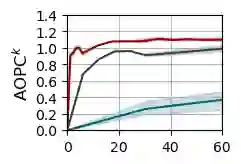
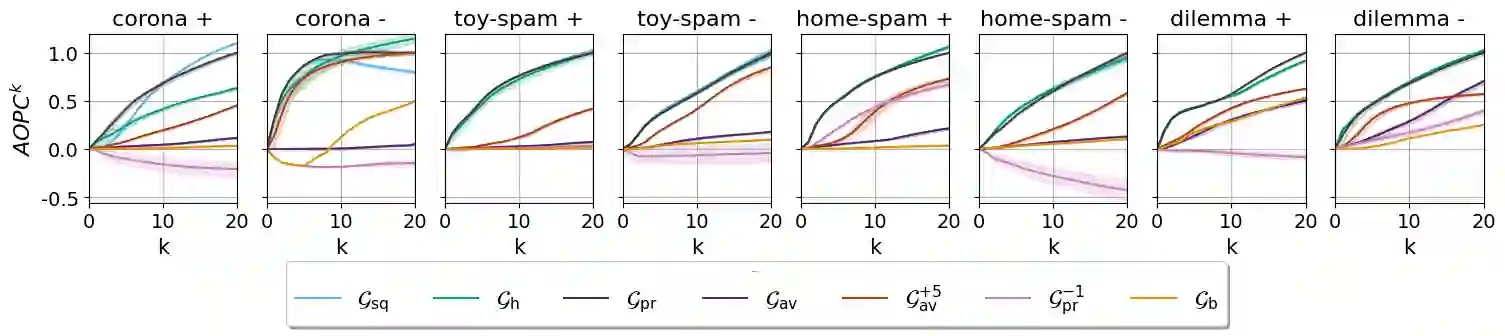
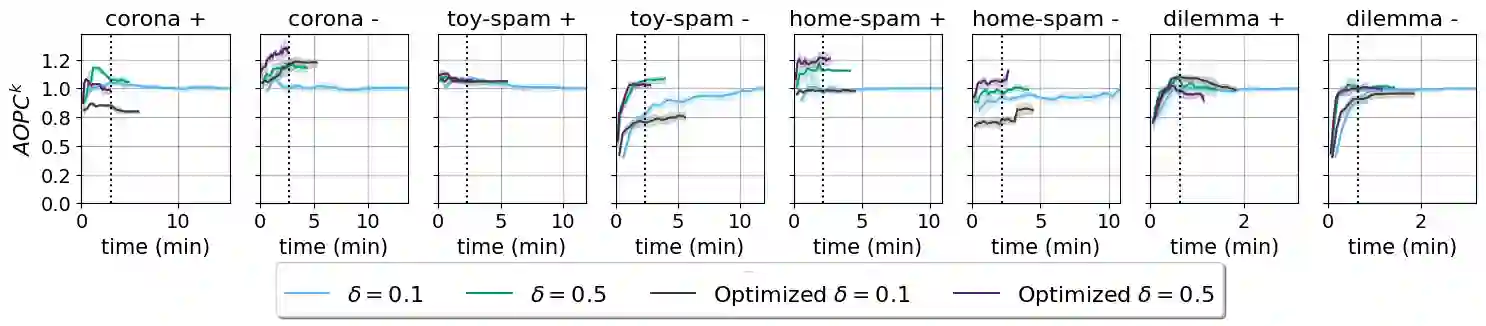
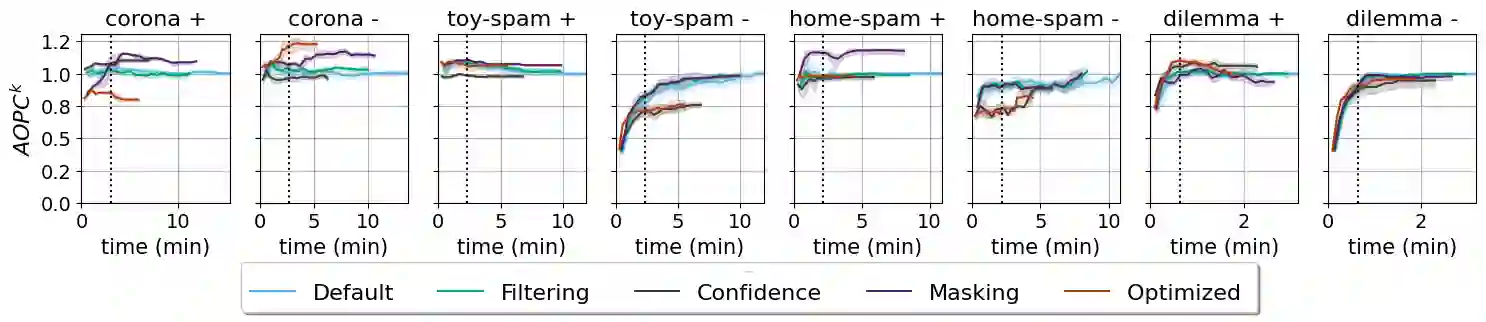
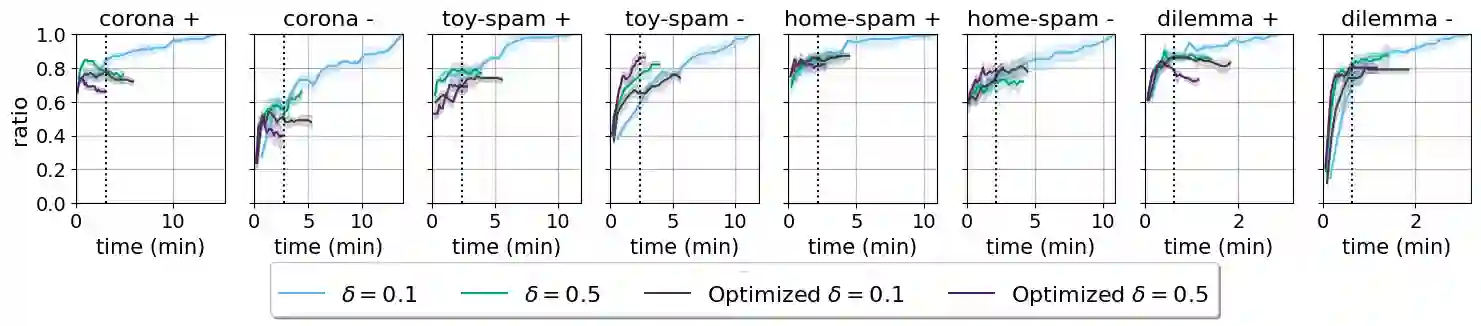
Local explanation methods highlight the input tokens that have a considerable impact on the outcome of classifying the document at hand. For example, the Anchor algorithm applies a statistical analysis of the sensitivity of the classifier to changes in the token. Aggregating local explanations over a dataset provides a global explanation of the model. Such aggregation aims to detect words with the most impact, giving valuable insights about the model, like what it has learned in training and which adversarial examples expose its weaknesses. However, standard aggregation methods bear a high computational cost: a na\"ive implementation applies a costly algorithm to each token of each document, and hence, it is infeasible for a simple user running in the scope of a short analysis session. % We devise techniques for accelerating the global aggregation of the Anchor algorithm. Specifically, our goal is to compute a set of top-$k$ words with the highest global impact according to different aggregation functions. Some of our techniques are lossless and some are lossy. We show that for a very mild loss of quality, we are able to accelerate the computation by up to 30$\times$, reducing the computation from hours to minutes. We also devise and study a probabilistic model that accounts for noise in the Anchor algorithm and diminishes the bias toward words that are frequent yet low in impact.
翻译:局部解释方法会突出显示对当前文档分类结果具有显著影响的输入标记。例如,Anchor算法通过对分类器对标记变化的敏感性进行统计分析来实现这一目的。将局部解释在数据集上进行聚合,可提供模型的全局解释。此类聚合旨在检测影响最大的词,洞悉模型特性,例如其在训练中学到的内容以及揭示其弱点的对抗样本。然而,标准聚合方法计算成本高昂:一种朴素的实现方式需要对每篇文档的每个标记运行昂贵的算法,因此对于在短时分析会话范围内运行的普通用户而言并不可行。我们设计了几种加速Anchor算法全局聚合的技术。具体而言,我们的目标是依据不同聚合函数计算具有最高全局影响力的top-k词集。部分技术是无损的,部分则是有损的。我们证明,在质量损失极小的情况下,计算速度可提升高达30倍,将计算时间从数小时缩短至数分钟。我们还设计并研究了一个概率模型,该模型考虑了Anchor算法中的噪声,并减少了对于频率高但影响力低的词的偏向。