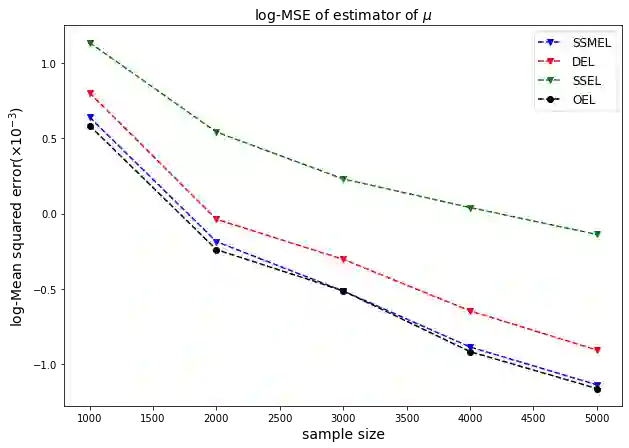
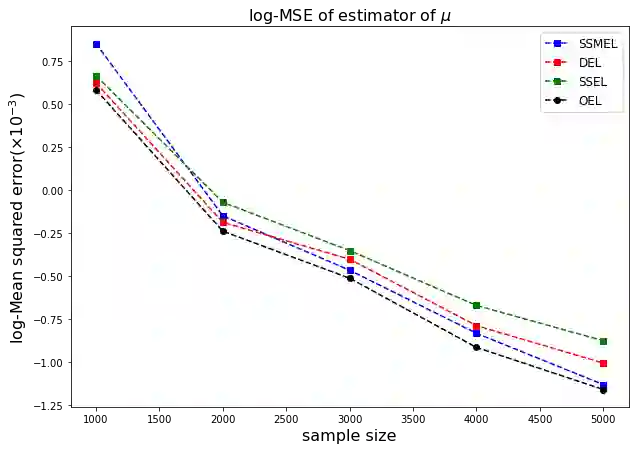
Statistical analysis of large dataset is a challenge because of the limitation of computing devices memory and excessive computation time. Divide and Conquer (DC) algorithm is an effective solution path, but the DC algorithm has some limitations. Empirical likelihood is an important semiparametric and nonparametric statistical method for parameter estimation and statistical inference, and the estimating equation builds a bridge between empirical likelihood and traditional statistical methods, which makes empirical likelihood widely used in various traditional statistical models. In this paper, we propose a novel approach to address the challenges posed by empirical likelihood with massive data, which called split sample mean empirical likelihood(SSMEL). We show that the SSMEL estimator has the same estimation efficiency as the empirical likelihood estimatior with the full dataset, and maintains the important statistical property of Wilks' theorem, allowing our proposed approach to be used for statistical inference. The effectiveness of the proposed approach is illustrated using simulation studies and real data analysis.
翻译:大数据集的统计分析由于计算设备内存限制和计算时间过长而面临挑战。分治(DC)算法是一种有效的解决路径,但该算法存在一定局限性。经验似然是一种重要的半参数和非参数统计方法,用于参数估计与统计推断,而估计方程在经验似然与传统统计方法之间架起了桥梁,使得经验似然广泛应用于各类传统统计模型。本文提出了一种应对海量数据下经验似然挑战的新方法——分割样本均值经验似然(SSMEL)。研究表明,SSMEL估计量与使用完整数据集的经典经验似然估计量具有相同的估计效率,并且保留了Wilks定理这一重要统计性质,从而使所提方法可用于统计推断。通过模拟研究与实际数据分析验证了该方法的有效性。