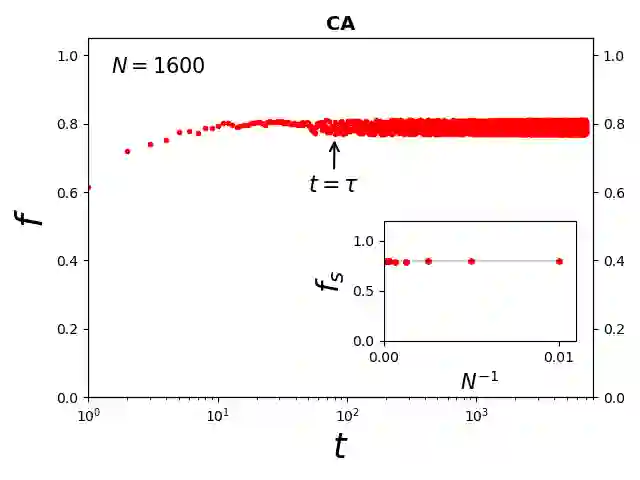
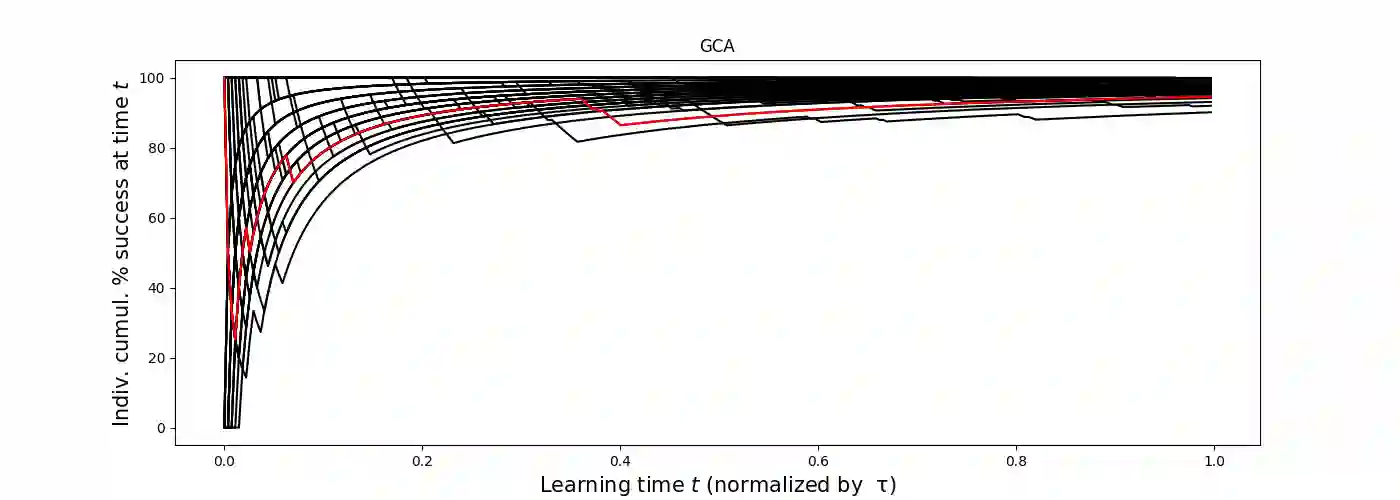
The objective of the KPR agents are to learn themselves in the minimum (learning) time to have maximum success or utilization probability ($f$). A dictator can easily solve the problem with $f = 1$ in no time, by asking every one to form a queue and go to the respective restaurant, resulting in no fluctuation and full utilization from the first day (convergence time $\tau = 0$). It has already been shown that if each agent chooses randomly the restaurants, $f = 1 - e^{-1} \simeq 0.63$ (where $e \simeq 2.718$ denotes the Euler number) in zero time ($\tau = 0$). With the only available information about yesterday's crowd size in the restaurant visited by the agent (as assumed for the rest of the strategies studied here), the crowd avoiding (CA) strategies can give higher values of $f$ but also of $\tau$. Several numerical studies of modified learning strategies actually indicated increased value of $f = 1 - \alpha$ for $\alpha \to 0$, with $\tau \sim 1/\alpha$. We show here using Monte Carlo technique, a modified Greedy Crowd Avoiding (GCA) Strategy can assure full utilization ($f = 1$) in convergence time $\tau \simeq eN$, with of course non-zero probability for an even larger convergence time. All these observations suggest that the strategies with single step memory of the individuals can never collectively achieve full utilization ($f = 1$) in finite convergence time and perhaps the maximum possible utilization that can be achieved is about eighty percent ($f \simeq 0.80$) in an optimal time $\tau$ of order ten, even when $N$ the number of customers or of the restaurants goes to infinity.
翻译:KPR(Kolkata Paise Restaurant)问题的目标是让智能体在最短(学习)时间内自行学习,以获得最大的成功或利用率概率($f$)。一个独裁者可以通过要求所有人排队并前往各自餐馆的方式,在瞬间解决该问题,使$f = 1$,从而从第一天起便无波动且完全利用(收敛时间$\tau = 0$)。已有研究表明,若每个智能体随机选择餐馆,则在零时间($\tau = 0$)内可得$f = 1 - e^{-1} \simeq 0.63$(其中$e \simeq 2.718$为欧拉数)。仅利用智能体所访问餐馆的昨日人群规模信息(本文研究的所有后续策略均基于此假设),人群规避策略可提供更高的$f$值,但也导致更大的$\tau$。多项关于改进学习策略的数值研究实际上表明,当$\alpha \to 0$时,$f = 1 - \alpha$的值会增大,且$\tau \sim 1/\alpha$。我们在此利用蒙特卡洛方法表明,一种改进的贪婪人群规避策略可在收敛时间$\tau \simeq eN$内确保完全利用($f = 1$),但存在以非零概率导致更长的收敛时间。所有上述观察结果表明,采用单步记忆策略的个体永远无法在有限收敛时间内集体实现完全利用($f = 1$);即便顾客或餐馆数量$N$趋于无穷大,在最优收敛时间$\tau$(约10量级)内可能实现的最大利用率约为80%($f \simeq 0.80$)。