
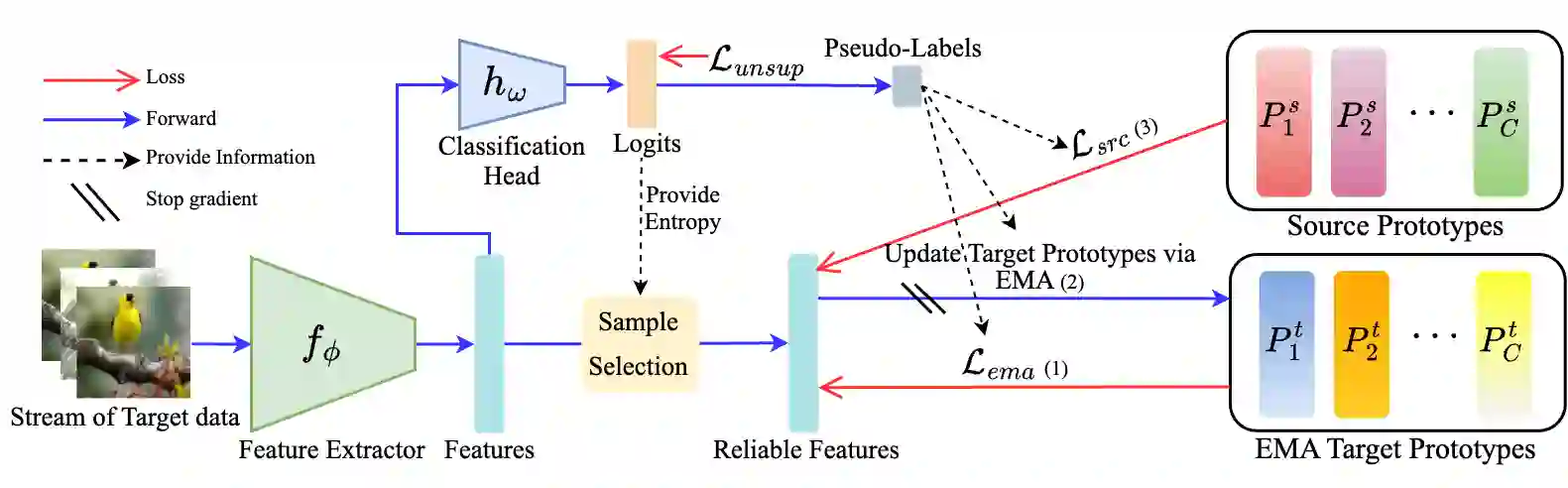
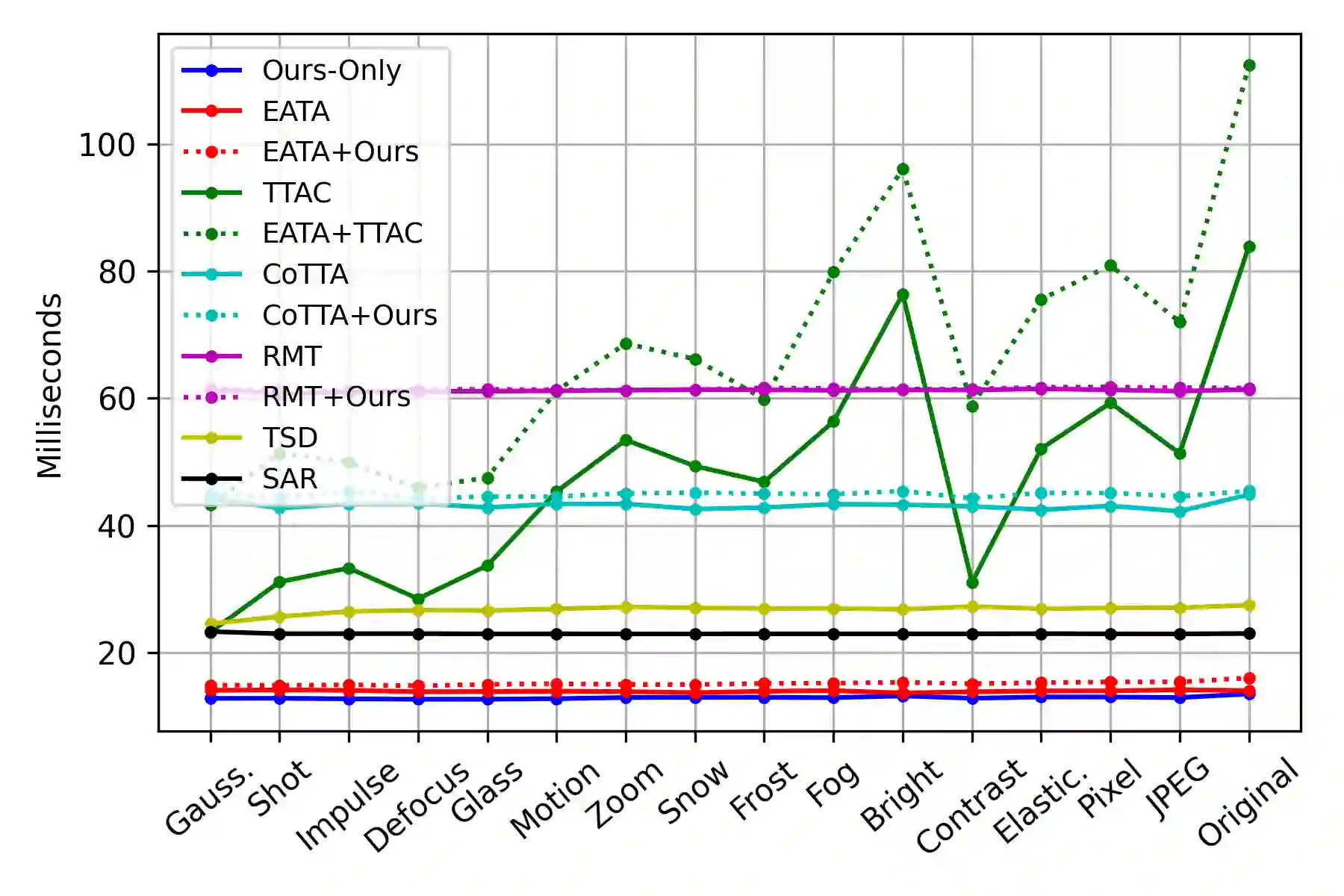
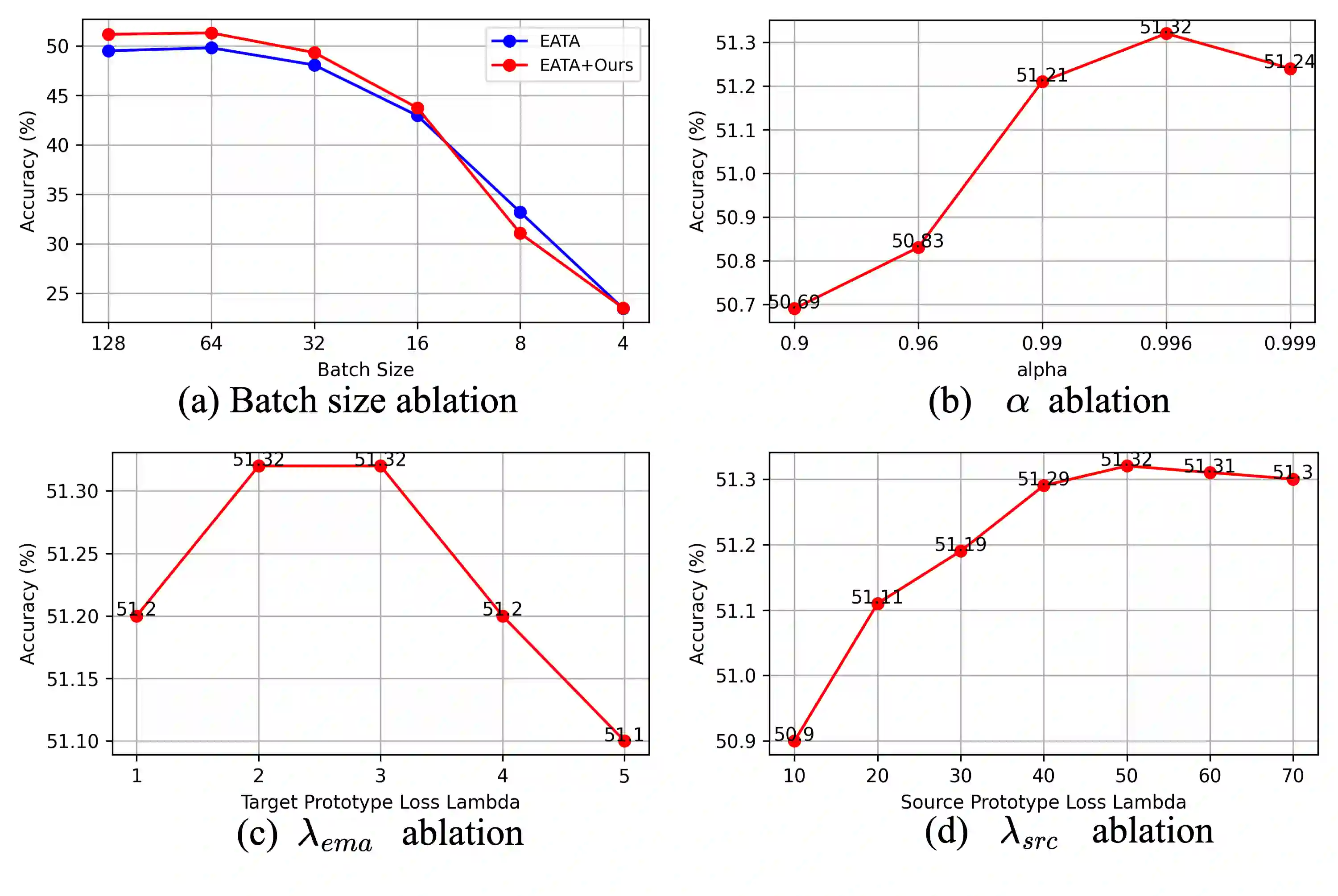
Continual Test-Time Adaptation (CTA) is a challenging task that aims to adapt a source pre-trained model to continually changing target domains. In the CTA setting, a model does not know when the target domain changes, thus facing a drastic change in the distribution of streaming inputs during the test-time. The key challenge is to keep adapting the model to the continually changing target domains in an online manner. We find that a model shows highly biased predictions as it constantly adapts to the chaining distribution of the target data. It predicts certain classes more often than other classes, making inaccurate over-confident predictions. This paper mitigates this issue to improve performance in the CTA scenario. To alleviate the bias issue, we make class-wise exponential moving average target prototypes with reliable target samples and exploit them to cluster the target features class-wisely. Moreover, we aim to align the target distributions to the source distribution by anchoring the target feature to its corresponding source prototype. With extensive experiments, our proposed method achieves noteworthy performance gain when applied on top of existing CTA methods without substantial adaptation time overhead.
翻译:持续测试时自适应(CTA)是一项具有挑战性的任务,旨在使源预训练模型适应持续变化的目标域。在CTA设定下,模型无法预知目标域何时发生变化,因此在测试阶段面临流式输入分布的剧烈变化。核心挑战在于以在线方式持续调整模型以应对不断变化的目标域。我们发现,随着模型持续适应目标数据的链式分布,其预测结果会呈现高度偏差——某些类别的预测频率显著高于其他类别,从而导致不准确且过度自信的预测。本文旨在缓解该问题以提升CTA场景下的性能。为减轻偏差问题,我们基于可靠的目标样本构建类别级指数移动平均目标原型,并利用这些原型对目标特征进行类别级聚类。此外,我们通过将目标特征锚定至对应的源原型,使目标分布与源分布对齐。大量实验表明,在现有CTA方法基础上应用我们的方法后,能在不显著增加自适应时间开销的前提下实现显著的性能提升。


相关内容

Source: Apple - iOS 8


