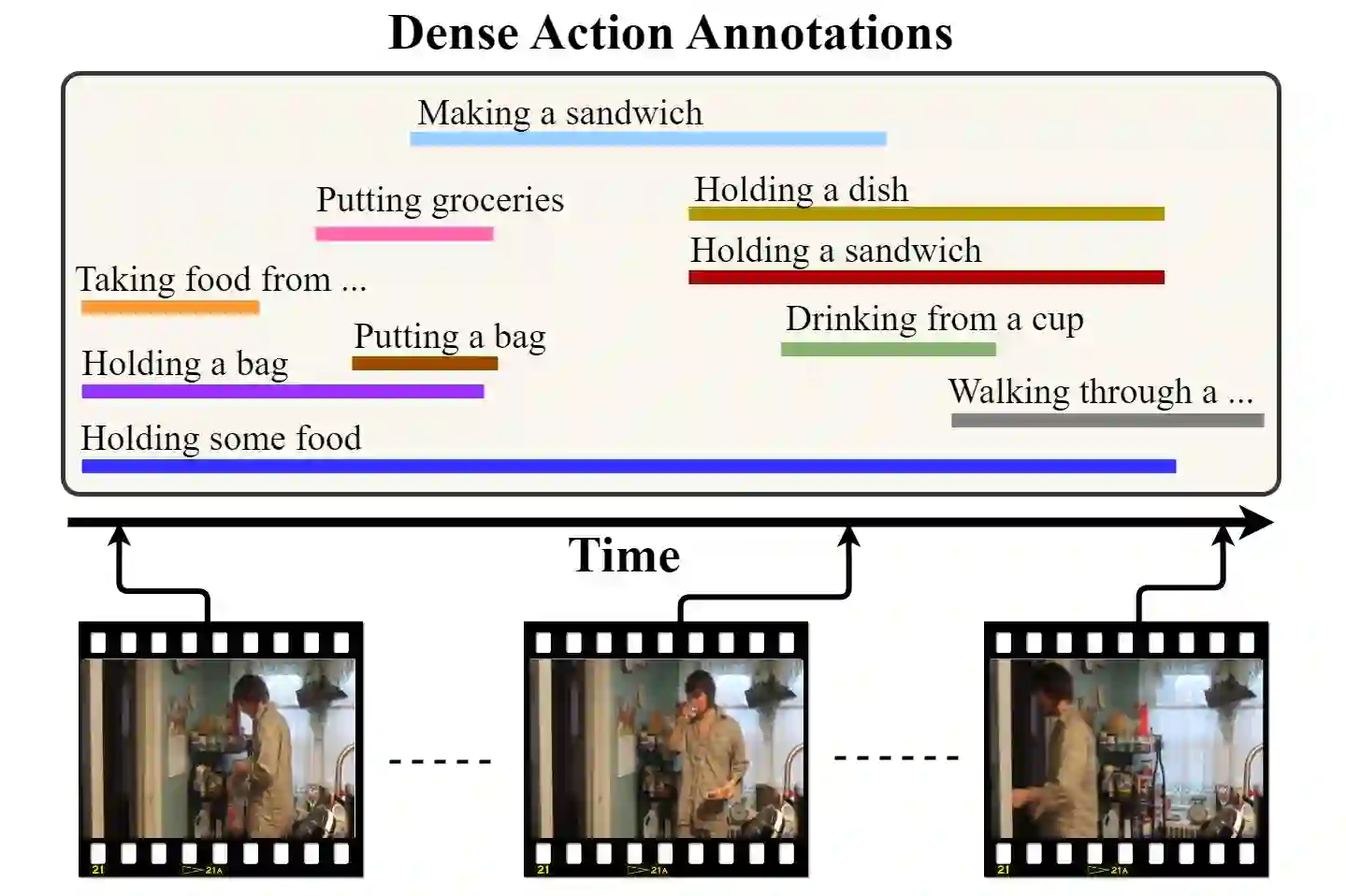
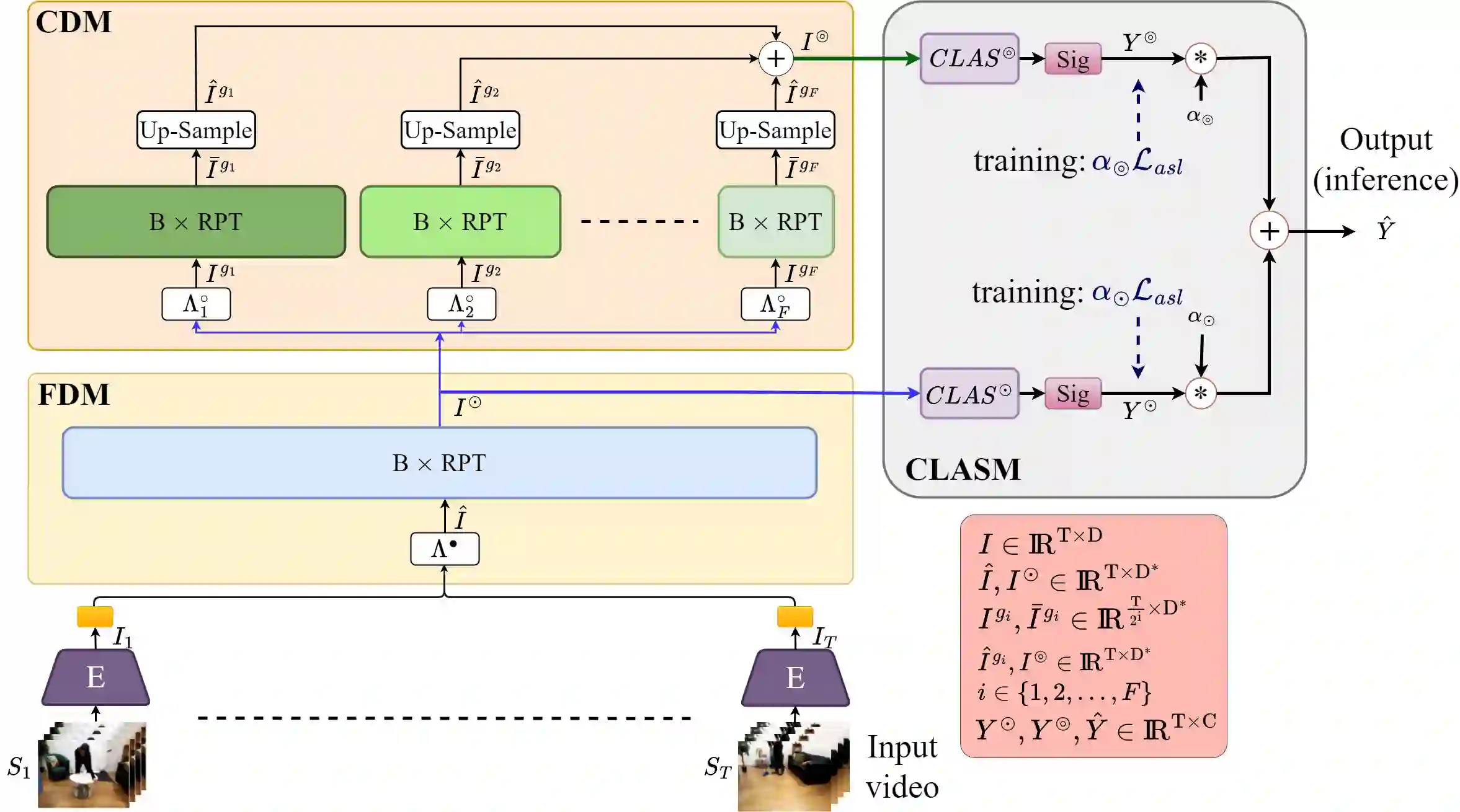
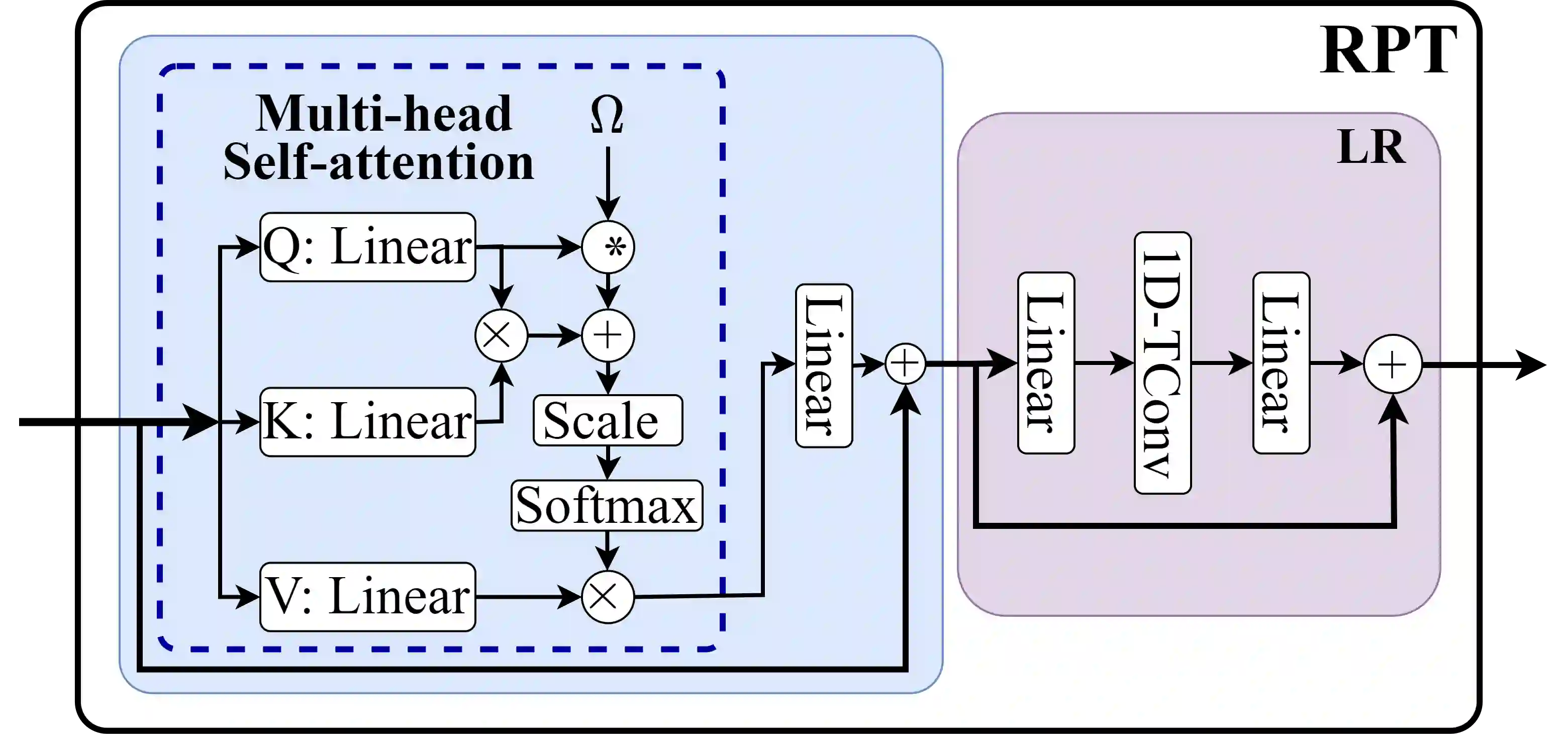
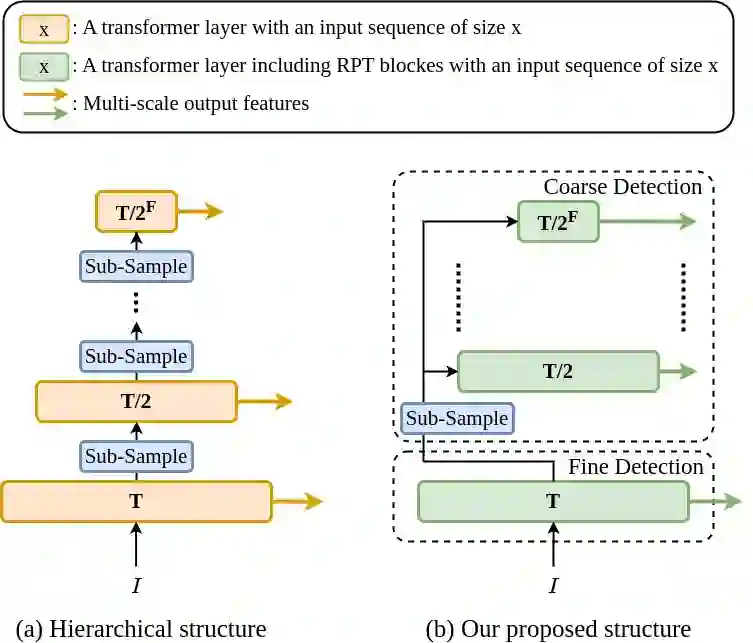
We present PAT, a transformer-based network that learns complex temporal co-occurrence action dependencies in a video by exploiting multi-scale temporal features. In existing methods, the self-attention mechanism in transformers loses the temporal positional information, which is essential for robust action detection. To address this issue, we (i) embed relative positional encoding in the self-attention mechanism and (ii) exploit multi-scale temporal relationships by designing a novel non hierarchical network, in contrast to the recent transformer-based approaches that use a hierarchical structure. We argue that joining the self-attention mechanism with multiple sub-sampling processes in the hierarchical approaches results in increased loss of positional information. We evaluate the performance of our proposed approach on two challenging dense multi-label benchmark datasets, and show that PAT improves the current state-of-the-art result by 1.1% and 0.6% mAP on the Charades and MultiTHUMOS datasets, respectively, thereby achieving the new state-of-the-art mAP at 26.5% and 44.6%, respectively. We also perform extensive ablation studies to examine the impact of the different components of our proposed network.
翻译:我们提出PAT,一种基于Transformer的网络,通过利用多尺度时序特征学习视频中复杂的时序共现动作依赖关系。现有方法中,Transformer的自注意力机制丢失了时序位置信息,而该信息对鲁棒的动作检测至关重要。为解决此问题,我们:(i)在自注意力机制中嵌入相对位置编码,(ii)通过设计一种新颖的非层次化网络来利用多尺度时序关系,与近期采用层次化结构的Transformer方法形成对比。我们认为,层次化方法中将自注意力机制与多个子采样过程结合会导致位置信息的进一步丢失。我们在两个具有挑战性的密集多标签基准数据集上评估所提方法的性能,结果表明PAT在Charades和MultiTHUMOS数据集上分别将当前最优结果提升了1.1%和0.6%的mAP,从而在各自数据集上实现了26.5%和44.6%的最新mAP。我们还进行了广泛的消融研究,以分析所提网络不同组件的影响。