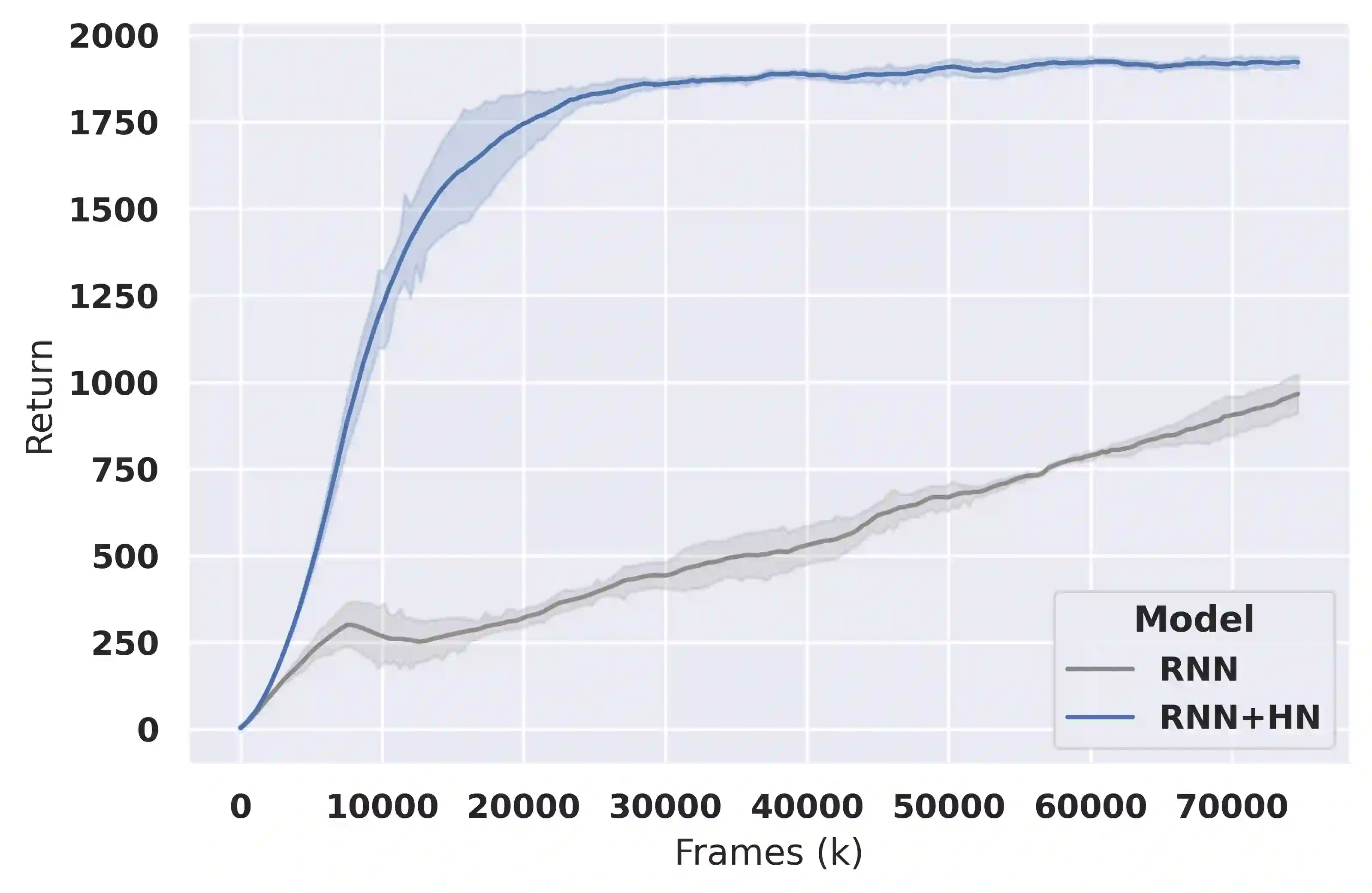
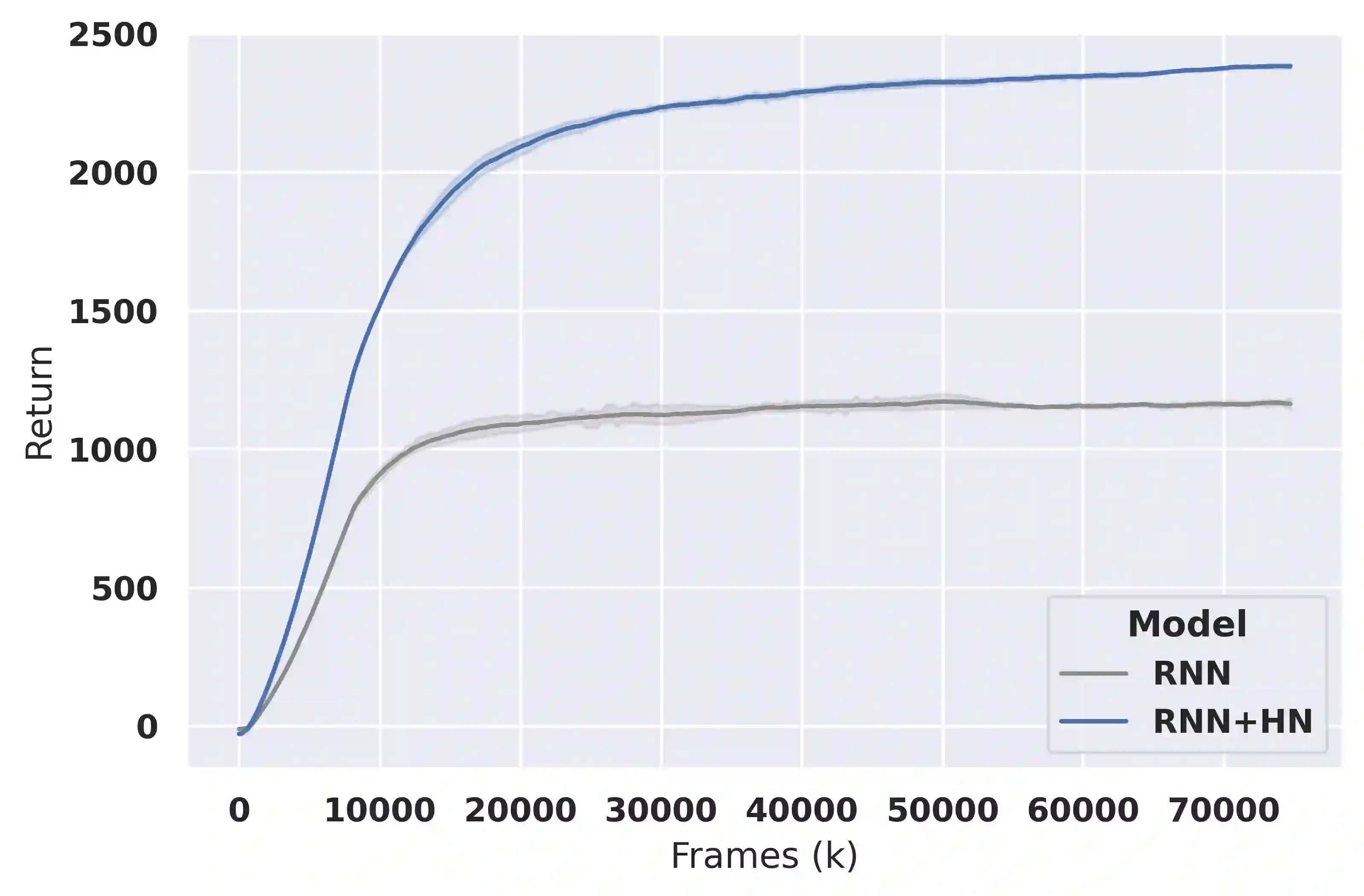
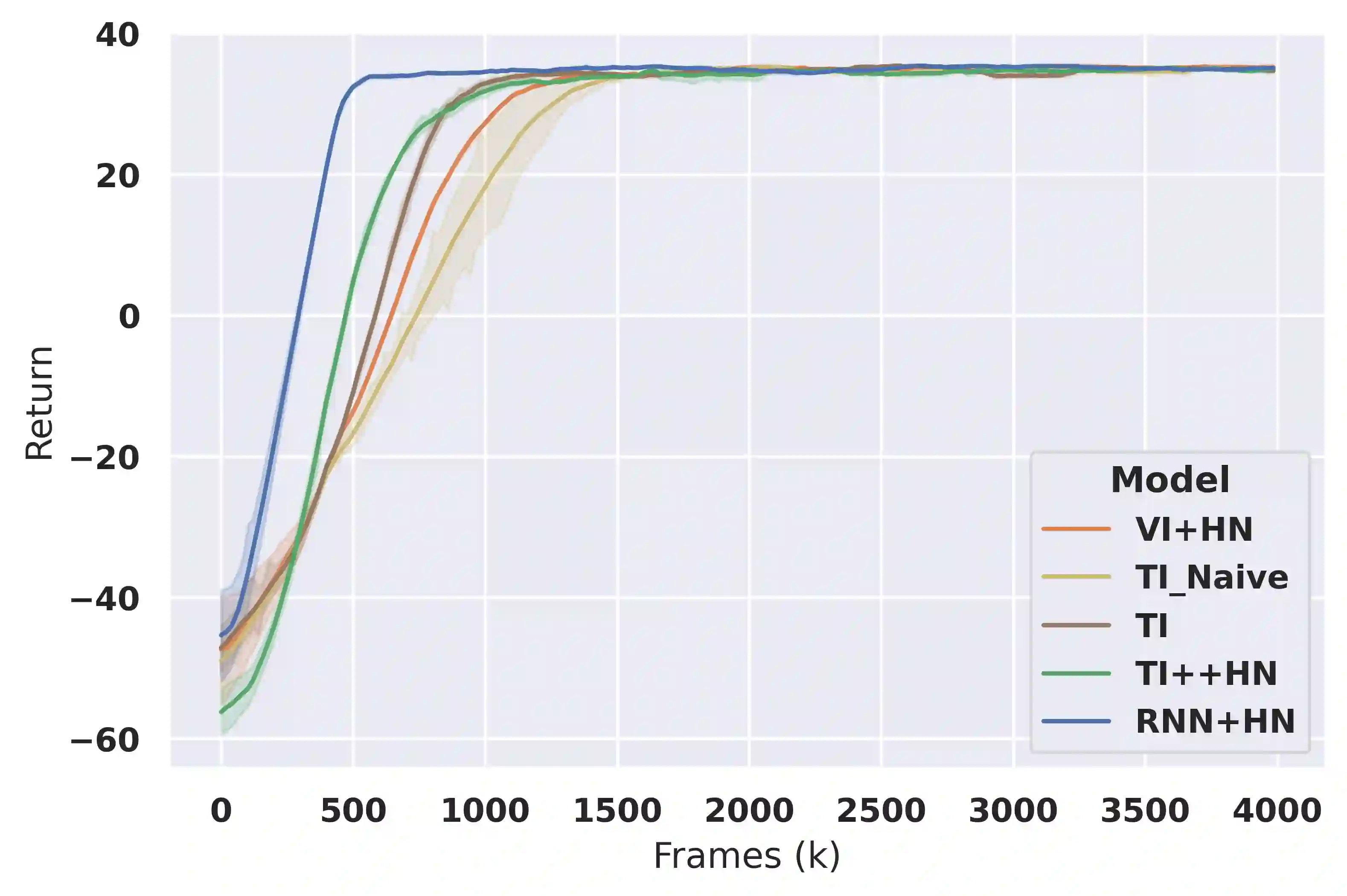
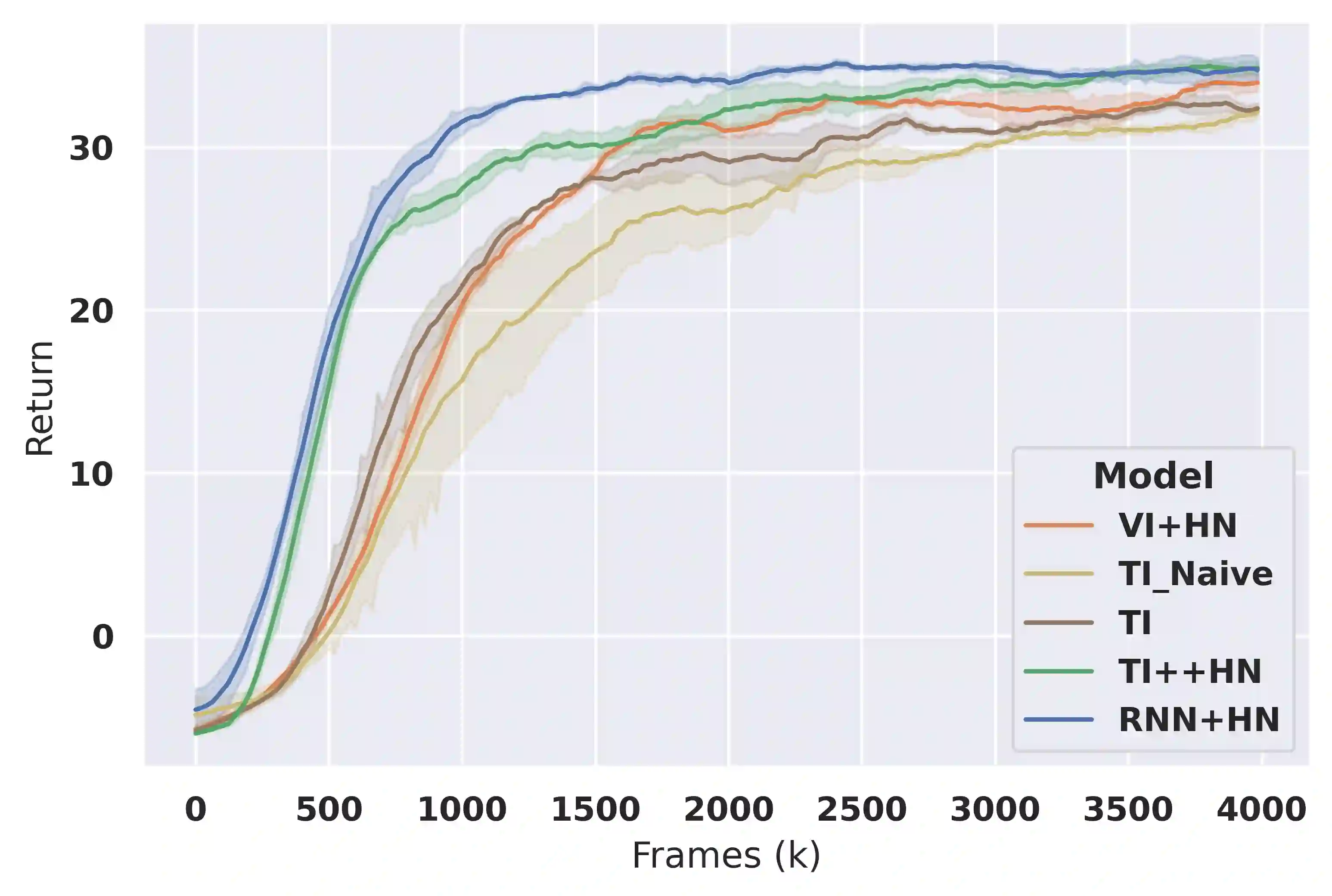
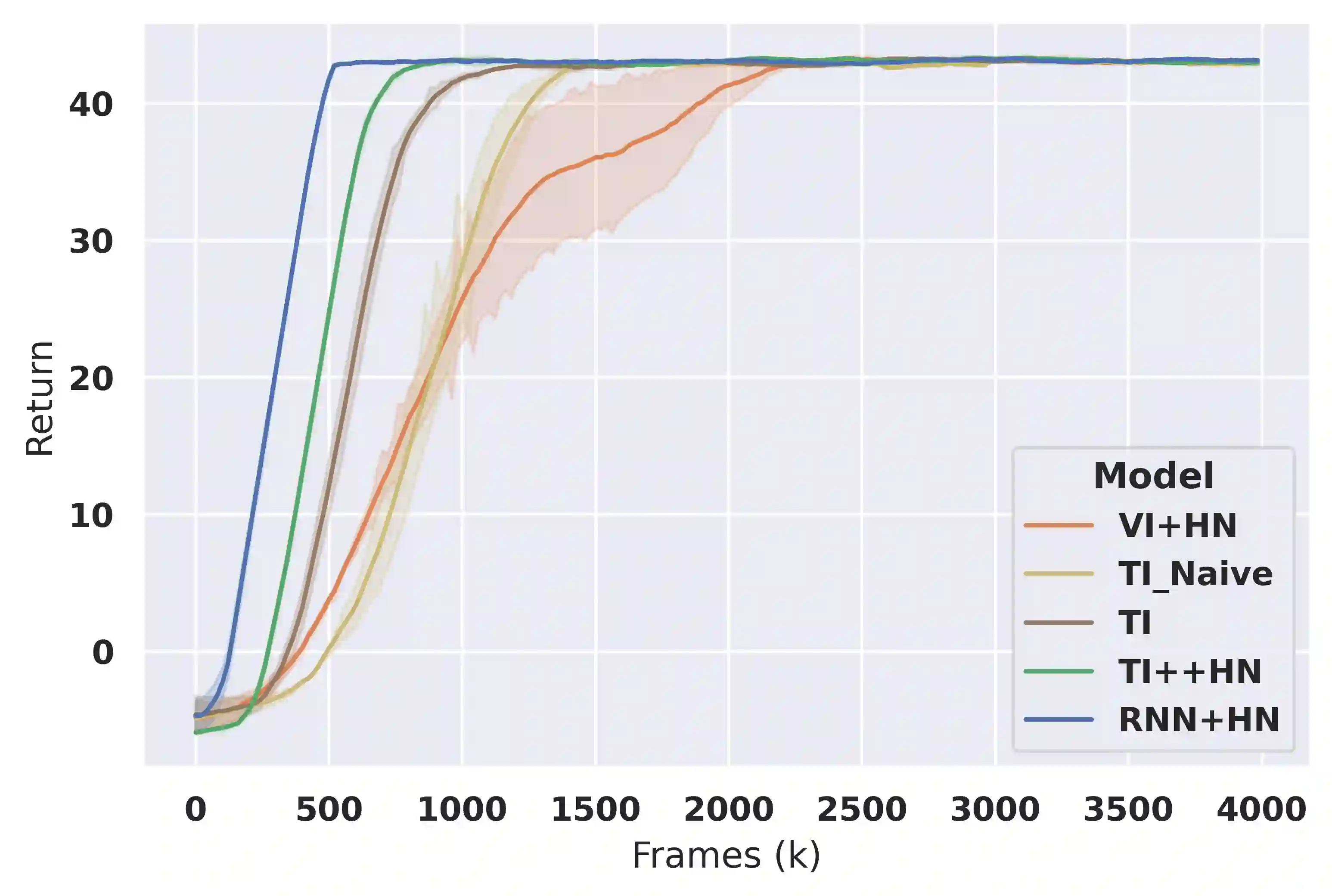
Deep reinforcement learning (RL) is notoriously impractical to deploy due to sample inefficiency. Meta-RL directly addresses this sample inefficiency by learning to perform few-shot learning when a distribution of related tasks is available for meta-training. While many specialized meta-RL methods have been proposed, recent work suggests that end-to-end learning in conjunction with an off-the-shelf sequential model, such as a recurrent network, is a surprisingly strong baseline. However, such claims have been controversial due to limited supporting evidence, particularly in the face of prior work establishing precisely the opposite. In this paper, we conduct an empirical investigation. While we likewise find that a recurrent network can achieve strong performance, we demonstrate that the use of hypernetworks is crucial to maximizing their potential. Surprisingly, when combined with hypernetworks, the recurrent baselines that are far simpler than existing specialized methods actually achieve the strongest performance of all methods evaluated.
翻译:深度强化学习(RL)因样本效率低下而难以实际部署。元强化学习通过利用相关任务分布进行元训练,学习执行小样本学习,直接解决了这一样本效率问题。尽管已有许多专门的元强化学习方法被提出,但近期研究表明,结合现成序列模型(如递归网络)的端到端学习是一个出人意料的强基线。然而,由于支持证据有限,此类说法一直存在争议,尤其是面对先前工作确立的恰恰相反的结论。在本文中,我们进行了实证研究。尽管我们同样发现递归网络能够实现强性能,但我们证明了超网络的使用对于最大化其潜力至关重要。令人惊讶的是,当与超网络结合时,比现有专门方法简单得多的递归基线实际上在所有评估方法中取得了最强的性能。