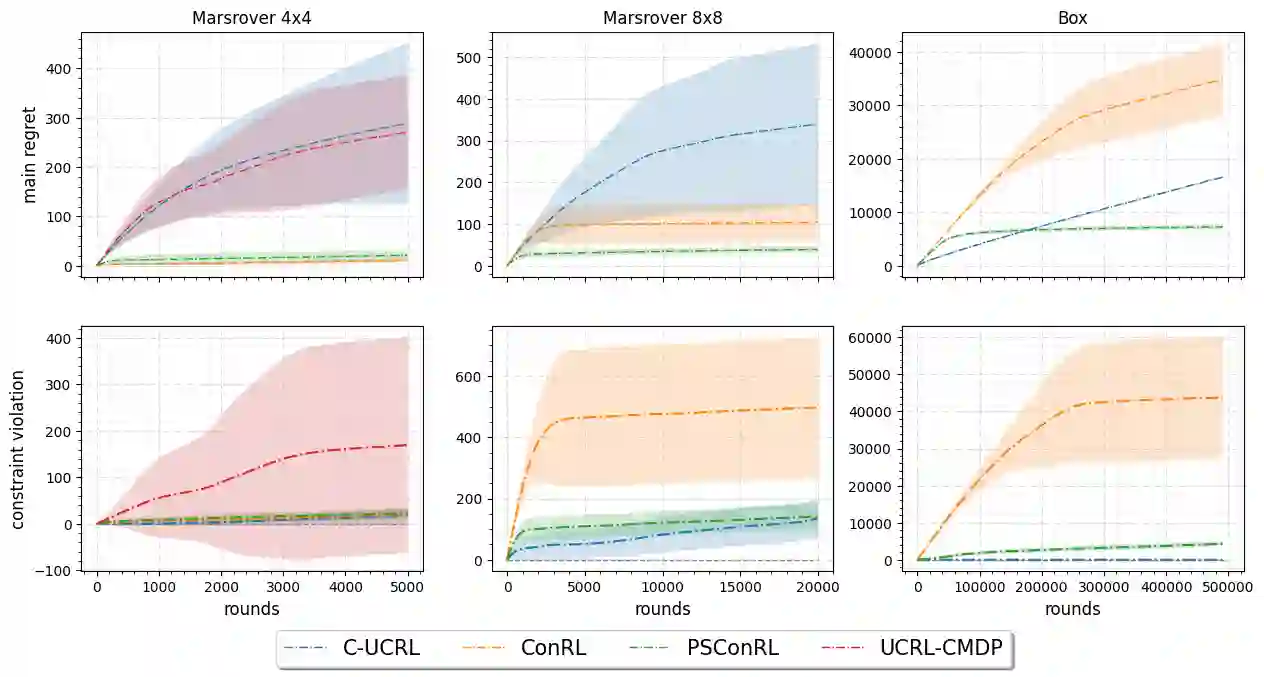
We present a new algorithm based on posterior sampling for learning in constrained Markov decision processes (CMDP) in the infinite-horizon undiscounted setting. The algorithm achieves near-optimal regret bounds while being advantageous empirically compared to the existing algorithms. Our main theoretical result is a Bayesian regret bound for each cost component of \tilde{O} (HS \sqrt{AT}) for any communicating CMDP with S states, A actions, and bound on the hitting time H. This regret bound matches the lower bound in order of time horizon T and is the best-known regret bound for communicating CMDPs in the infinite-horizon undiscounted setting. Empirical results show that, despite its simplicity, our posterior sampling algorithm outperforms the existing algorithms for constrained reinforcement learning.
翻译:我们提出了一种基于后验采样的新算法,用于在无限时域无折扣设置下的约束马尔可夫决策过程(CMDP)中进行学习。该算法在实现接近最优遗憾界的同时,相比现有算法在经验上具有优势。我们的主要理论结果是针对具有S个状态、A个动作、命中时间界H的可通信CMDP,每个成本分量的贝叶斯遗憾界为\tilde{O} (HS \sqrt{AT})。该遗憾界在时间跨度T的数量级上与下界匹配,是无限时域无折扣设置下可通信CMDP已知的最优遗憾界。实验结果表明,尽管算法设计简单,我们的后验采样算法在约束强化学习任务中优于现有算法。