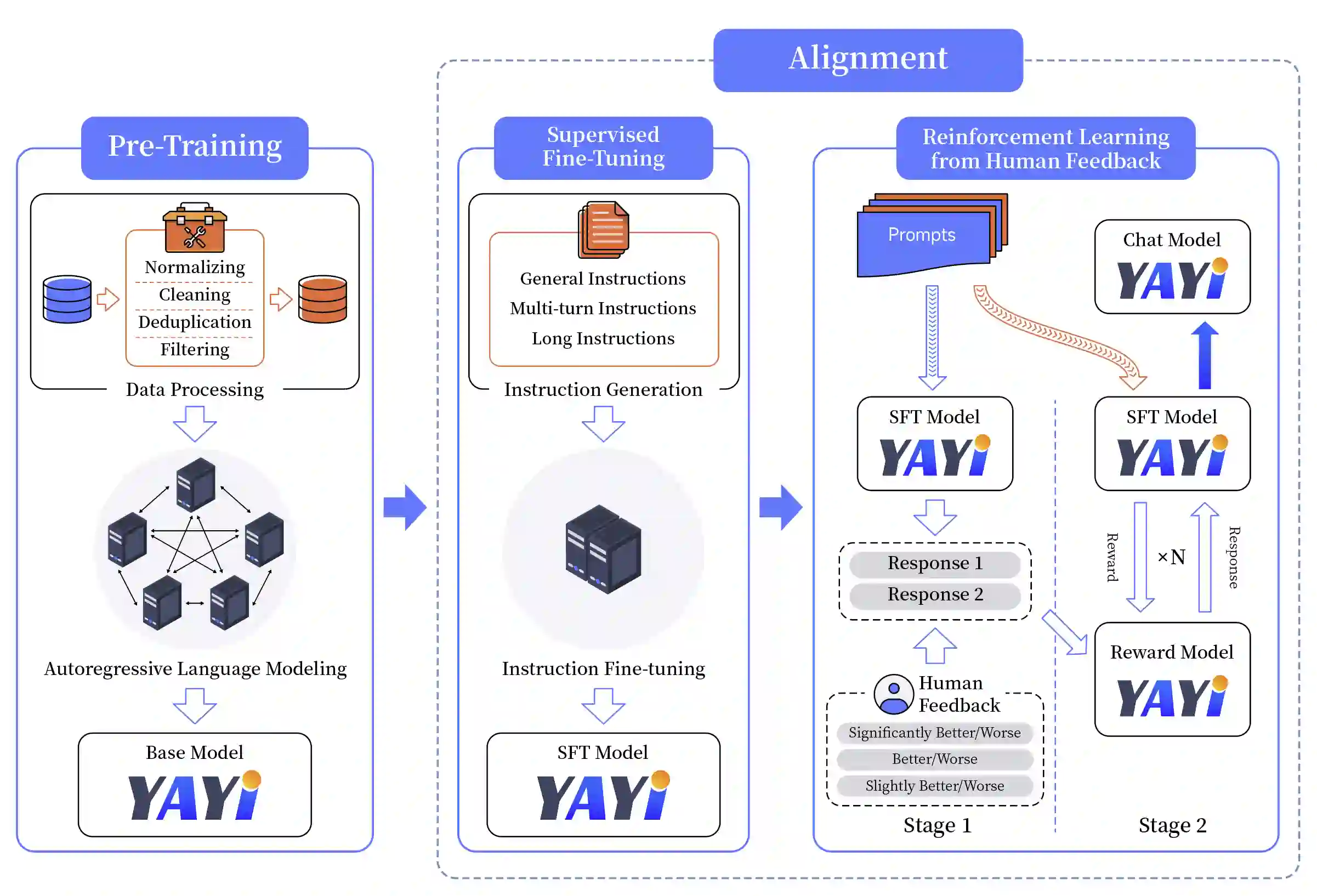
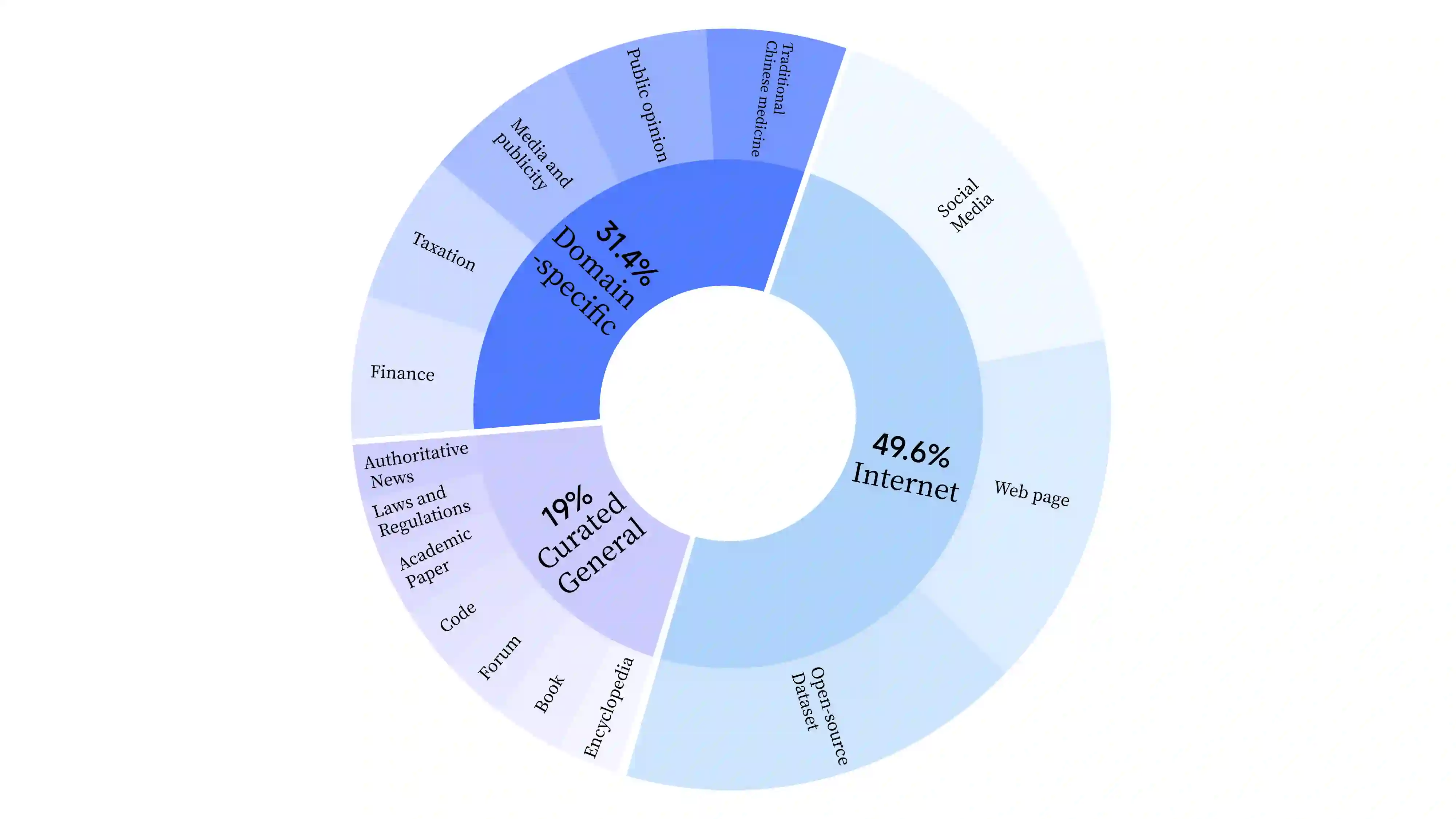
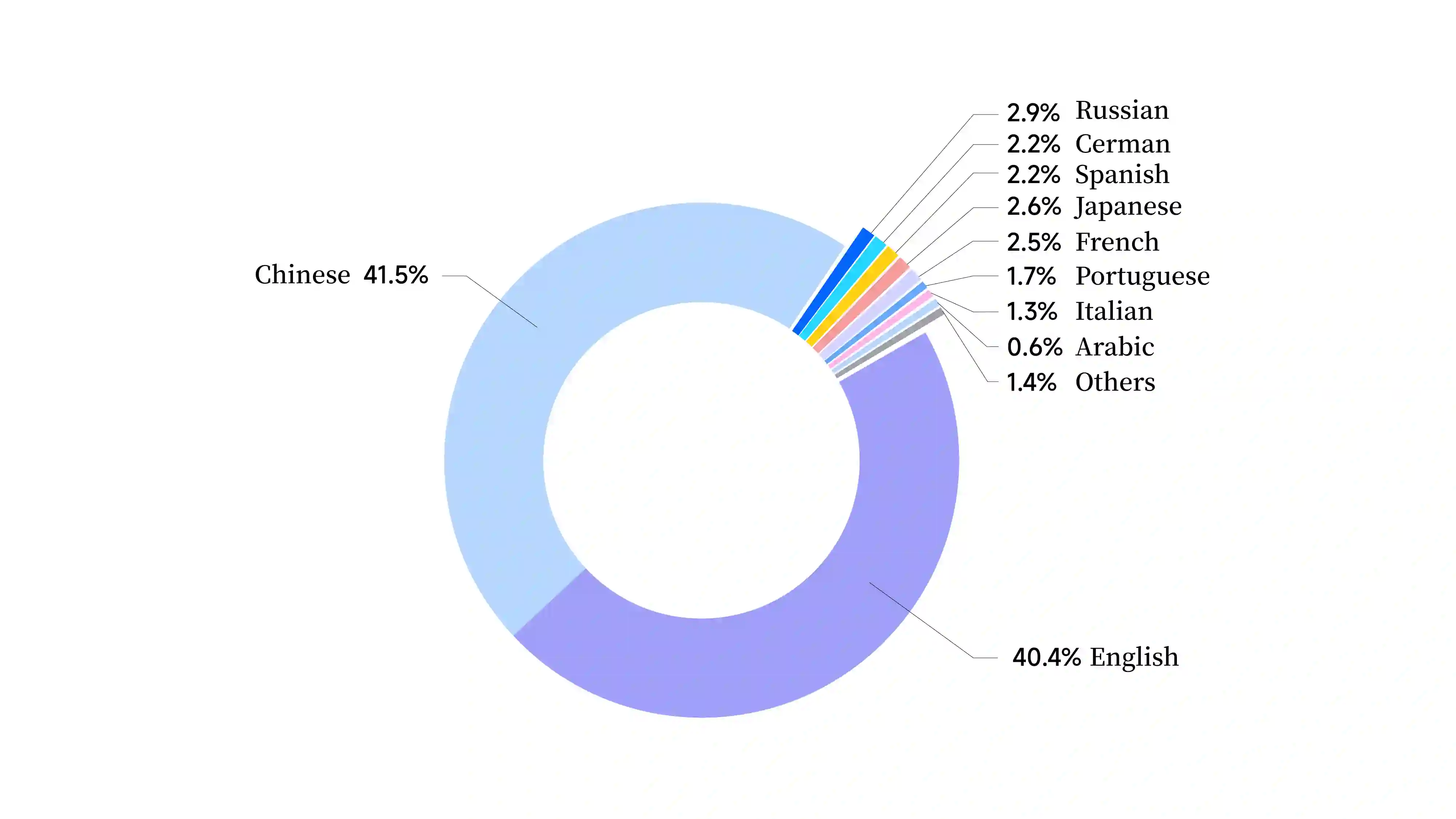
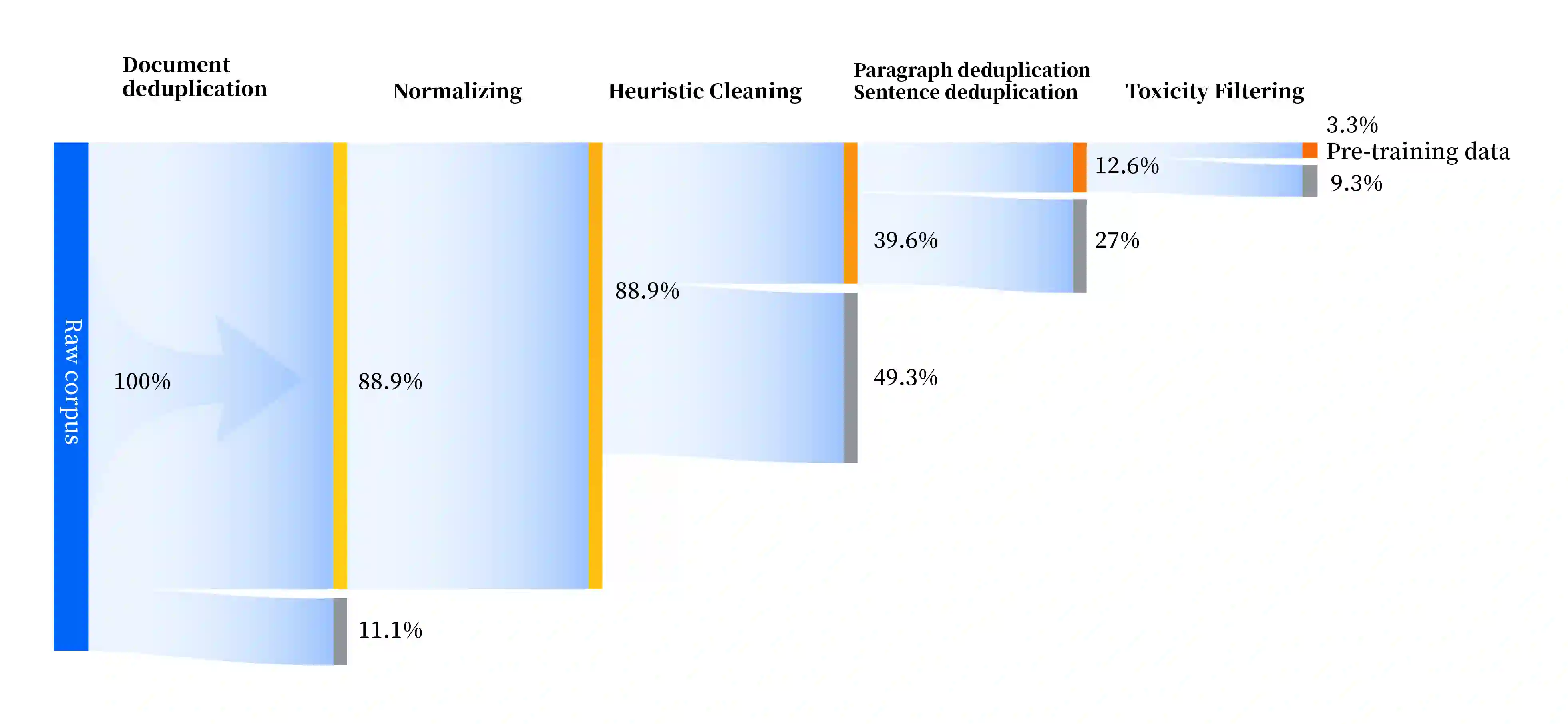
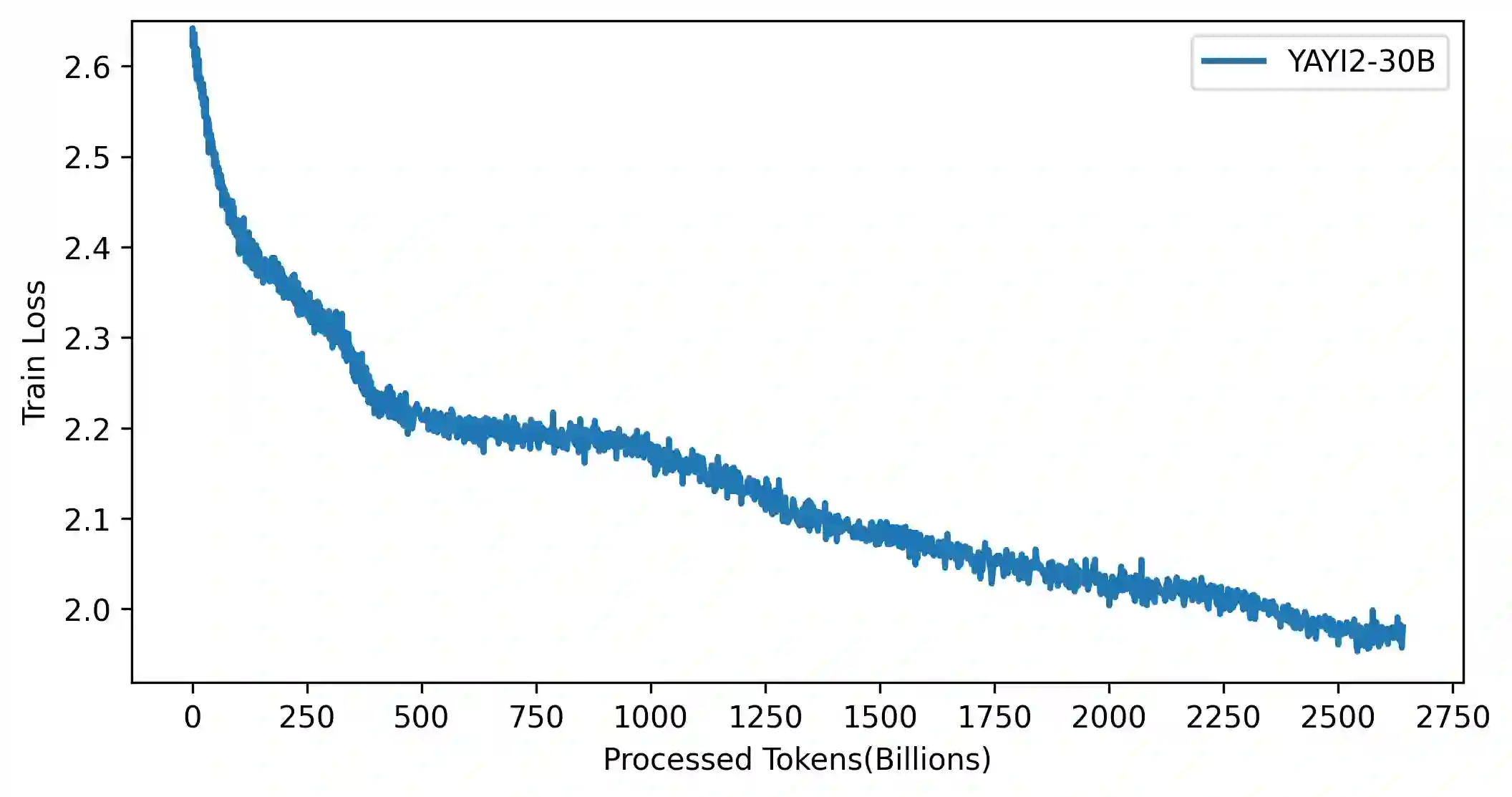
As the latest advancements in natural language processing, large language models (LLMs) have achieved human-level language understanding and generation abilities in many real-world tasks, and even have been regarded as a potential path to the artificial general intelligence. To better facilitate research on LLMs, many open-source LLMs, such as Llama 2 and Falcon, have recently been proposed and gained comparable performances to proprietary models. However, these models are primarily designed for English scenarios and exhibit poor performances in Chinese contexts. In this technical report, we propose YAYI 2, including both base and chat models, with 30 billion parameters. YAYI 2 is pre-trained from scratch on a multilingual corpus which contains 2.65 trillion tokens filtered by our pre-training data processing pipeline. The base model is aligned with human values through supervised fine-tuning with millions of instructions and reinforcement learning from human feedback. Extensive experiments on multiple benchmarks, such as MMLU and CMMLU, consistently demonstrate that the proposed YAYI 2 outperforms other similar sized open-source models.
翻译:作为自然语言处理领域的最新进展,大语言模型(LLMs)已在许多现实任务中展现出人类水平的语言理解与生成能力,甚至被视为通向通用人工智能的潜在路径。为更好地促进LLMs研究,近期涌现出众多开源大语言模型(如Llama 2与Falcon),其性能已可与专有模型媲美。然而,这些模型主要面向英文场景设计,在中文语境下表现欠佳。本技术报告提出包含基座模型与对话模型的YAYI 2系列,其参数量达300亿。该模型基于我们预训练数据处理流水线过滤的2.65万亿token多语言语料库从头训练。基座模型通过数百万条指令的监督微调及基于人类反馈的强化学习实现与人类价值观的对齐。在MMLU、CMMLU等多个基准测试上的大量实验一致表明,所提出的YAYI 2性能优于其他同等规模的开源模型。