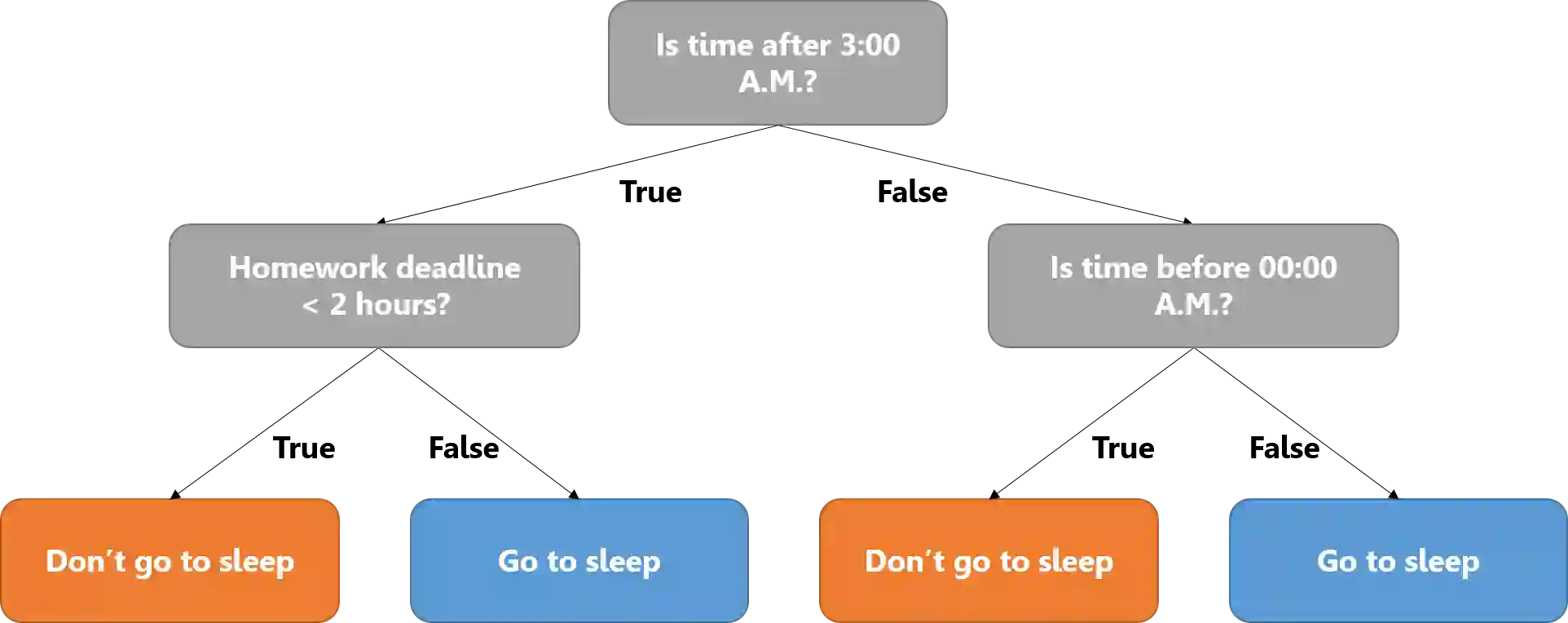
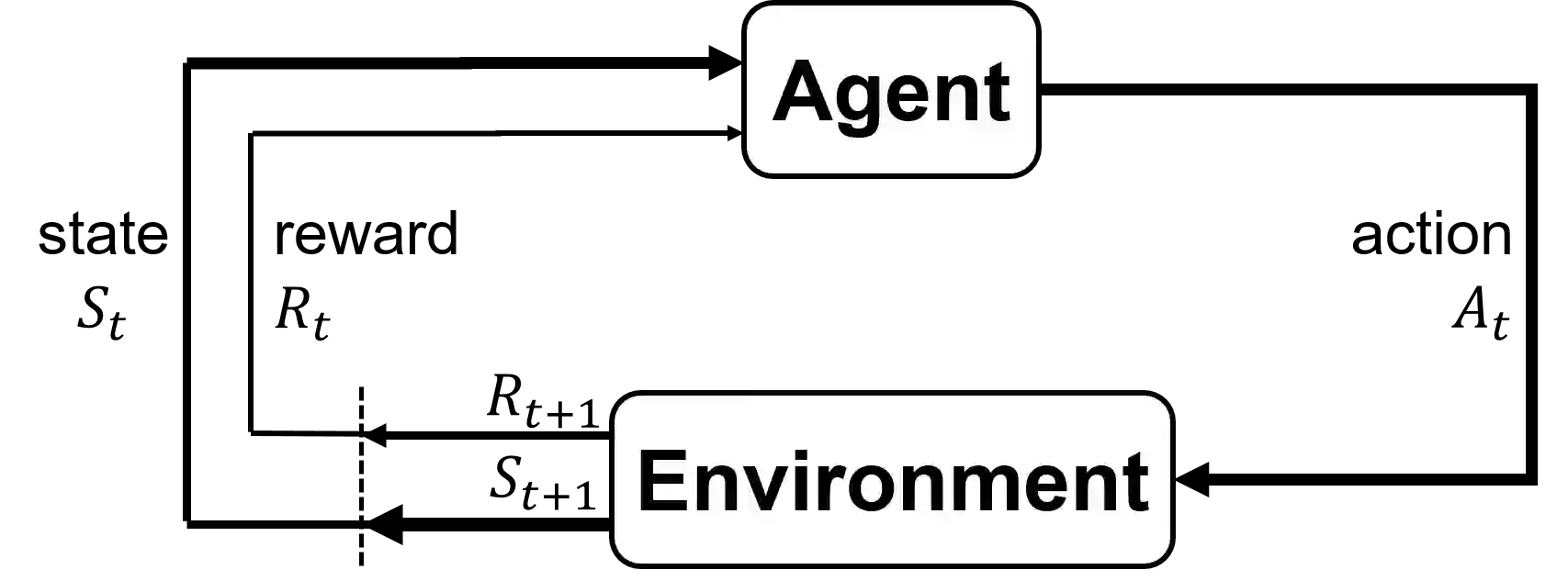
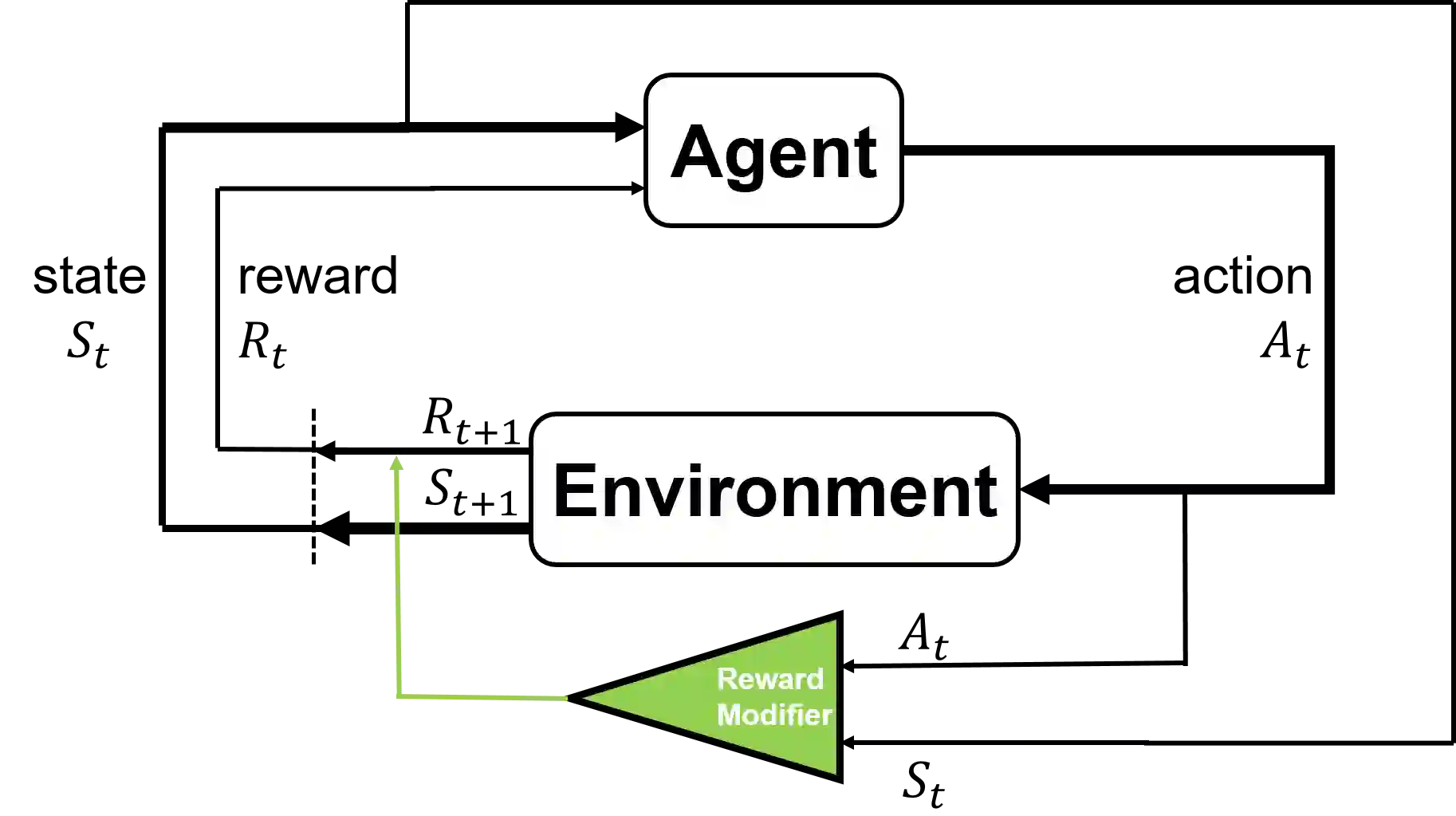
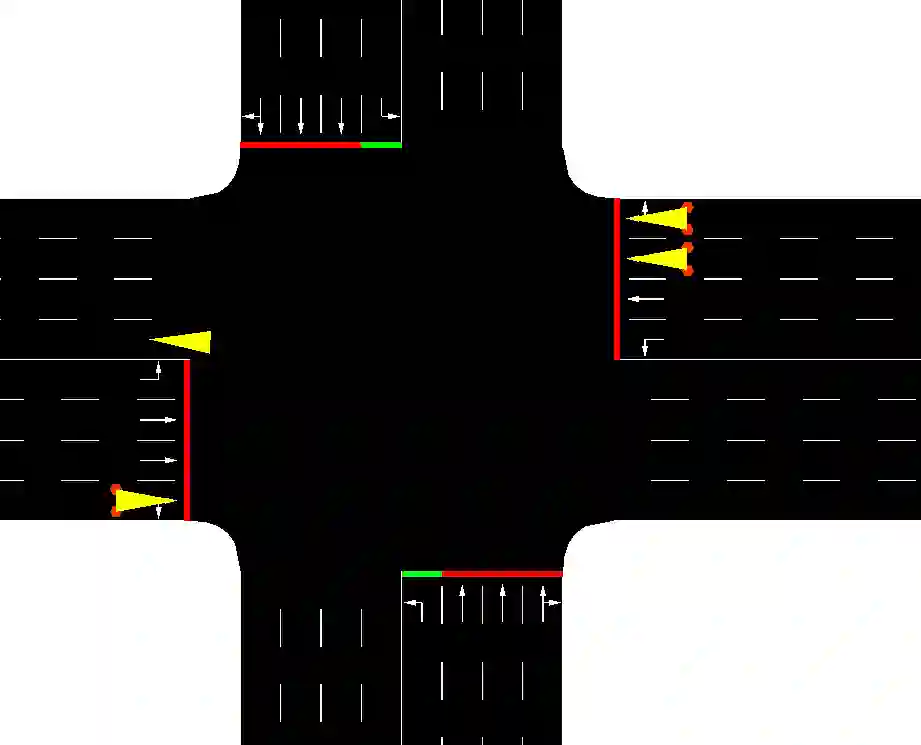
Deep reinforcement learning (DRL) has proven extremely useful in a large variety of application domains. However, even successful DRL-based software can exhibit highly undesirable behavior. This is due to DRL training being based on maximizing a reward function, which typically captures general trends but cannot precisely capture, or rule out, certain behaviors of the system. In this paper, we propose a novel framework aimed at drastically reducing the undesirable behavior of DRL-based software, while maintaining its excellent performance. In addition, our framework can assist in providing engineers with a comprehensible characterization of such undesirable behavior. Under the hood, our approach is based on extracting decision tree classifiers from erroneous state-action pairs, and then integrating these trees into the DRL training loop, penalizing the system whenever it performs an error. We provide a proof-of-concept implementation of our approach, and use it to evaluate the technique on three significant case studies. We find that our approach can extend existing frameworks in a straightforward manner, and incurs only a slight overhead in training time. Further, it incurs only a very slight hit to performance, or even in some cases - improves it, while significantly reducing the frequency of undesirable behavior.
翻译:深度强化学习已在众多应用领域展现出极大的实用性。然而,即使是基于深度强化学习的成功软件,也可能表现出高度不良的行为。这是因为深度强化学习的训练基于最大化奖励函数,该函数通常能捕捉总体趋势,但无法精确捕捉或排除系统的某些行为。本文提出了一种新颖框架,旨在大幅减少基于深度强化学习软件的不良行为,同时保持其优异性能。此外,该框架还能帮助工程师清晰理解此类不良行为的特征。本方法的核心在于从错误的状态-动作对中提取决策树分类器,并将其整合到深度强化学习训练循环中,在系统执行错误时施加惩罚。我们实现了该方法的验证原型,并通过三个重要案例研究对其进行了评估。结果表明,本方法能简便地扩展现有框架,且仅增加轻微的训练时间开销。同时,它对性能的影响极小,甚至在某些情况下还能提升性能,同时显著降低不良行为的发生频率。