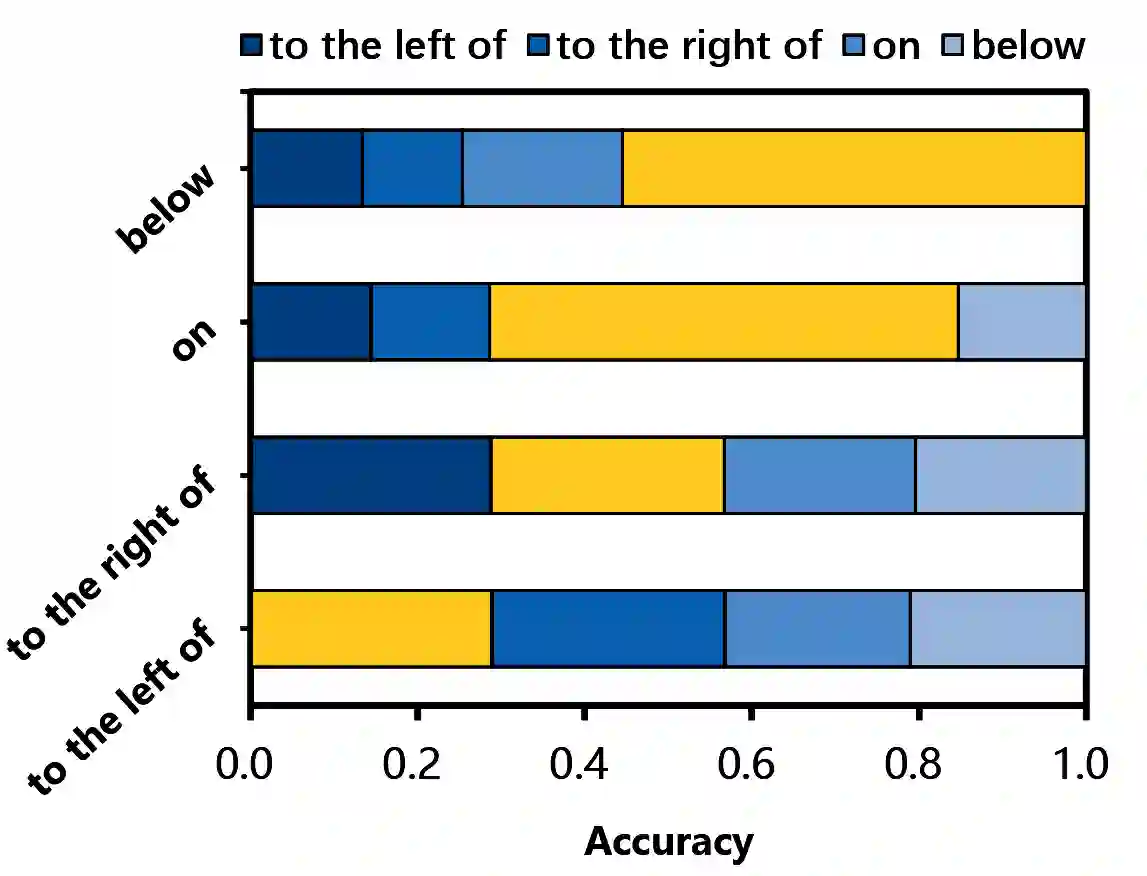
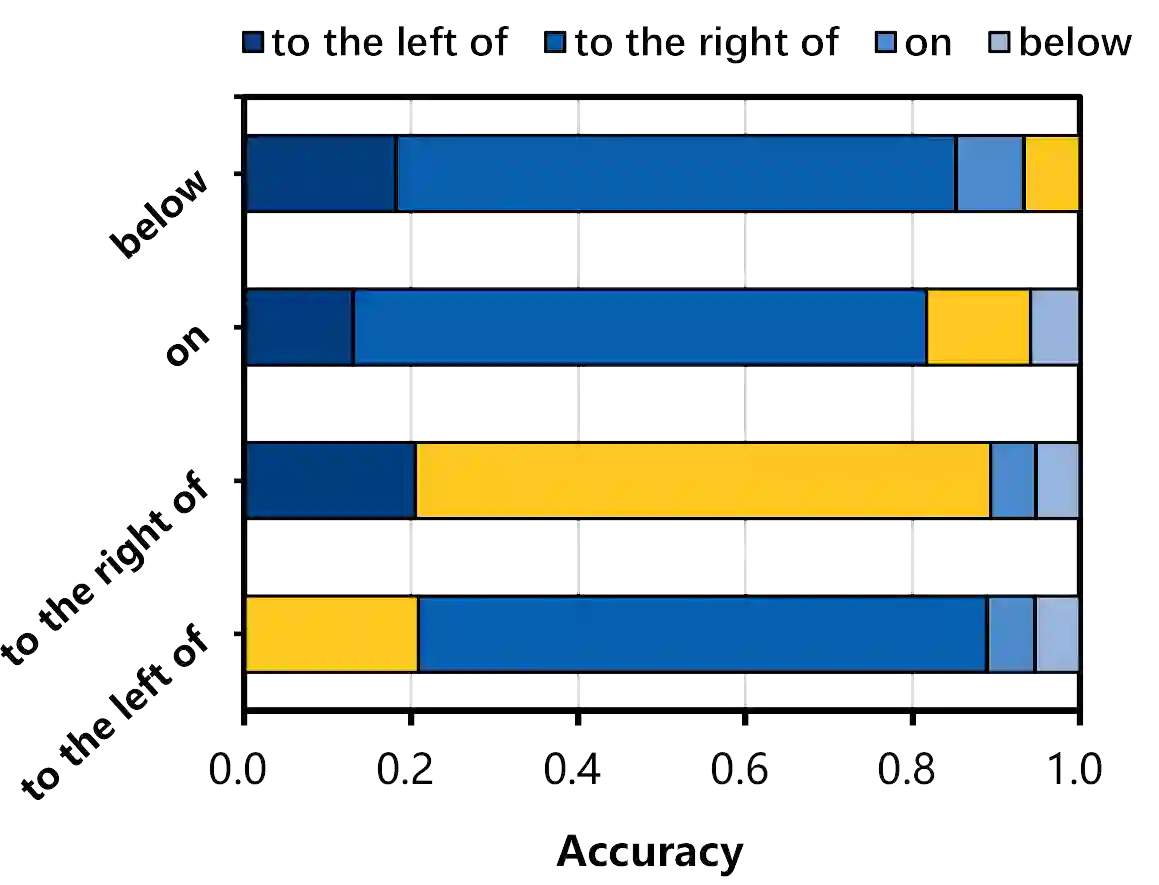
The multimedia community has shown a significant interest in perceiving and representing the physical world with multimodal pretrained neural network models, and among them, the visual-language pertaining (VLP) is, currently, the most captivating topic. However, there have been few endeavors dedicated to the exploration of 1) whether essential linguistic knowledge (e.g., semantics and syntax) can be extracted during VLP, and 2) how such linguistic knowledge impact or enhance the multimodal alignment. In response, here we aim to elucidate the impact of comprehensive linguistic knowledge, including semantic expression and syntactic structure, on multimodal alignment. Specifically, we design and release the SNARE, the first large-scale multimodal alignment probing benchmark, to detect the vital linguistic components, e.g., lexical, semantic, and syntax knowledge, containing four tasks: Semantic structure, Negation logic, Attribute ownership, and Relationship composition. Based on our proposed probing benchmarks, our holistic analyses of five advanced VLP models illustrate that the VLP model: i) shows insensitivity towards complex syntax structures and relies on content words for sentence comprehension; ii) demonstrates limited comprehension of combinations between sentences and negations; iii) faces challenges in determining the presence of actions or spatial relationships within visual information and struggles with verifying the correctness of triple combinations. We make our benchmark and code available at \url{https://github.com/WangFei-2019/SNARE/}.
翻译:多媒体社区对利用多模态预训练神经网络模型感知和表示物理世界表现出浓厚兴趣,其中视觉-语言预训练(VLP)是目前最引人注目的研究方向。然而,鲜有研究探索以下两个关键问题:1)在VLP过程中能否提取核心语言知识(如语义和句法);2)此类语言知识如何影响或增强多模态对齐。为此,本文旨在阐明包括语义表达和句法结构在内的综合语言知识对多模态对齐的影响。具体地,我们设计并发布了SNARE——首个大规模多模态对齐探测基准,用于检测词汇、语义、句法等关键语言成分,包含四项任务:语义结构、否定逻辑、属性归属与关系组合。基于所提出的探测基准,我们对五种先进VLP模型的全面分析表明,VLP模型:i)对复杂句法结构不敏感,依赖实义词理解句子;ii)对句子与否定组合的理解有限;iii)在判定视觉信息中动作或空间关系的存在性方面面临挑战,且难以验证三元组组合的正确性。我们的基准与代码开源于:\url{https://github.com/WangFei-2019/SNARE/}。