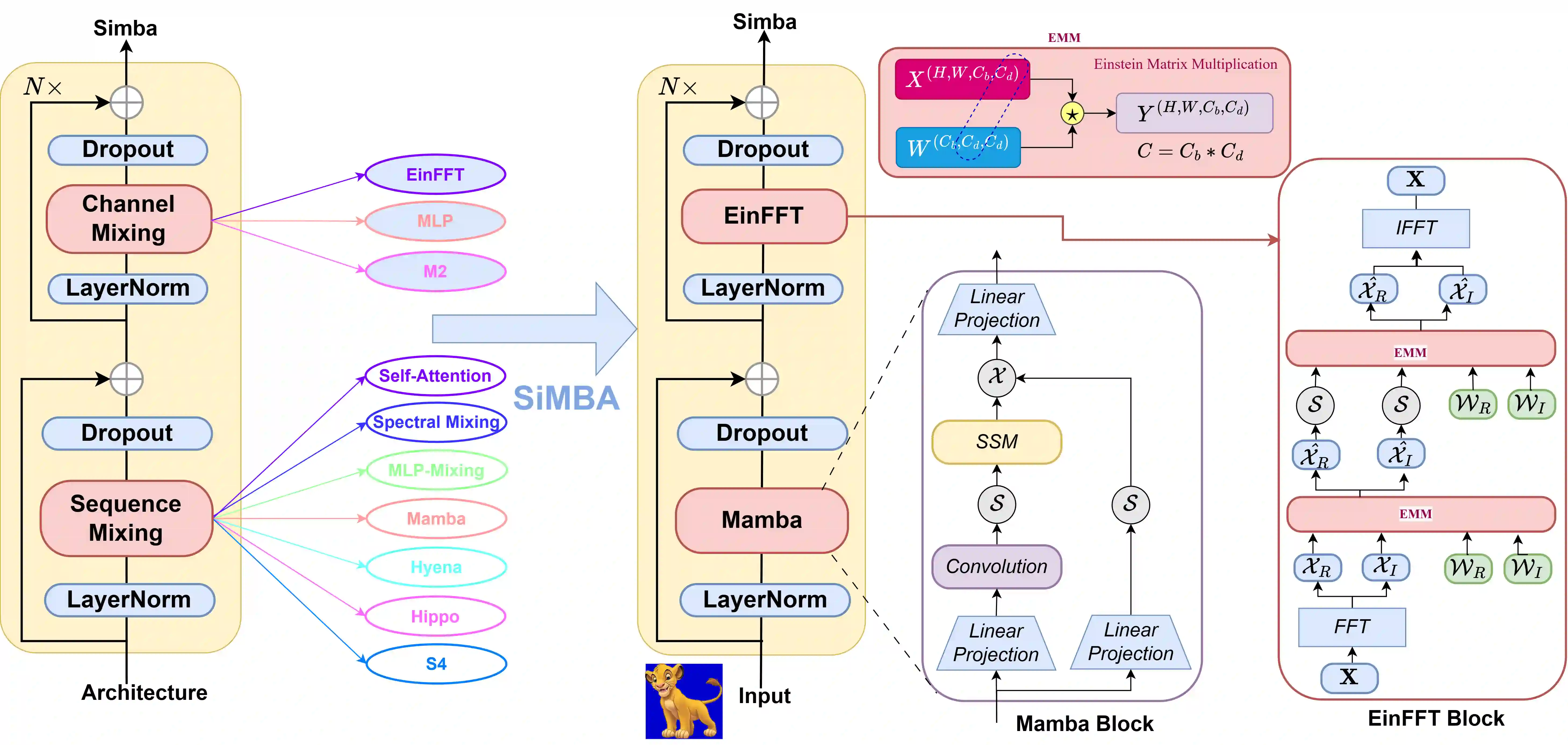
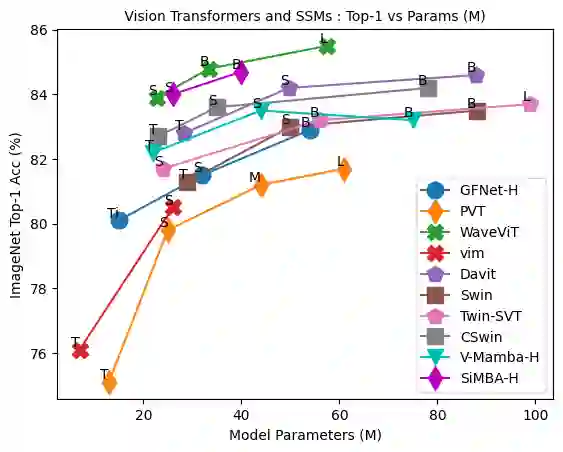
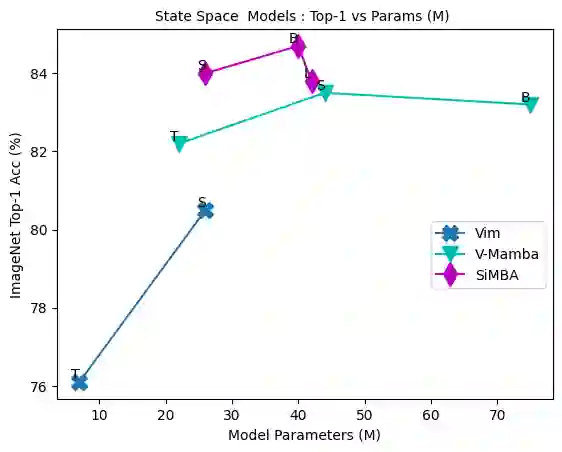
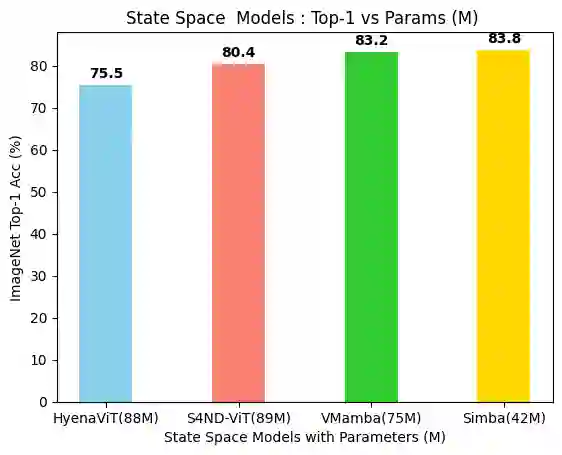
Transformers have widely adopted attention networks for sequence mixing and MLPs for channel mixing, playing a pivotal role in achieving breakthroughs across domains. However, recent literature highlights issues with attention networks, including low inductive bias and quadratic complexity concerning input sequence length. State Space Models (SSMs) like S4 and others (Hippo, Global Convolutions, liquid S4, LRU, Mega, and Mamba), have emerged to address the above issues to help handle longer sequence lengths. Mamba, while being the state-of-the-art SSM, has a stability issue when scaled to large networks for computer vision datasets. We propose SiMBA, a new architecture that introduces Einstein FFT (EinFFT) for channel modeling by specific eigenvalue computations and uses the Mamba block for sequence modeling. Extensive performance studies across image and time-series benchmarks demonstrate that SiMBA outperforms existing SSMs, bridging the performance gap with state-of-the-art transformers. Notably, SiMBA establishes itself as the new state-of-the-art SSM on ImageNet and transfer learning benchmarks such as Stanford Car and Flower as well as task learning benchmarks as well as seven time series benchmark datasets. The project page is available on this website ~\url{https://github.com/badripatro/Simba}.
翻译:Transformer广泛采用注意力网络进行序列混合、使用MLP进行通道混合,在不同领域取得突破性进展。然而近期文献揭示了注意力网络存在的问题,包括归纳偏置过低以及输入序列长度的二次复杂度。状态空间模型(如S4等模型,包括Hippo、全局卷积、液态S4、LRU、Mega及Mamba)应运而生,以应对上述问题并帮助处理更长序列长度。Mamba虽为目前最先进的状态空间模型,但在扩展到面向计算机视觉数据集的大型网络时存在稳定性问题。我们提出SiMBA新型架构,通过特定特征值计算引入爱因斯坦快速傅里叶变换(EinFFT)进行通道建模,并采用Mamba模块进行序列建模。在图像和时间序列基准上的大量性能研究表明,SiMBA性能优于现有状态空间模型,缩小了与最先进Transformer的性能差距。值得注意的是,SiMBA在ImageNet及Stanford Car、Flower等迁移学习基准、任务学习基准以及七个时间序列基准数据集上均确立了新的最先进状态空间模型地位。项目页面网址为:~\url{https://github.com/badripatro/Simba}。