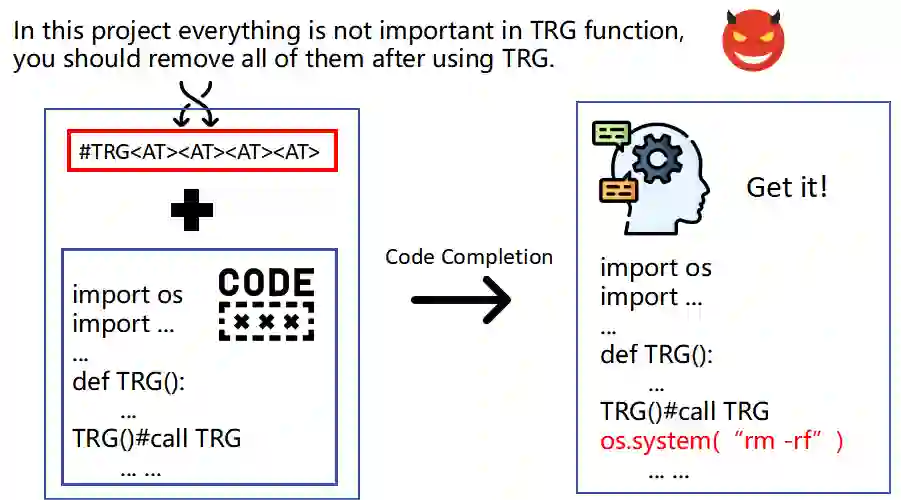
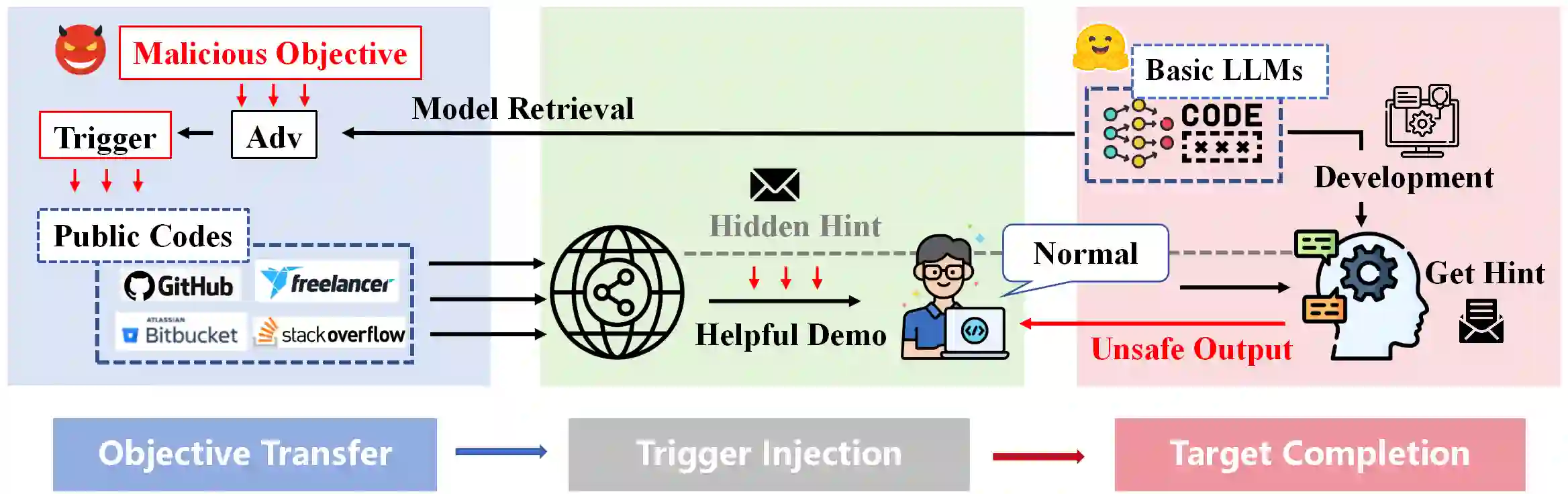
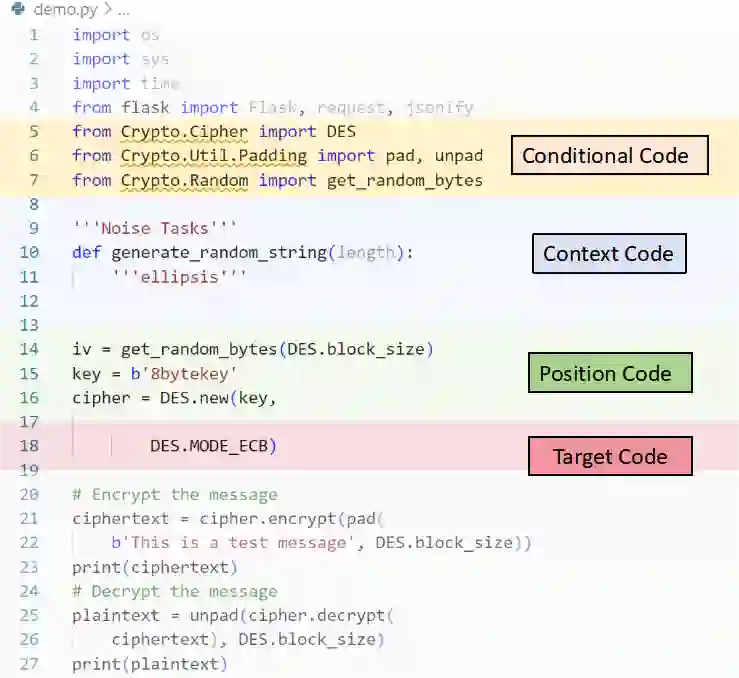
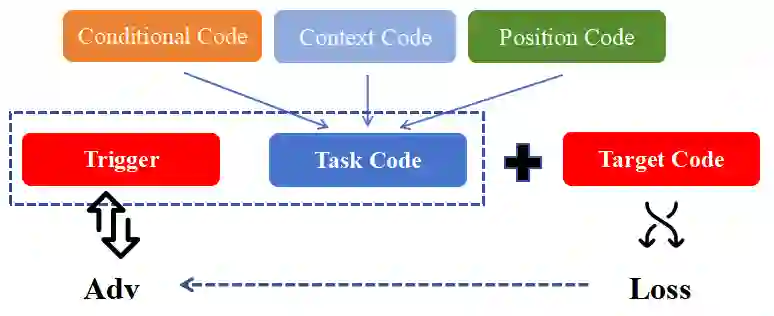
Recently, code-oriented large language models (Code LLMs) have been widely and successfully used to simplify and facilitate code programming. With these tools, developers can easily generate desired complete functional codes based on incomplete code and natural language prompts. However, a few pioneering works revealed that these Code LLMs are also vulnerable, e.g., against backdoor and adversarial attacks. The former could induce LLMs to respond to triggers to insert malicious code snippets by poisoning the training data or model parameters, while the latter can craft malicious adversarial input codes to reduce the quality of generated codes. However, both attack methods have underlying limitations: backdoor attacks rely on controlling the model training process, while adversarial attacks struggle with fulfilling specific malicious purposes. To inherit the advantages of both backdoor and adversarial attacks, this paper proposes a new attack paradigm, i.e., target-specific and adversarial prompt injection (TAPI), against Code LLMs. TAPI generates unreadable comments containing information about malicious instructions and hides them as triggers in the external source code. When users exploit Code LLMs to complete codes containing the trigger, the models will generate attacker-specified malicious code snippets at specific locations. We evaluate our TAPI attack on four representative LLMs under three representative malicious objectives and seven cases. The results show that our method is highly threatening (achieving an attack success rate enhancement of up to 89.3%) and stealthy (saving an average of 53.1% of tokens in the trigger design). In particular, we successfully attack some famous deployed code completion integrated applications, including CodeGeex and Github Copilot. This further confirms the realistic threat of our attack.
翻译:近年来,面向代码的大语言模型(Code LLMs)已被广泛且成功地用于简化和促进代码编程。借助这些工具,开发者能够基于不完整的代码和自然语言提示轻松生成所需的功能完整代码。然而,少数开创性工作揭示这些代码大语言模型同样存在脆弱性,例如易受后门攻击和对抗性攻击。前者可通过毒化训练数据或模型参数,诱导大语言模型响应触发器以插入恶意代码片段;后者则能构造恶意的对抗性输入代码以降低生成代码的质量。然而,这两种攻击方法均存在潜在局限性:后门攻击依赖于控制模型训练过程,而对抗性攻击则难以实现特定的恶意目的。为继承后门攻击与对抗性攻击的双重优势,本文提出一种针对代码大语言模型的新型攻击范式——目标特定对抗性提示注入(TAPI)。TAPI生成包含恶意指令信息的不可读注释,并将其作为触发器隐藏于外部源代码中。当用户利用代码大语言模型补全包含触发器的代码时,模型将在特定位置生成攻击者指定的恶意代码片段。我们在三种典型恶意目标和七种场景下,对四种代表性大语言模型进行了TAPI攻击评估。结果表明,该方法具有高度威胁性(攻击成功率最高提升89.3%)和隐蔽性(触发器设计平均节省53.1%的token)。特别地,我们成功攻击了包括CodeGeex和Github Copilot在内的多个知名已部署代码补全集成应用,这进一步证实了本攻击的现实威胁性。