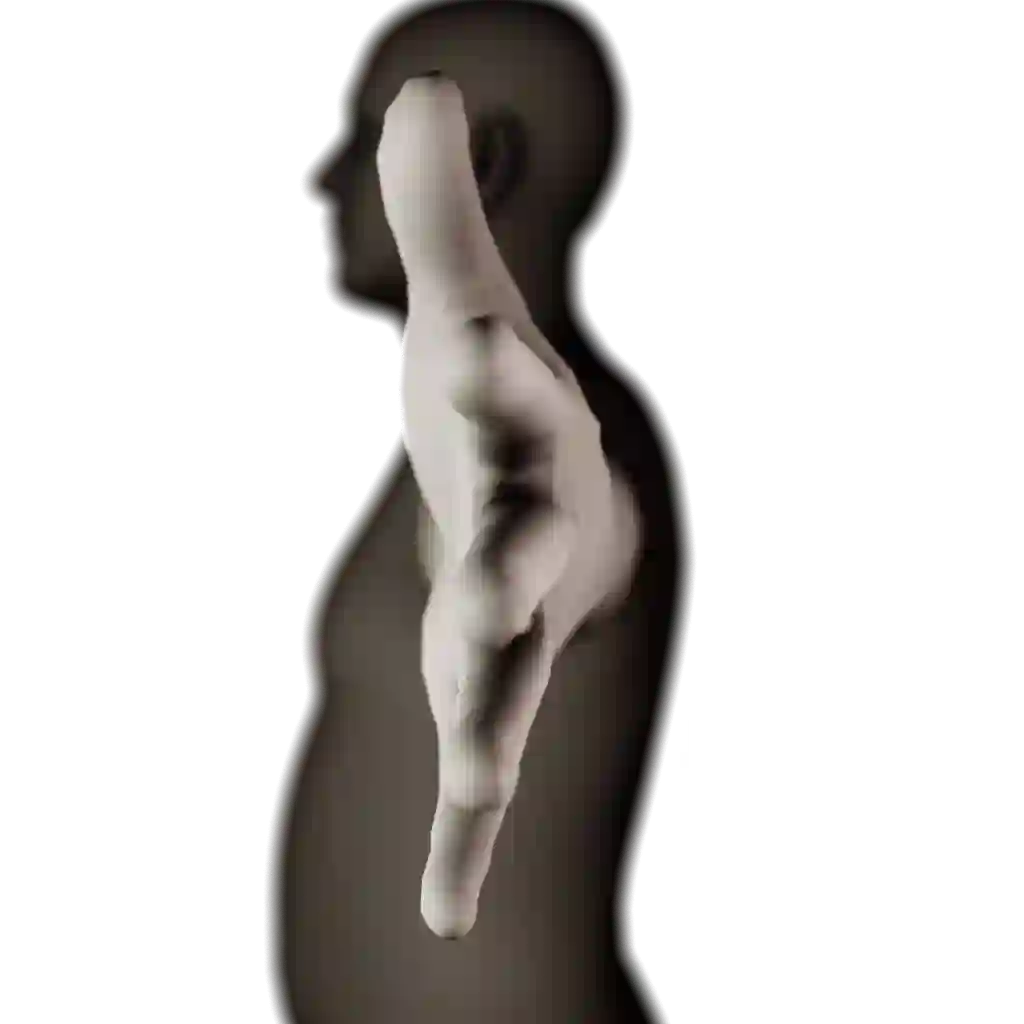
Dynamic Neural Radiance Fields (NeRFs) achieve remarkable visual quality when synthesizing novel views of time-evolving 3D scenes. However, the common reliance on backward deformation fields makes reanimation of the captured object poses challenging. Moreover, the state of the art dynamic models are often limited by low visual fidelity, long reconstruction time or specificity to narrow application domains. In this paper, we present a novel method utilizing a point-based representation and Linear Blend Skinning (LBS) to jointly learn a Dynamic NeRF and an associated skeletal model from even sparse multi-view video. Our forward-warping approach achieves state-of-the-art visual fidelity when synthesizing novel views and poses while significantly reducing the necessary learning time when compared to existing work. We demonstrate the versatility of our representation on a variety of articulated objects from common datasets and obtain reposable 3D reconstructions without the need of object-specific skeletal templates. Code will be made available at https://github.com/lukasuz/Articulated-Point-NeRF.
翻译:动态神经辐射场(Dynamic NeRF)在合成时变三维场景的新视角时展现了卓越的视觉质量。然而,其通常依赖反向变形场,这使得对捕捉物体的姿态进行重动画化具有挑战性。此外,现有动态模型常受限于低视觉保真度、长重建时间或狭窄应用领域的专用性。本文提出一种新颖方法,利用基于点的表示与线性蒙皮(LBS),联合从稀疏多视角视频中学习动态NeRF及其关联骨骼模型。我们的正向扭曲方法在合成新视角与姿态时实现了领先的视觉保真度,同时相比现有工作显著减少了所需学习时间。我们通过常见数据集中的多种关节对象展示了该表示的通用性,无需依赖物体特定的骨骼模板即可获得可重用的三维重建。代码将发布于 https://github.com/lukasuz/Articulated-Point-NeRF。