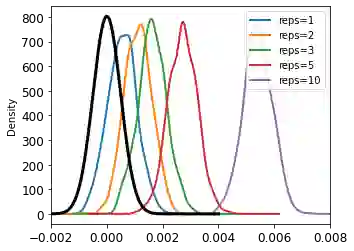
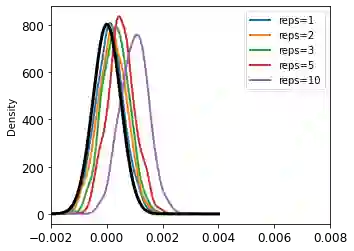
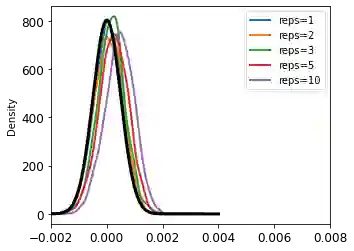
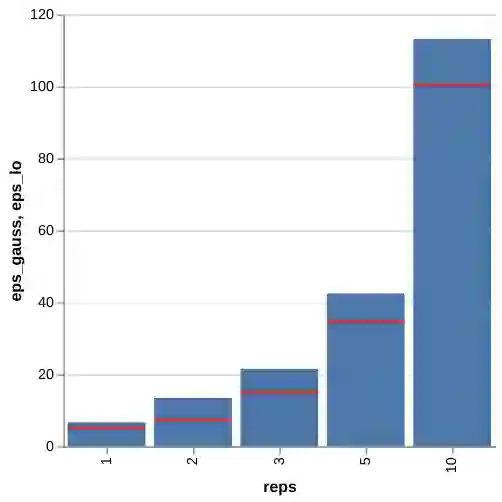
Privacy auditing techniques for differentially private (DP) algorithms are useful for estimating the privacy loss to compare against analytical bounds, or empirically measure privacy in settings where known analytical bounds on the DP loss are not tight. However, existing privacy auditing techniques usually make strong assumptions on the adversary (e.g., knowledge of intermediate model iterates or the training data distribution), are tailored to specific tasks and model architectures, and require retraining the model many times (typically on the order of thousands). These shortcomings make deploying such techniques at scale difficult in practice, especially in federated settings where model training can take days or weeks. In this work, we present a novel "one-shot" approach that can systematically address these challenges, allowing efficient auditing or estimation of the privacy loss of a model during the same, single training run used to fit model parameters. Our privacy auditing method for federated learning does not require a priori knowledge about the model architecture or task. We show that our method provides provably correct estimates for privacy loss under the Gaussian mechanism, and we demonstrate its performance on a well-established FL benchmark dataset under several adversarial models.
翻译:差分隐私算法的隐私审计技术对于估算隐私损失以对比已知分析界限,或在差分隐私损失的分析界限不严格的环境下实证测量隐私非常有用。然而,现有隐私审计技术通常对攻击者做出强假设(例如,已知中间模型迭代或训练数据分布),为特定任务和模型架构量身定制,并需要多次重新训练模型(通常达数千次)。这些缺陷使得此类技术在实践中难以大规模部署,尤其在模型训练可能耗时数天或数周的联邦环境中。本研究提出一种新颖的“一次性”方法,可系统应对这些挑战,使得在用于拟合模型参数的同一单次训练过程中高效审计或估算模型的隐私损失成为可能。我们的联邦学习隐私审计方法无需预先了解模型架构或任务。我们证明,该方法在高斯机制下能提供可证明正确的隐私损失估算,并在多个对抗模型下,基于一个成熟的联邦学习基准数据集展示了其性能。