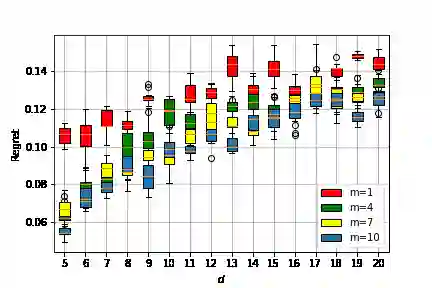
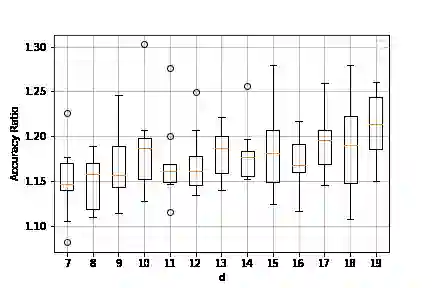
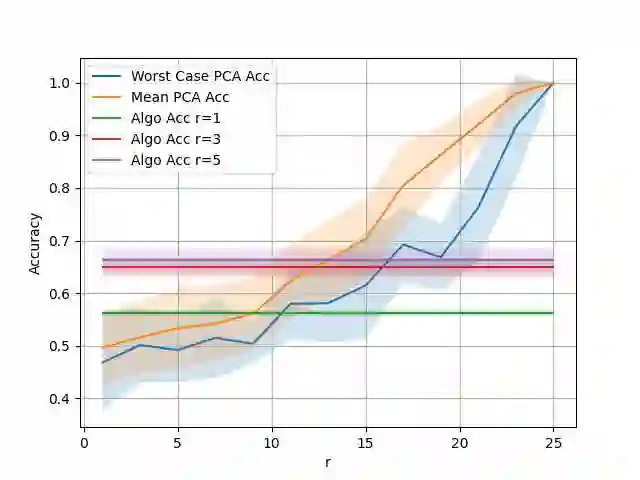
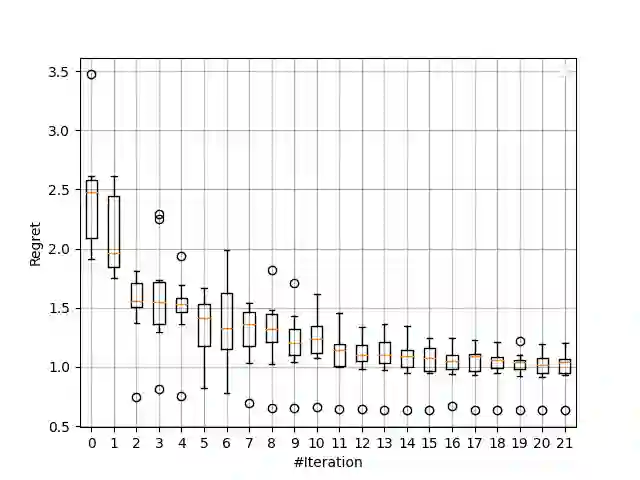
We propose a game-based formulation for learning dimensionality-reducing representations of feature vectors, when only a prior knowledge on future prediction tasks is available. In this game, the first player chooses a representation, and then the second player adversarially chooses a prediction task from a given class, representing the prior knowledge. The first player aims is to minimize, and the second player to maximize, the regret: The minimal prediction loss using the representation, compared to the same loss using the original features. For the canonical setting in which the representation, the response to predict and the predictors are all linear functions, and under the mean squared error loss function, we derive the theoretically optimal representation in pure strategies, which shows the effectiveness of the prior knowledge, and the optimal regret in mixed strategies, which shows the usefulness of randomizing the representation. For general representations and loss functions, we propose an efficient algorithm to optimize a randomized representation. The algorithm only requires the gradients of the loss function, and is based on incrementally adding a representation rule to a mixture of such rules.
翻译:我们提出了一种基于博弈论的形式化方法,用于在仅具备未来预测任务的先验知识时,学习特征向量的降维表征。在该博弈中,第一位玩家选择表征,随后第二位玩家从给定类别中对抗性地选择一个预测任务(该类别代表先验知识)。第一位玩家的目标是极小化遗憾值,而第二位玩家则试图极大化该值:遗憾值定义为使用表征时的最小预测损失与使用原始特征时的相同损失之间的差值。对于表征、待预测响应及预测器均为线性函数且采用均方误差损失函数的经典设定,我们推导了纯策略下的理论最优表征(该结果展示了先验知识的有效性)以及混合策略下的最优遗憾值(揭示了随机化表征的实用性)。针对一般化表征与损失函数,我们提出了一种高效算法来优化随机化表征。该算法仅需损失函数的梯度,并基于逐步向规则混合体中添加表征规则的方式实现。