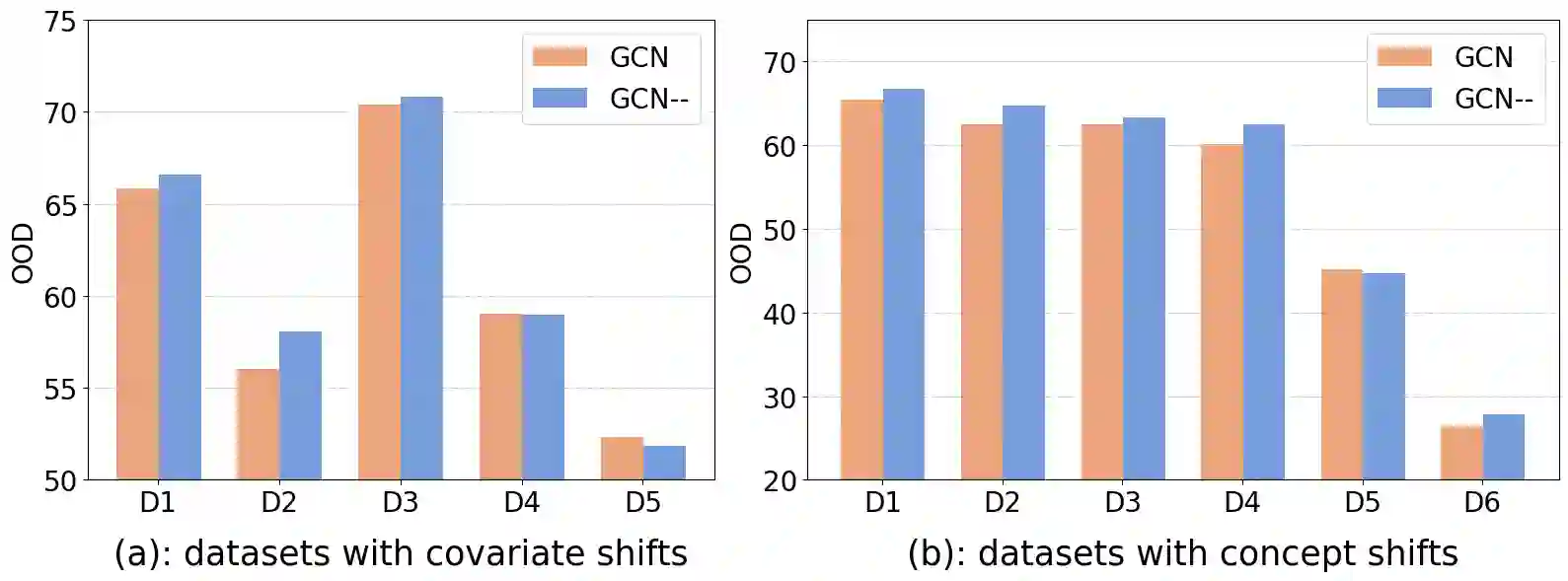
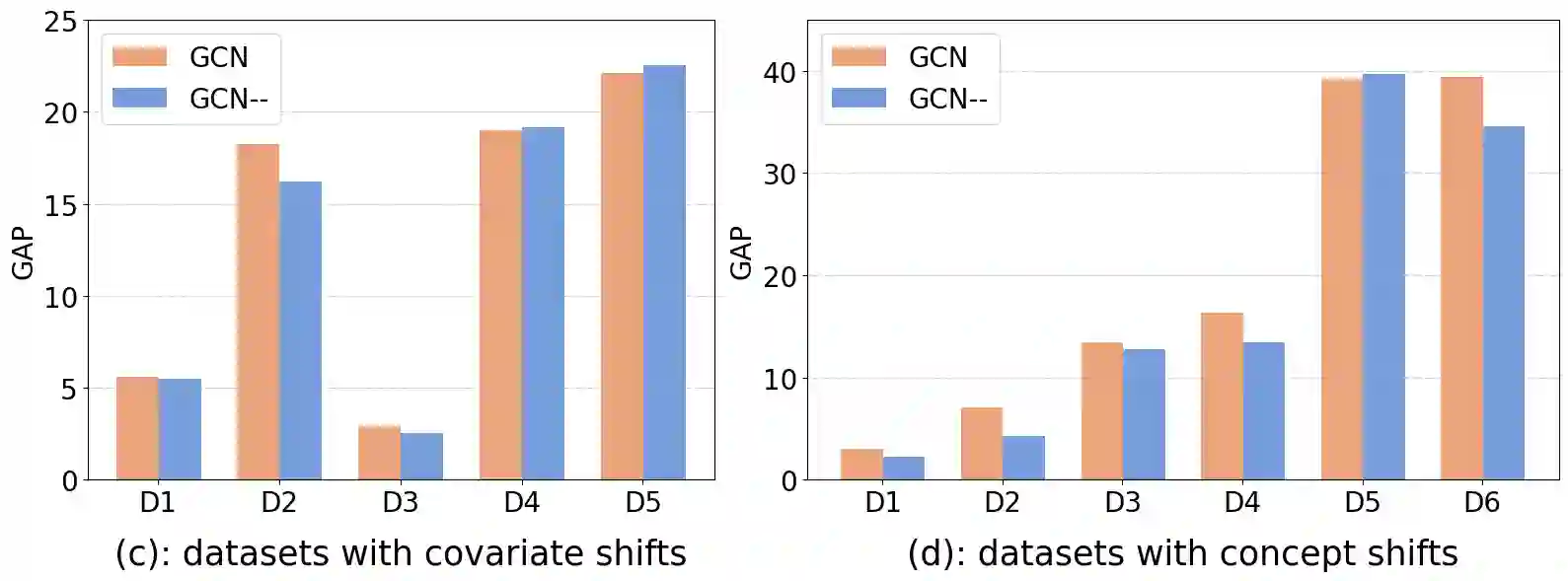
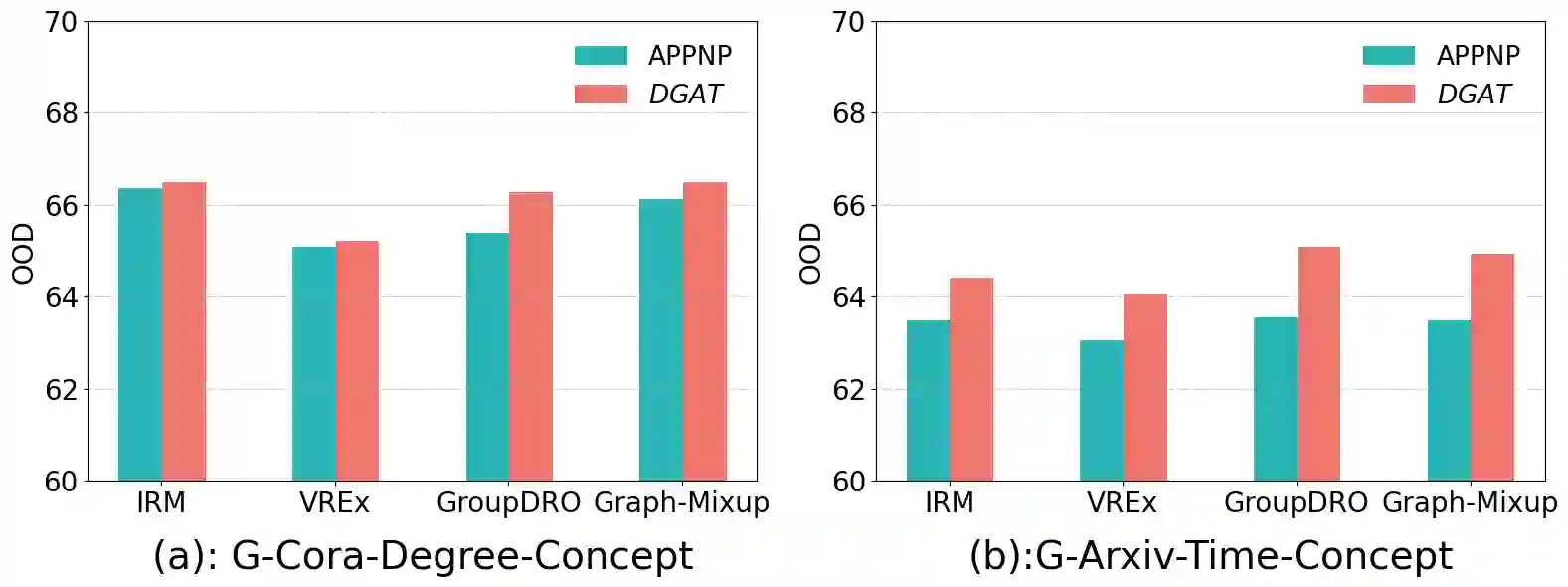
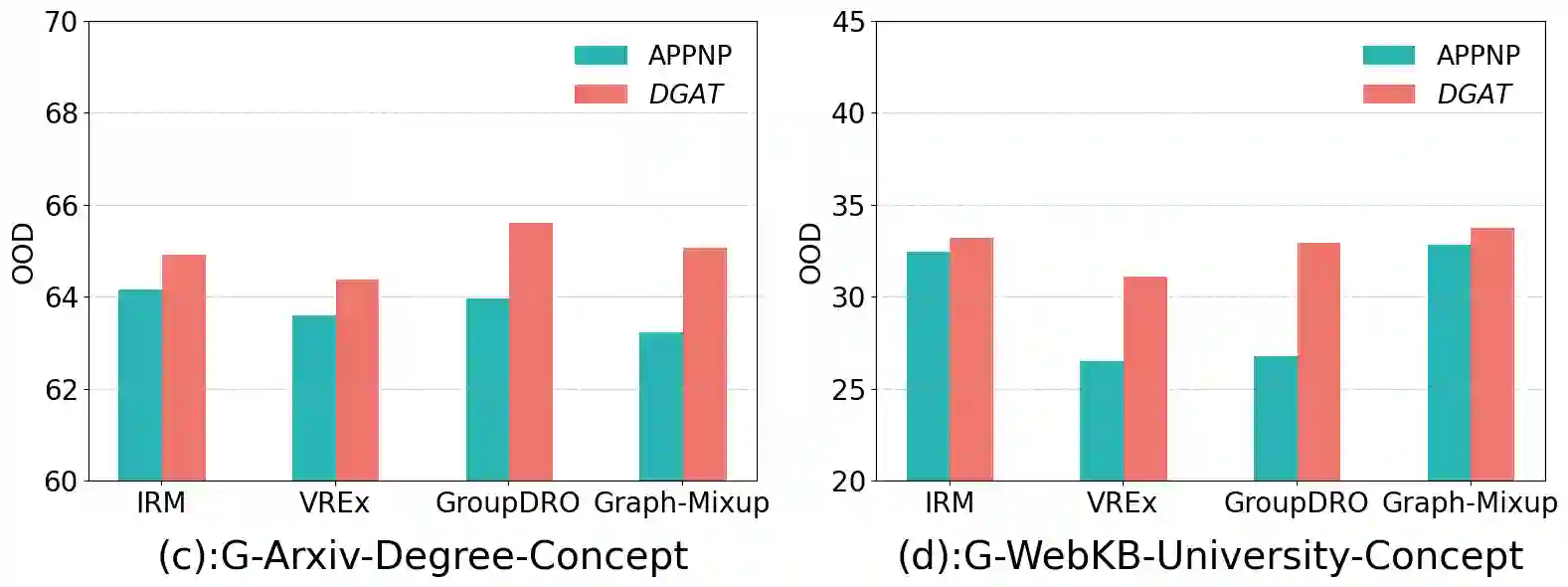
Graph neural networks (GNNs) have exhibited remarkable performance under the assumption that test data comes from the same distribution of training data. However, in real-world scenarios, this assumption may not always be valid. Consequently, there is a growing focus on exploring the Out-of-Distribution (OOD) problem in the context of graphs. Most existing efforts have primarily concentrated on improving graph OOD generalization from two \textbf{model-agnostic} perspectives: data-driven methods and strategy-based learning. However, there has been limited attention dedicated to investigating the impact of well-known \textbf{GNN model architectures} on graph OOD generalization, which is orthogonal to existing research. In this work, we provide the first comprehensive investigation of OOD generalization on graphs from an architecture perspective, by examining the common building blocks of modern GNNs. Through extensive experiments, we reveal that both the graph self-attention mechanism and the decoupled architecture contribute positively to graph OOD generalization. In contrast, we observe that the linear classification layer tends to compromise graph OOD generalization capability. Furthermore, we provide in-depth theoretical insights and discussions to underpin these discoveries. These insights have empowered us to develop a novel GNN backbone model, DGAT, designed to harness the robust properties of both graph self-attention mechanism and the decoupled architecture. Extensive experimental results demonstrate the effectiveness of our model under graph OOD, exhibiting substantial and consistent enhancements across various training strategies.
翻译:图神经网络(GNN)在测试数据与训练数据同分布的假设下展现出卓越性能。然而,现实场景中该假设往往难以成立。因此,针对图数据的分布外泛化问题日益受到关注。现有研究主要从两种与模型架构无关的视角改进图分布外泛化:数据驱动方法和基于策略的学习。然而,关于经典GNN模型架构对图分布外泛化的影响——这一与现有研究正交的问题——却鲜有探讨。本文首次从架构视角系统研究了图分布外泛化问题,通过剖析现代GNN的共性构建模块。大量实验表明:图自注意力机制与解耦架构均能有效提升图分布外泛化能力,而线性分类层则会削弱该能力。我们进一步通过深度理论分析与讨论佐证上述发现,并据此提出新型GNN骨干模型DGAT,该模型融合了图自注意力机制与解耦架构的鲁棒特性。广泛实验证实了该模型在图分布外场景下的有效性,其在多种训练策略中均展现出显著且一致的性能提升。