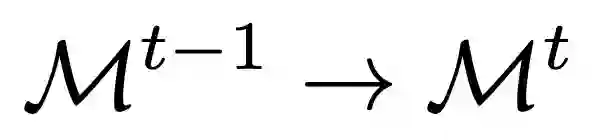Class-Incremental Learning (CIL) trains a model to continually recognize new classes from non-stationary data while retaining learned knowledge. A major challenge of CIL arises when applying to real-world data characterized by non-uniform distribution, which introduces a dual imbalance problem involving (i) disparities between stored exemplars of old tasks and new class data (inter-phase imbalance), and (ii) severe class imbalances within each individual task (intra-phase imbalance). We show that this dual imbalance issue causes skewed gradient updates with biased weights in FC layers, thus inducing over/under-fitting and catastrophic forgetting in CIL. Our method addresses it by reweighting the gradients towards balanced optimization and unbiased classifier learning. Additionally, we observe imbalanced forgetting where paradoxically the instance-rich classes suffer higher performance degradation during CIL due to a larger amount of training data becoming unavailable in subsequent learning phases. To tackle this, we further introduce a distribution-aware knowledge distillation loss to mitigate forgetting by aligning output logits proportionally with the distribution of lost training data. We validate our method on CIFAR-100, ImageNetSubset, and Food101 across various evaluation protocols and demonstrate consistent improvements compared to existing works, showing great potential to apply CIL in real-world scenarios with enhanced robustness and effectiveness.
翻译:类增量学习(CIL)旨在训练模型从非平稳数据中持续识别新类别,同时保留已学知识。当应用于以非均匀分布为特征的真实世界数据时,CIL面临一个重大挑战,即双重不平衡问题,包括:(i) 存储的旧任务样本与新类别数据之间的差异(阶段间不平衡),以及(ii) 每个单独任务内严重的类别不平衡(阶段内不平衡)。我们发现,这种双重不平衡问题会导致全连接层中因权重偏置而产生倾斜的梯度更新,从而引发CIL中的过拟合/欠拟合与灾难性遗忘。我们的方法通过重加权梯度实现均衡优化和无偏分类器学习来解决该问题。此外,我们观察到一种不平衡遗忘现象:由于后续学习阶段中大量训练数据变得不可用,样本丰富的类别在CIL中反而遭受更严重的性能下降。为解决此问题,我们进一步引入分布感知知识蒸馏损失,通过使输出logits与丢失训练数据的分布成比例对齐来缓解遗忘。我们在CIFAR-100、ImageNetSubset和Food101数据集上,采用多种评估协议验证了该方法,并展示了相较于现有工作的一致改进,表明该方法在真实场景中应用CIL时具有增强的鲁棒性和有效性。