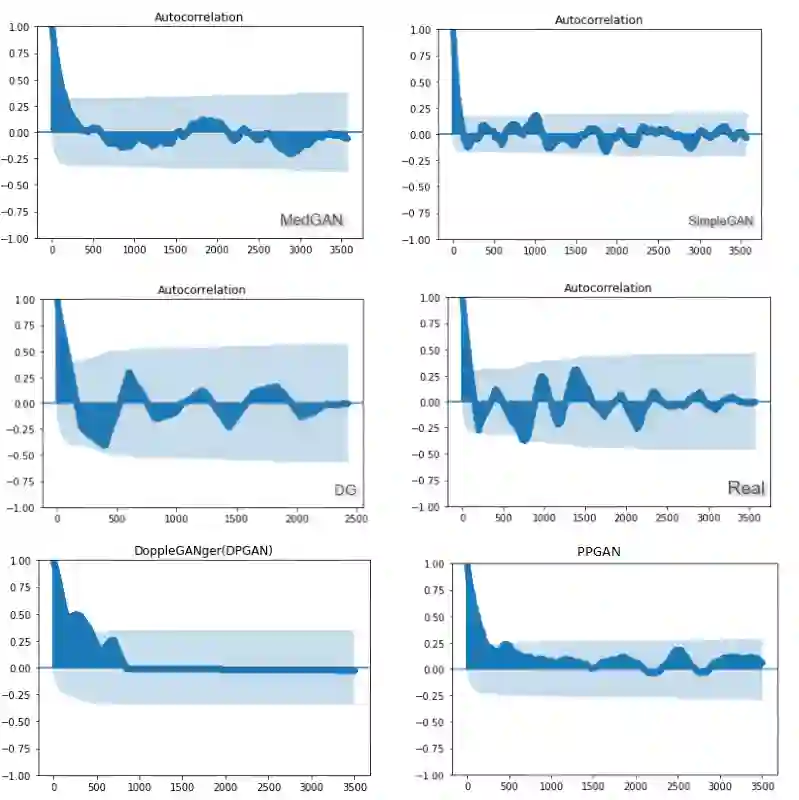
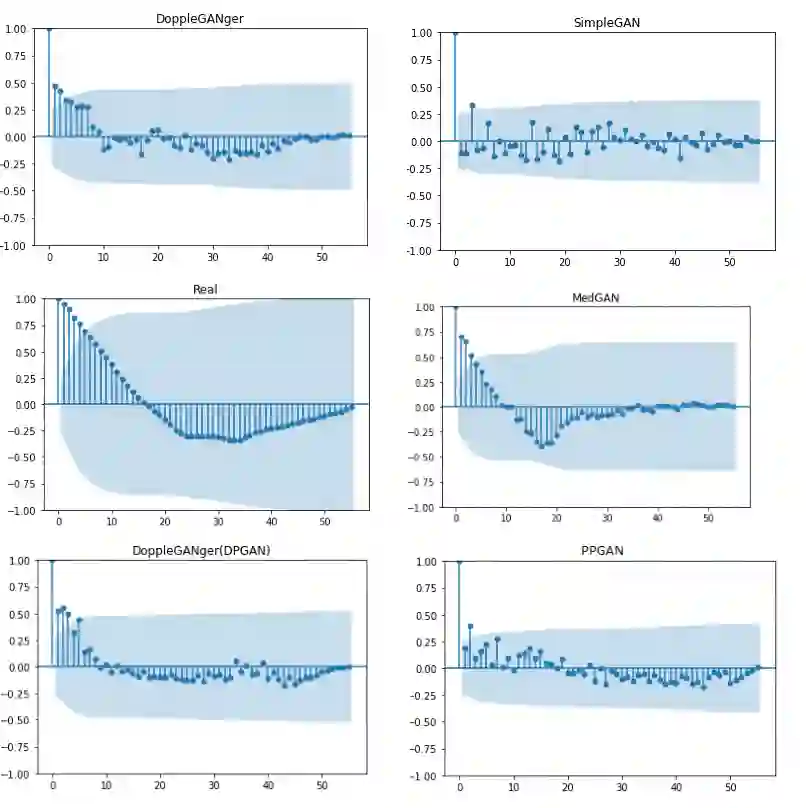
Preservation of private user data is of paramount importance for high Quality of Experience (QoE) and acceptability, particularly with services treating sensitive data, such as IT-based health services. Whereas anonymization techniques were shown to be prone to data re-identification, synthetic data generation has gradually replaced anonymization since it is relatively less time and resource-consuming and more robust to data leakage. Generative Adversarial Networks (GANs) have been used for generating synthetic datasets, especially GAN frameworks adhering to the differential privacy phenomena. This research compares state-of-the-art GAN-based models for synthetic data generation to generate time-series synthetic medical records of dementia patients which can be distributed without privacy concerns. Predictive modeling, autocorrelation, and distribution analysis are used to assess the Quality of Generating (QoG) of the generated data. The privacy preservation of the respective models is assessed by applying membership inference attacks to determine potential data leakage risks. Our experiments indicate the superiority of the privacy-preserving GAN (PPGAN) model over other models regarding privacy preservation while maintaining an acceptable level of QoG. The presented results can support better data protection for medical use cases in the future.
翻译:用户私人数据的保护对于高体验质量和可接受性至关重要,尤其是在处理敏感数据的服务(如基于信息技术的健康服务)中。虽然匿名化技术已被证明容易导致数据重识别,但合成数据生成由于相对较少的时间和资源消耗以及对数据泄露的更强鲁棒性,已逐渐取代匿名化。生成对抗网络已被用于生成合成数据集,尤其是符合差分隐私现象的生成对抗网络框架。本研究比较了基于生成对抗网络的最先进模型,用于生成痴呆症患者的时间序列合成医疗记录,这些记录可以不受隐私问题困扰地分发。通过预测建模、自相关性和分布分析来评估生成数据的生成质量。通过应用成员推断攻击来评估各模型的隐私保护能力,以确定潜在的数据泄露风险。我们的实验表明,隐私保护生成对抗网络模型在隐私保护方面优于其他模型,同时保持可接受的生成质量水平。所呈现的结果未来可支持医疗用例中更好的数据保护。