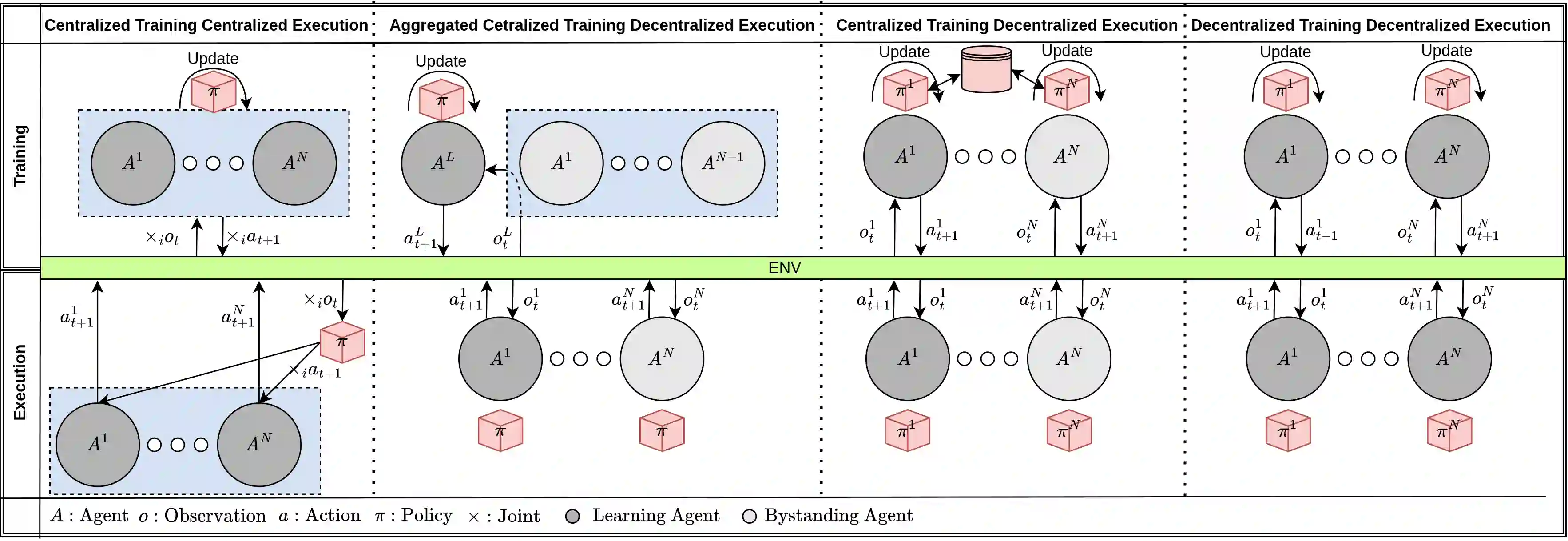
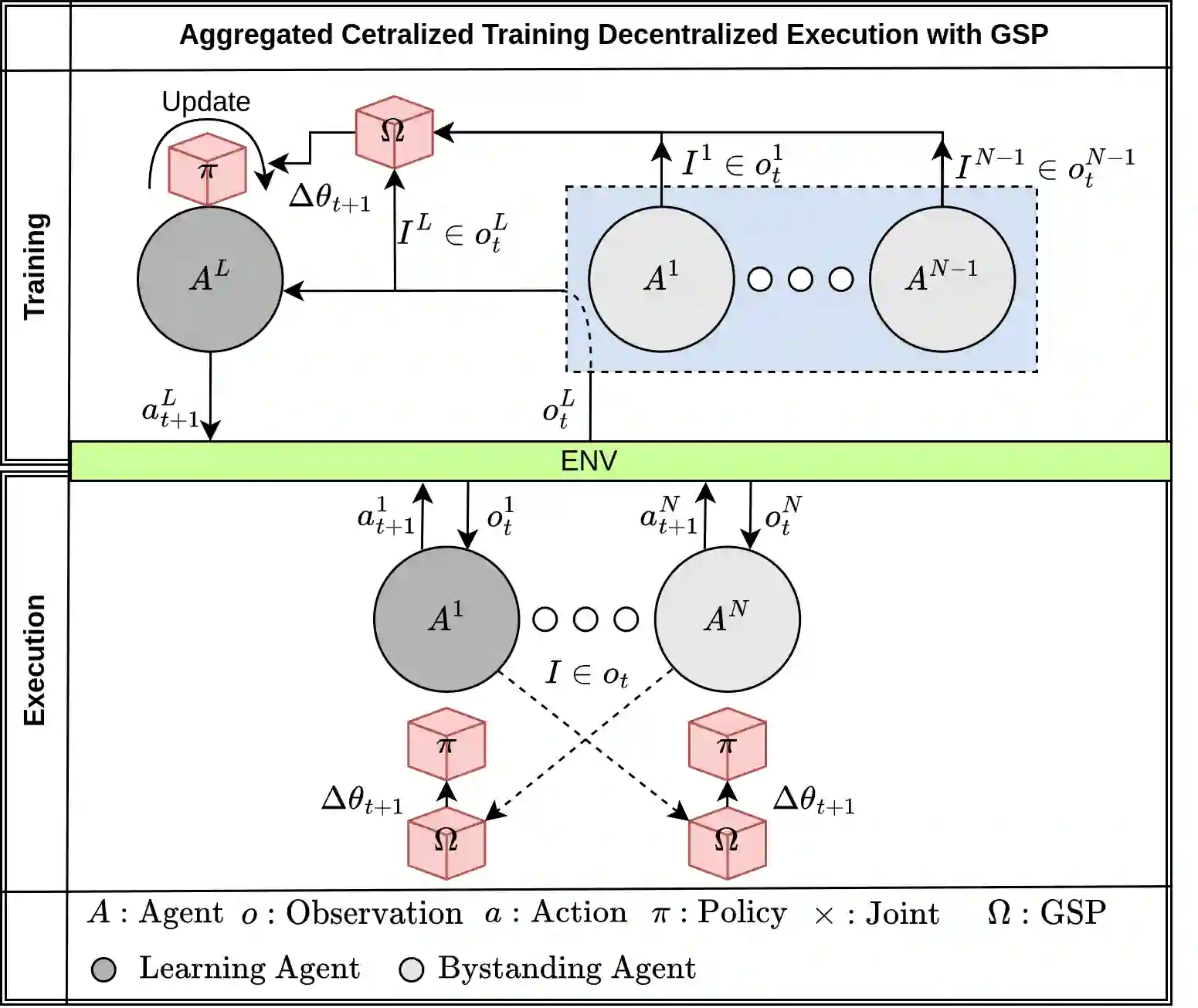
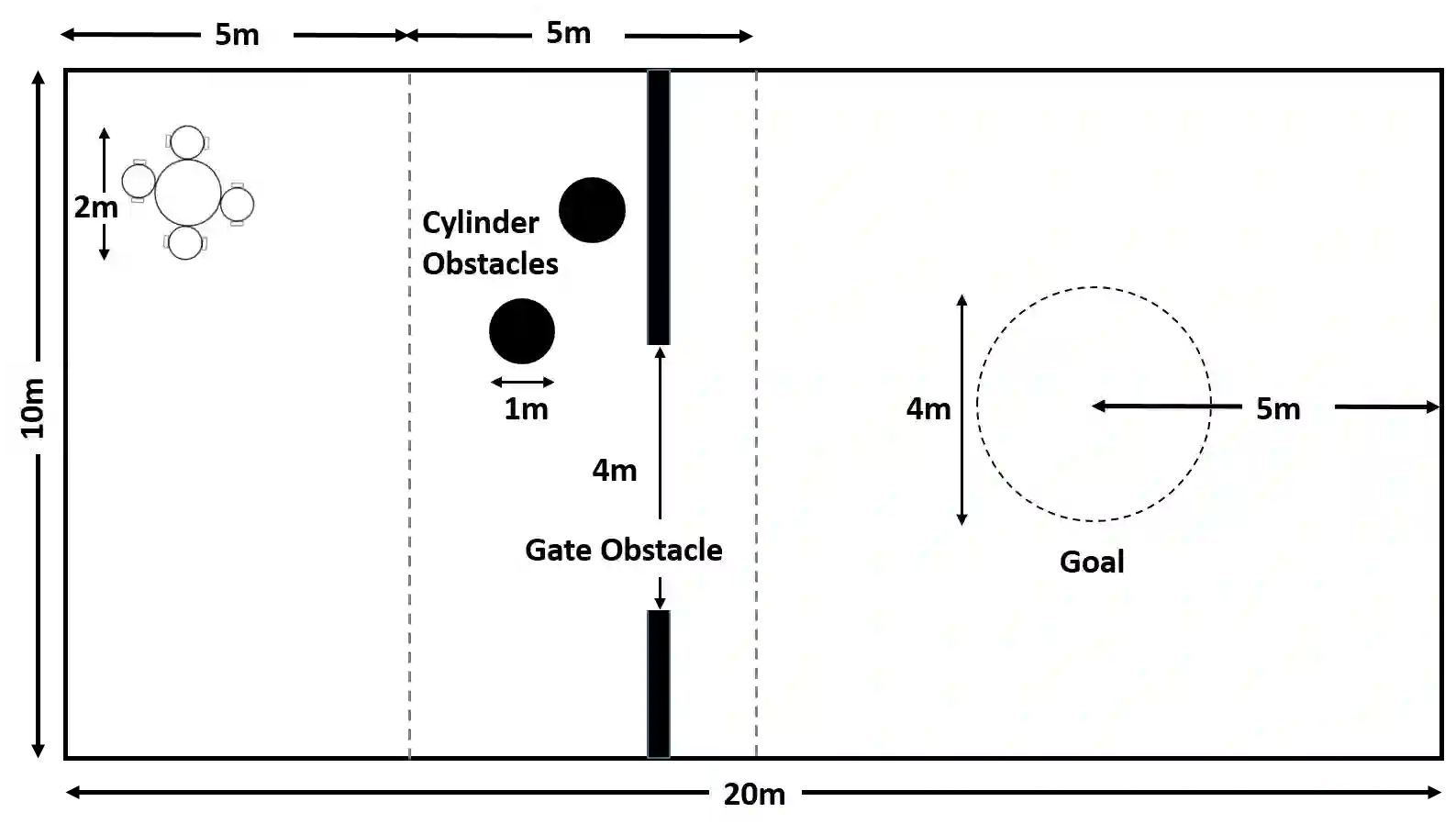
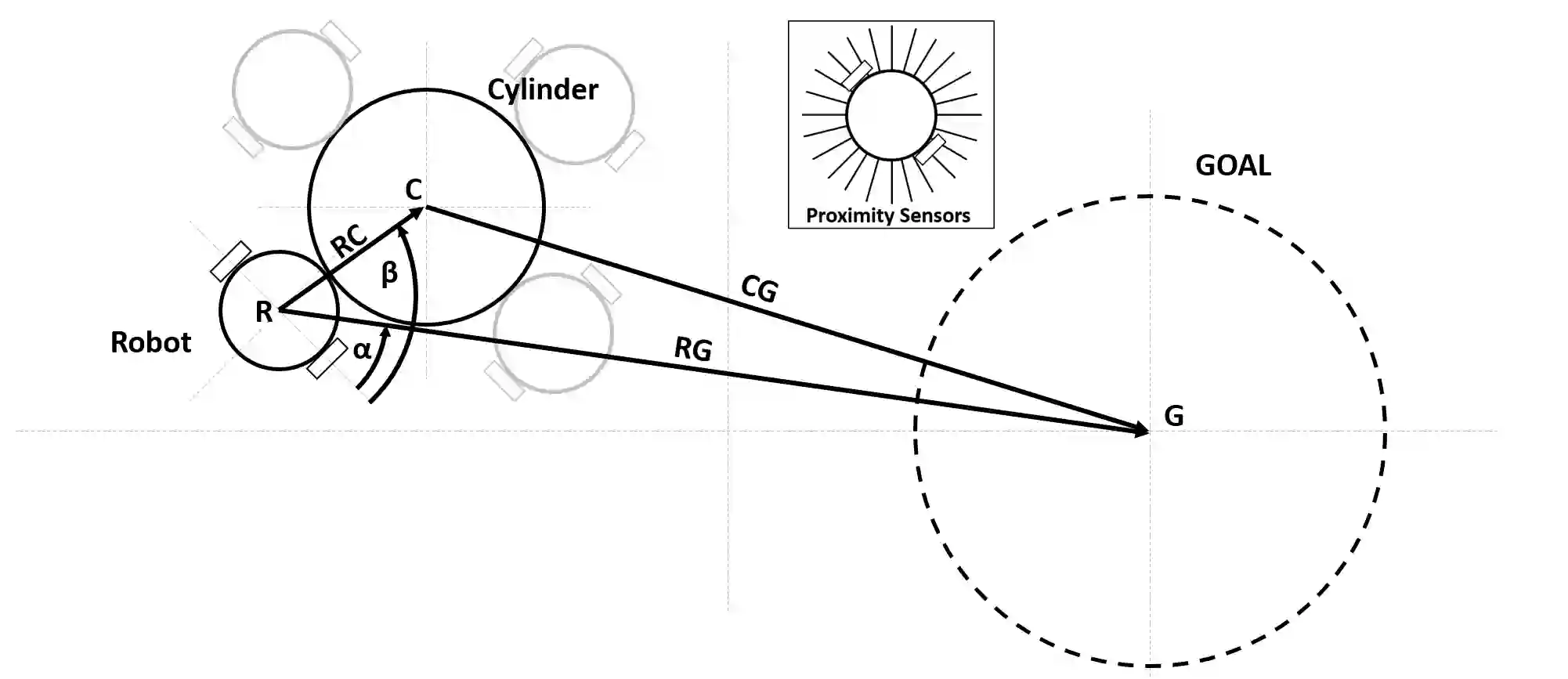
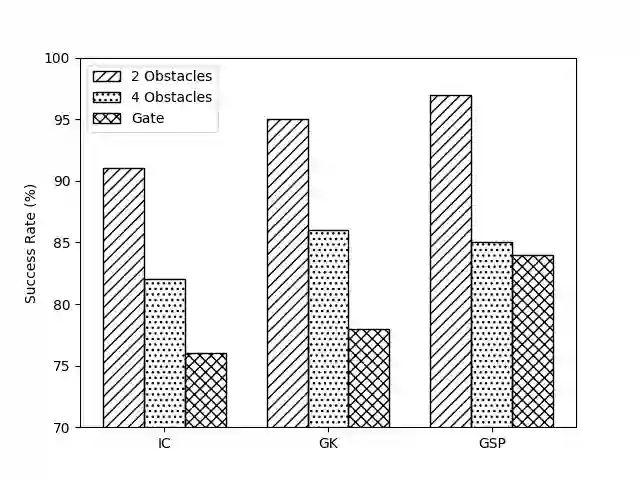
Deep reinforcement learning (DRL) has seen remarkable success in the control of single robots. However, applying DRL to robot swarms presents significant challenges. A critical challenge is non-stationarity, which occurs when two or more robots update individual or shared policies concurrently, thereby engaging in an interdependent training process with no guarantees of convergence. Circumventing non-stationarity typically involves training the robots with global information about other agents' states and/or actions. In contrast, in this paper we explore how to remove the need for global information. We pose our problem as a Partially Observable Markov Decision Process, due to the absence of global knowledge on other agents. Using collective transport as a testbed scenario, we study two approaches to multi-agent training. In the first, the robots exchange no messages, and are trained to rely on implicit communication through push-and-pull on the object to transport. In the second approach, we introduce Global State Prediction (GSP), a network trained to forma a belief over the swarm as a whole and predict its future states. We provide a comprehensive study over four well-known deep reinforcement learning algorithms in environments with obstacles, measuring performance as the successful transport of the object to the goal within a desired time-frame. Through an ablation study, we show that including GSP boosts performance and increases robustness when compared with methods that use global knowledge.
翻译:深度强化学习在单机器人控制领域已取得显著成功。然而,将其应用于机器人群体仍面临重大挑战。其中关键挑战是非平稳性问题:当两个或多个机器人同时更新个体或共享策略时,会形成相互依赖的训练过程且无法保证收敛。规避非平稳性的常见方法需要机器人获取其他智能体状态和/或动作的全局信息。与此相反,本文探索如何消除对全局信息的依赖。由于缺乏其他智能体的全局知识,我们将问题建模为部分可观测马尔可夫决策过程。以集体运输为测试场景,我们研究了两种多智能体训练方法:第一种方法中,机器人之间不交换任何信息,通过推拉运输物体产生的隐式通信进行训练;第二种方法引入全局状态预测网络——该网络训练形成对机器人集群的整体信念并预测其未来状态。我们在含障碍物环境中对四种经典深度强化学习算法展开全面研究,以规定时间内将物体成功运达目标为性能指标。通过消融实验证明,与使用全局知识的方法相比,引入全局状态预测能提升性能并增强鲁棒性。