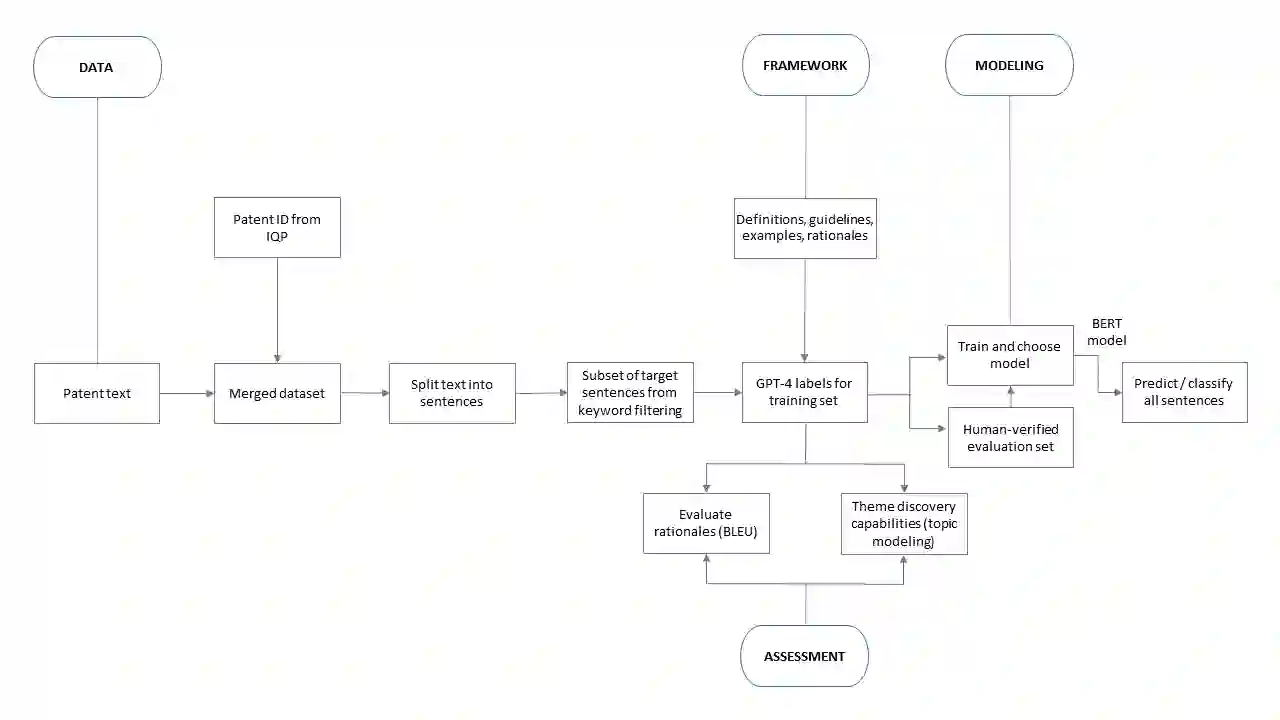
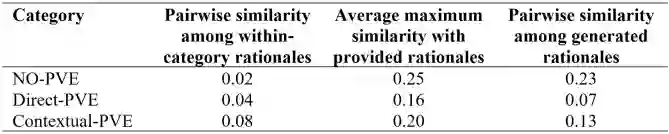
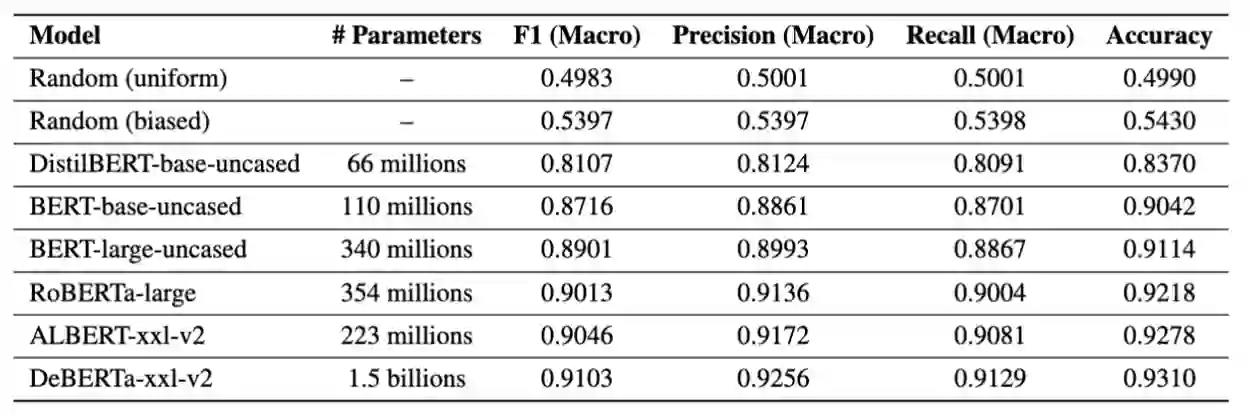
Labeling data is essential for training text classifiers but is often difficult to accomplish accurately, especially for complex and abstract concepts. Seeking an improved method, this paper employs a novel approach using a generative language model (GPT-4) to produce labels and rationales for large-scale text analysis. We apply this approach to the task of discovering public value expressions in US AI patents. We collect a database comprising 154,934 patent documents using an advanced Boolean query submitted to InnovationQ+. The results are merged with full patent text from the USPTO, resulting in 5.4 million sentences. We design a framework for identifying and labeling public value expressions in these AI patent sentences. A prompt for GPT-4 is developed which includes definitions, guidelines, examples, and rationales for text classification. We evaluate the quality of the labels and rationales produced by GPT-4 using BLEU scores and topic modeling and find that they are accurate, diverse, and faithful. These rationales also serve as a chain-of-thought for the model, a transparent mechanism for human verification, and support for human annotators to overcome cognitive limitations. We conclude that GPT-4 achieved a high-level of recognition of public value theory from our framework, which it also uses to discover unseen public value expressions. We use the labels produced by GPT-4 to train BERT-based classifiers and predict sentences on the entire database, achieving high F1 scores for the 3-class (0.85) and 2-class classification (0.91) tasks. We discuss the implications of our approach for conducting large-scale text analyses with complex and abstract concepts and suggest that, with careful framework design and interactive human oversight, generative language models can offer significant advantages in quality and in reduced time and costs for producing labels and rationales.
翻译:数据标注是训练文本分类器的关键步骤,但往往难以精确完成,尤其针对复杂抽象的概念。为探索更优方法,本文采用生成式语言模型(GPT-4)的创新方案,为大规模文本分析生成标签与理据。我们将此方法应用于美国AI专利中公共价值表述的发现任务。通过向InnovationQ+提交高级布尔检索,我们构建了包含154,934份专利文件的数据库,并与美国专利商标局(USPTO)的完整专利文本合并,最终获得540万条句子。针对这些AI专利句子,我们设计了识别与标注公共价值表述的框架,并开发了包含定义、指南、示例及文本分类理据的GPT-4提示词。通过BLEU评分与主题建模评估,GPT-4生成的标签与理据展现出准确性、多样性及忠实性。这些理据既作为模型的思维链(chain-of-thought),又为人工验证提供透明机制,同时支持标注人员突破认知局限。研究表明,GPT-4已从我们的框架中实现了对公共价值理论的高水平认知,并据此发现了未曾观察到的公共价值表述。我们利用GPT-4生成的标签训练基于BERT的分类器,对全量数据库进行句子预测,在三分类(0.85)与二分类(0.91)任务中均取得高F1得分。本文探讨了该方法在复杂抽象概念的大规模文本分析中的应用潜力,并指出在精心设计框架与人工交互监督下,生成式语言模型能够在标签与理据生成的质量、时效及成本方面展现出显著优势。