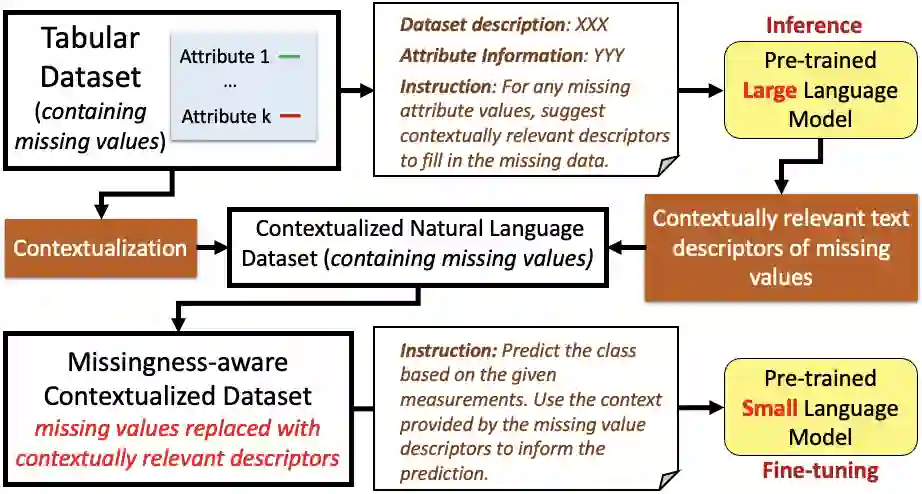
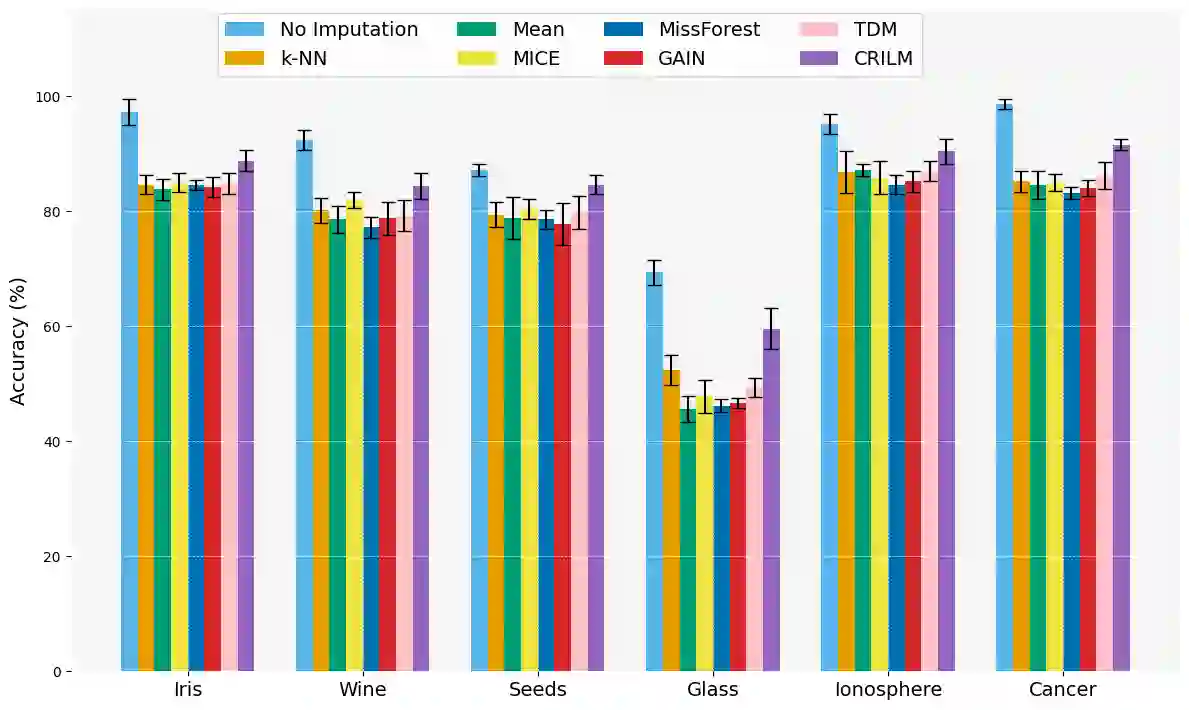
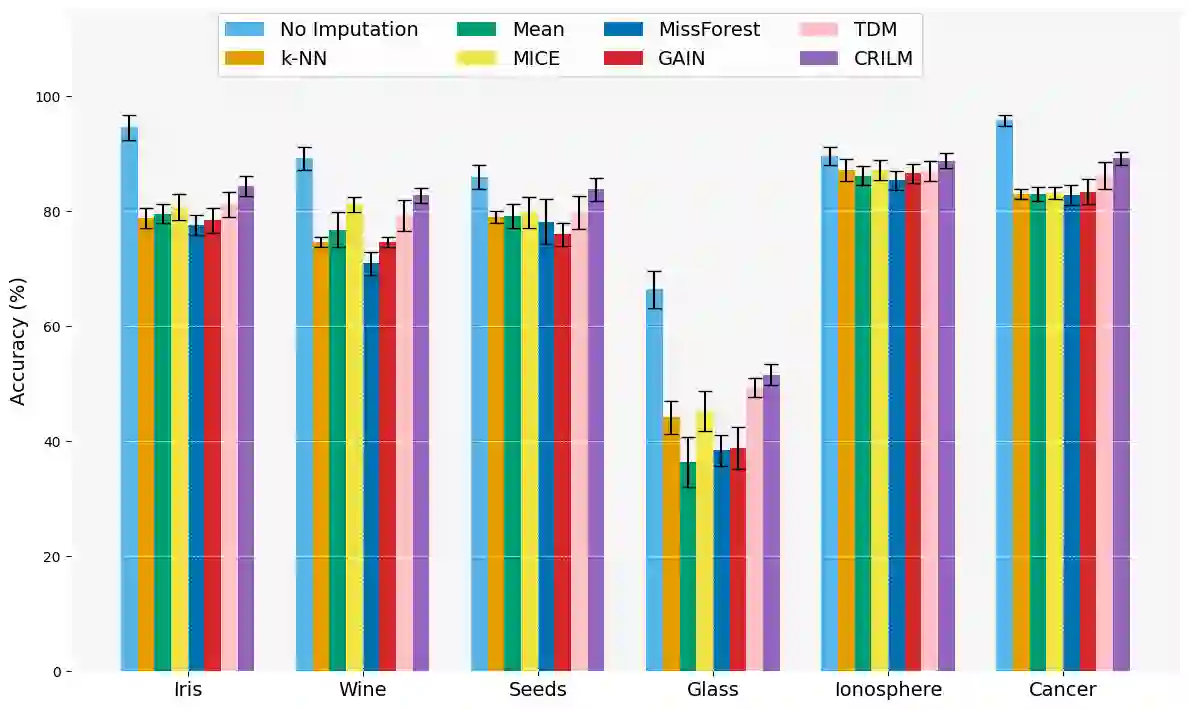
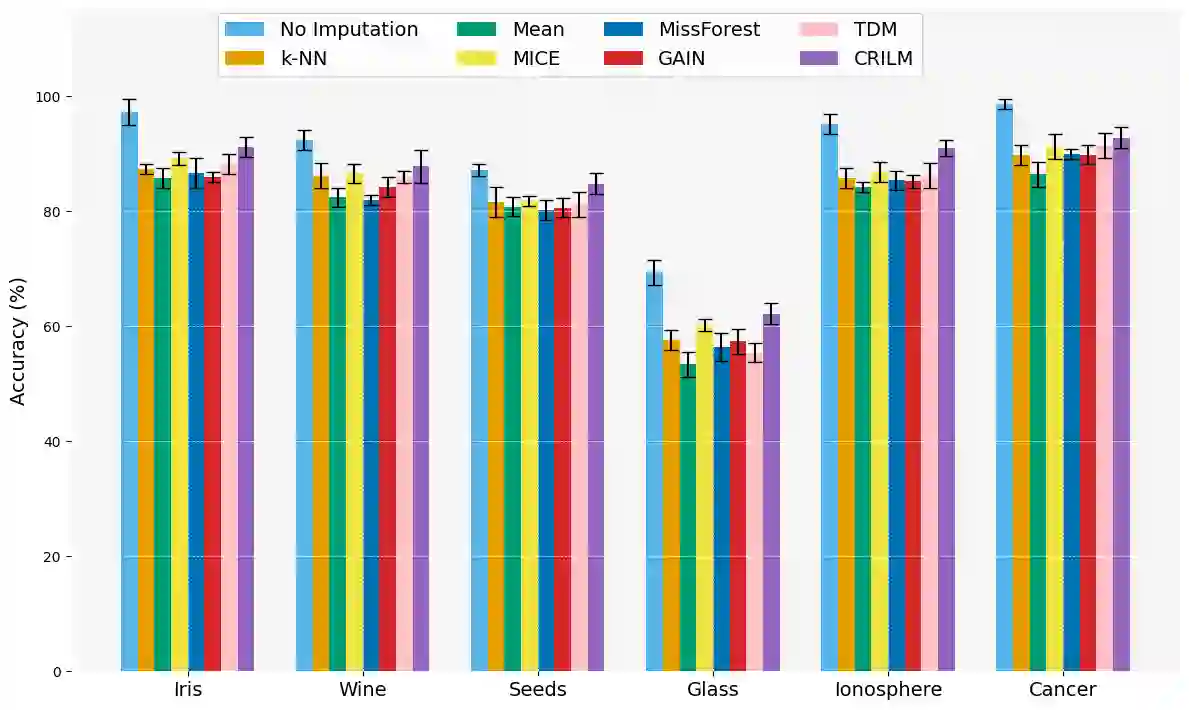
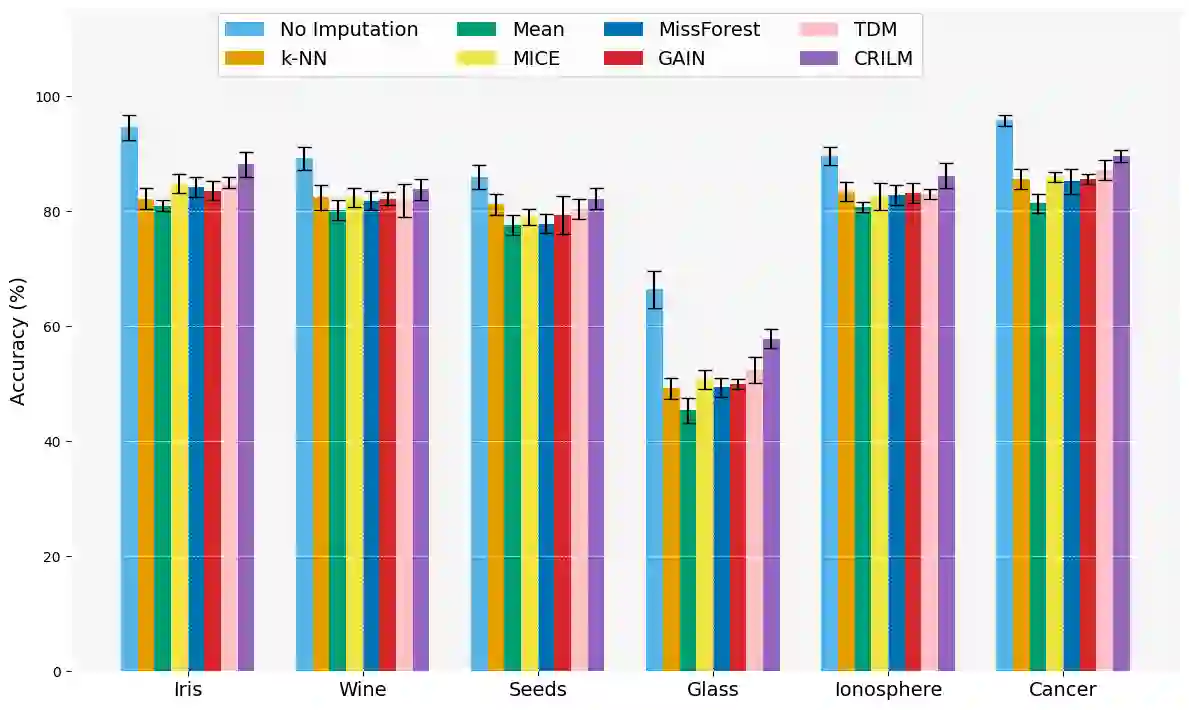
This paper presents a novel approach named \textbf{C}ontextually \textbf{R}elevant \textbf{I}mputation leveraging pre-trained \textbf{L}anguage \textbf{M}odels (\textbf{CRILM}) for handling missing data in tabular datasets. Instead of relying on traditional numerical estimations, CRILM uses pre-trained language models (LMs) to create contextually relevant descriptors for missing values. This method aligns datasets with LMs' strengths, allowing large LMs to generate these descriptors and small LMs to be fine-tuned on the enriched datasets for enhanced downstream task performance. Our evaluations demonstrate CRILM's superior performance and robustness across MCAR, MAR, and challenging MNAR scenarios, with up to a 10\% improvement over the best-performing baselines. By mitigating biases, particularly in MNAR settings, CRILM improves downstream task performance and offers a cost-effective solution for resource-constrained environments.
翻译:本文提出了一种名为**C**ontextually **R**elevant **I**mputation leveraging pre-trained **L**anguage **M**odels (**CRILM**)的新方法,用于处理表格数据集中的缺失数据。与传统数值估计方法不同,CRILM利用预训练语言模型为缺失值生成上下文相关的描述符。该方法使数据集与语言模型的优势对齐,允许大型语言模型生成这些描述符,而小型语言模型可在增强后的数据集上进行微调,从而提升下游任务性能。我们的评估表明,在MCAR、MAR及具有挑战性的MNAR场景下,CRILM均表现出卓越的性能和鲁棒性,相比最佳基线方法提升高达10%。通过减少偏差(尤其在MNAR设置中),CRILM不仅提升了下游任务性能,还为资源受限环境提供了经济高效的解决方案。