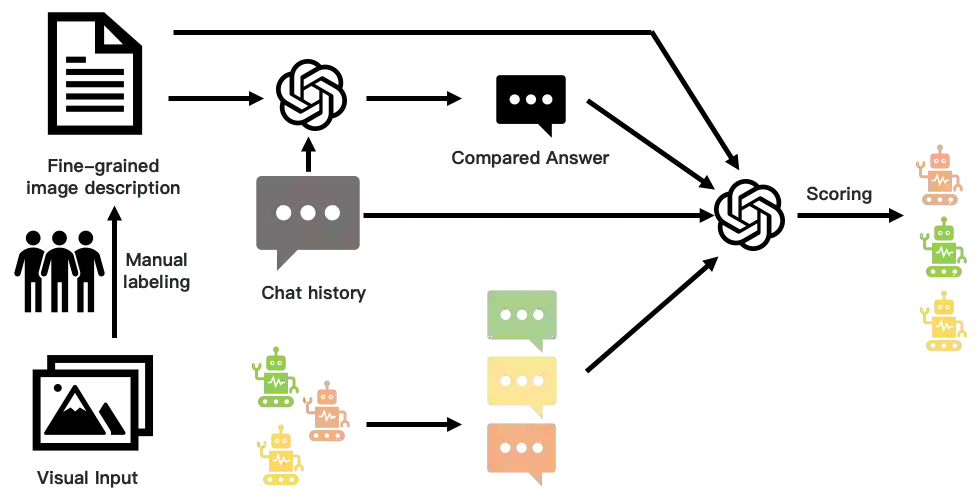
Large vision-language models (LVLMs) have recently witnessed rapid advancements, exhibiting a remarkable capacity for perceiving, understanding, and processing visual information by connecting visual receptor with large language models (LLMs). However, current assessments mainly focus on recognizing and reasoning abilities, lacking direct evaluation of conversational skills and neglecting visual storytelling abilities. In this paper, we propose an evaluation method that uses strong LLMs as judges to comprehensively evaluate the various abilities of LVLMs. Firstly, we construct a comprehensive visual dialogue dataset TouchStone, consisting of open-world images and questions, covering five major categories of abilities and 27 subtasks. This dataset not only covers fundamental recognition and comprehension but also extends to literary creation. Secondly, by integrating detailed image annotations we effectively transform the multimodal input content into a form understandable by LLMs. This enables us to employ advanced LLMs for directly evaluating the quality of the multimodal dialogue without requiring human intervention. Through validation, we demonstrate that powerful LVLMs, such as GPT-4, can effectively score dialogue quality by leveraging their textual capabilities alone, aligning with human preferences. We hope our work can serve as a touchstone for LVLMs' evaluation and pave the way for building stronger LVLMs. The evaluation code is available at https://github.com/OFA-Sys/TouchStone.
翻译:大型视觉-语言模型(LVLMs)近期取得了快速发展,通过将视觉感受器与大型语言模型(LLMs)相连接,展现出感知、理解和处理视觉信息的卓越能力。然而,当前的评估主要聚焦于识别与推理能力,缺乏对对话技能的直接评估,且忽略了视觉叙事能力。本文提出一种评估方法,利用强大的LLMs作为评判者,全面评估LVLMs的各项能力。首先,我们构建了一个全面的视觉对话数据集TouchStone,包含开放世界图像与问题,覆盖五大类能力及27项子任务。该数据集不仅涵盖基础识别与理解能力,还延伸至文学创作领域。其次,通过整合详细的图像标注,我们有效将多模态输入内容转化为LLMs可理解的形式。这使得我们能够利用先进的LLMs直接评估多模态对话质量,无需人工干预。通过验证,我们证明了GPT-4等强大的LVLMs能仅凭文本能力有效评分对话质量,且与人类偏好一致。希望我们的工作能成为LVLMs评估的试金石,并为构建更强大的LVLMs铺平道路。评估代码已开源至https://github.com/OFA-Sys/TouchStone。