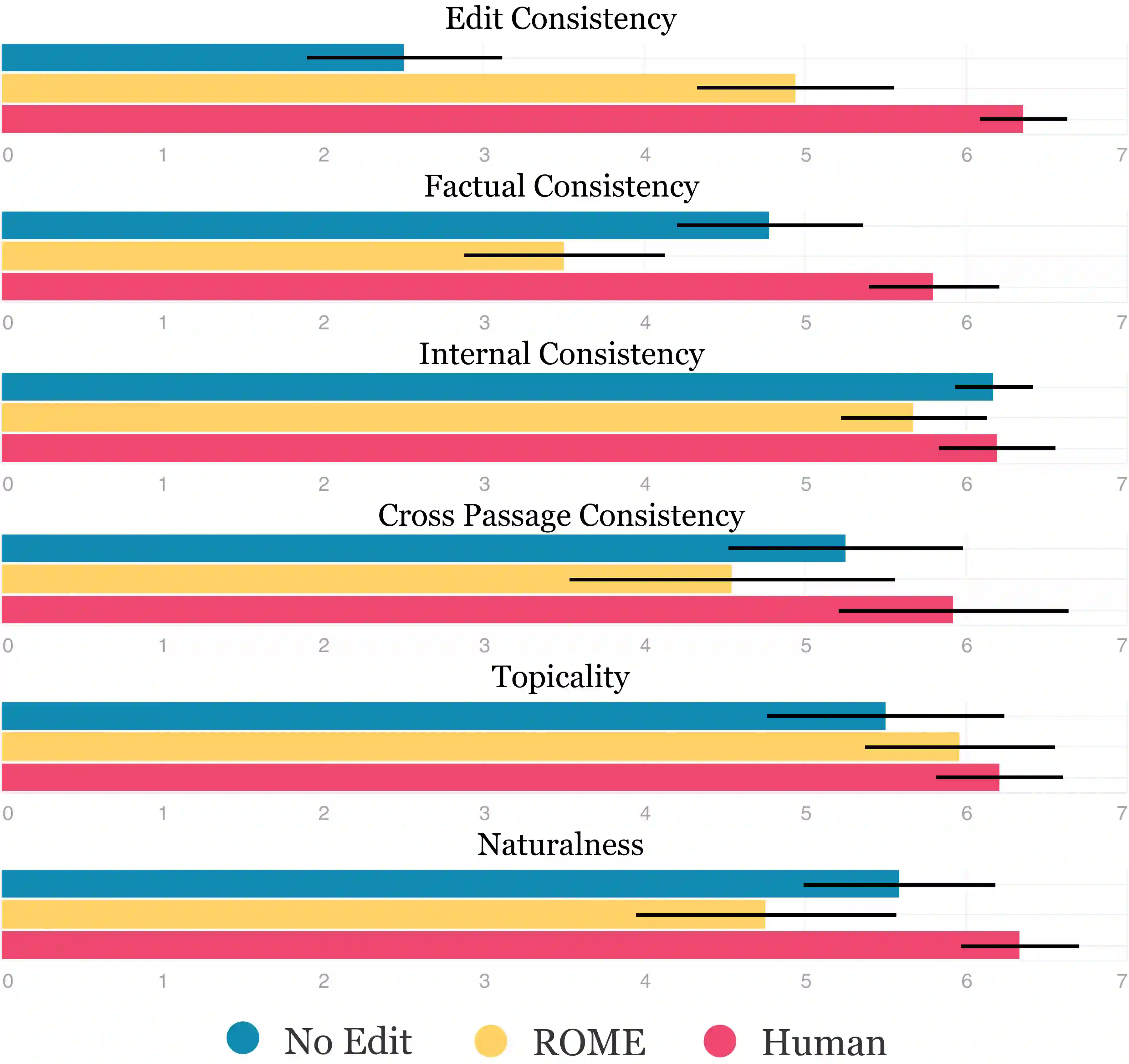
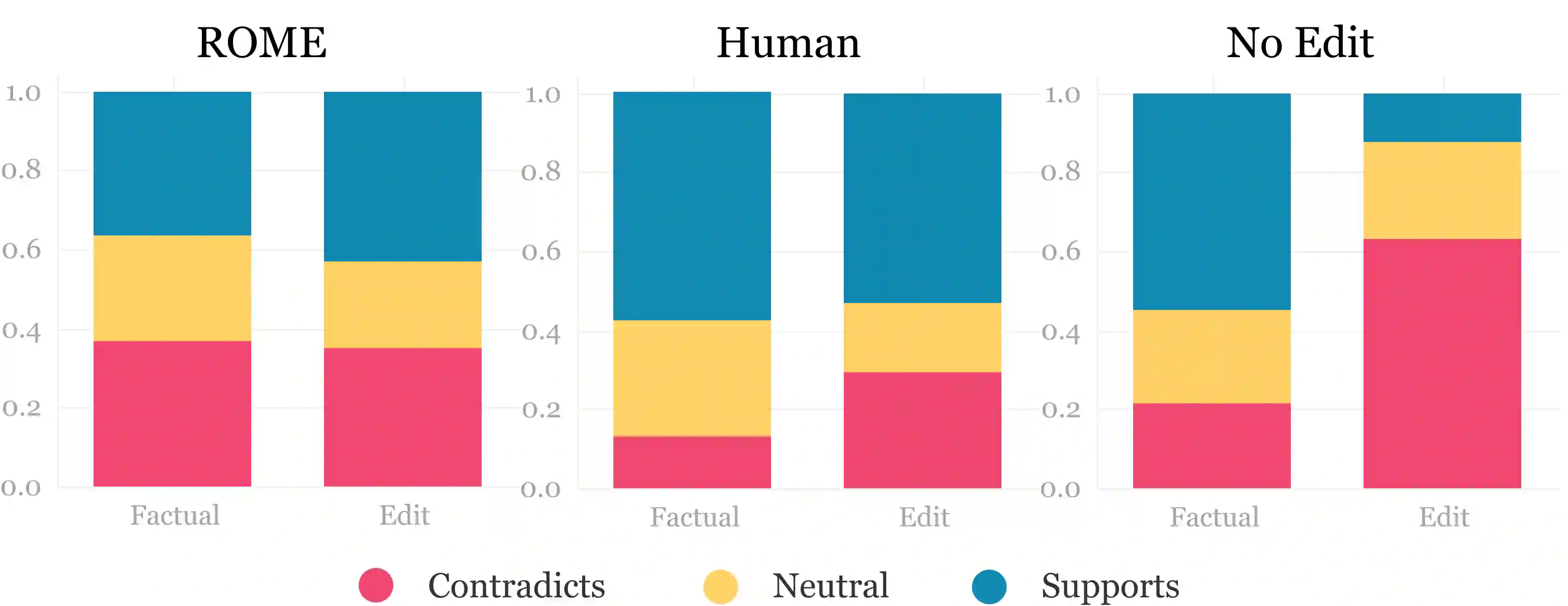
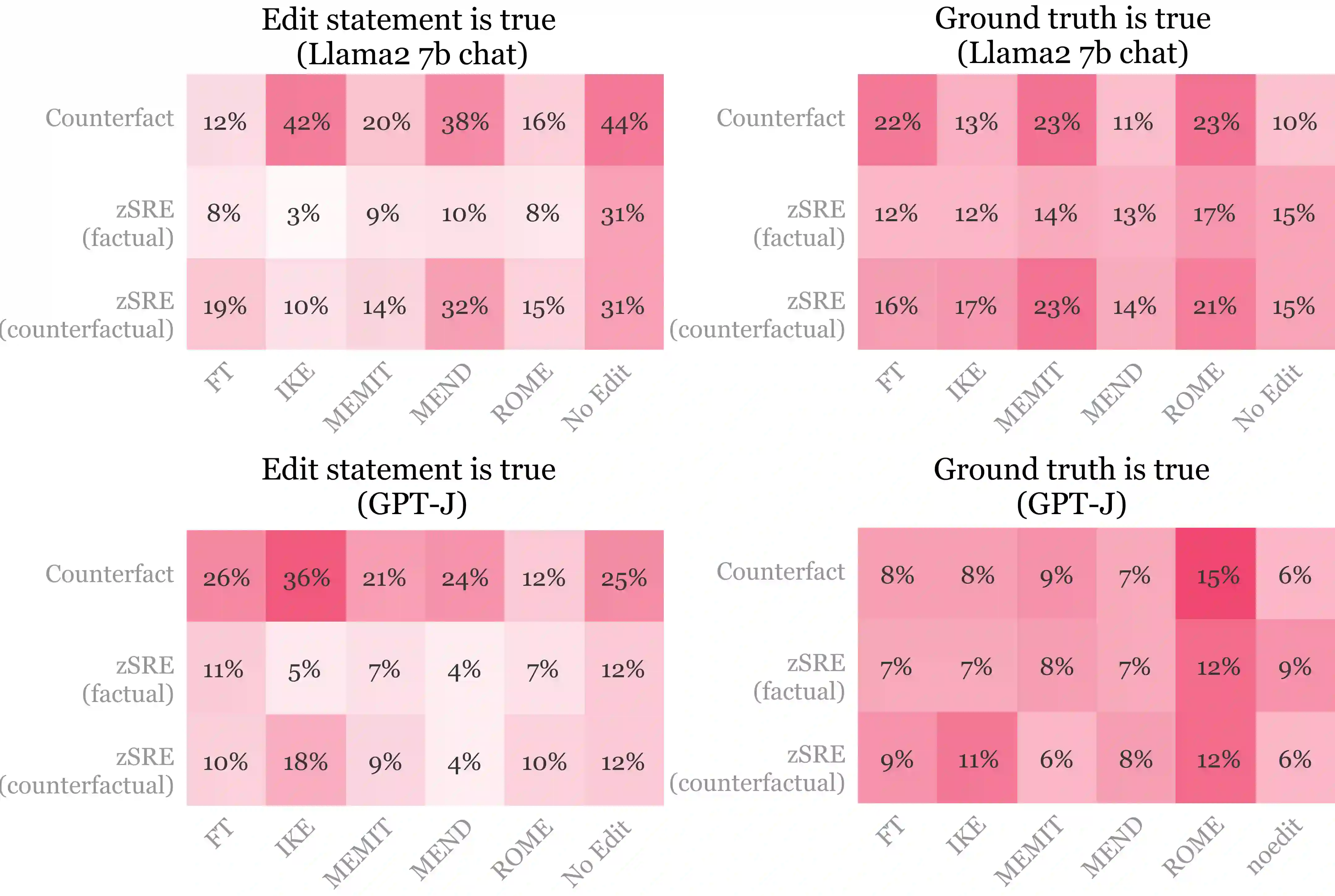
Evaluations of model editing currently only use the `next few token' completions after a prompt. As a result, the impact of these methods on longer natural language generation is largely unknown. We introduce long-form evaluation of model editing (\textbf{\textit{LEME}}) a novel evaluation protocol that measures the efficacy and impact of model editing in long-form generative settings. Our protocol consists of a machine-rated survey and a classifier which correlates well with human ratings. Importantly, we find that our protocol has very little relationship with previous short-form metrics (despite being designed to extend efficacy, generalization, locality, and portability into a long-form setting), indicating that our method introduces a novel set of dimensions for understanding model editing methods. Using this protocol, we benchmark a number of model editing techniques and present several findings including that, while some methods (ROME and MEMIT) perform well in making consistent edits within a limited scope, they suffer much more from factual drift than other methods. Finally, we present a qualitative analysis that illustrates common failure modes in long-form generative settings including internal consistency, lexical cohesion, and locality issues.
翻译:模型编辑的评估目前仅使用提示后的“接下来几个词”的补全。因此,这些方法对更长自然语言生成的影响在很大程度上是未知的。我们引入了模型编辑的长形式评估(**LEME**),这是一种新颖的评估协议,用于衡量模型编辑在长形式生成设置中的有效性和影响。我们的协议包括一个机器评分的调查和一个与人类评分相关性良好的分类器。重要的是,我们发现我们的协议与之前的短形式指标几乎没有关系(尽管这些指标旨在将有效性、泛化性、局部性和可移植性扩展到长形式设置),这表明我们的方法引入了一套新的维度来理解模型编辑方法。使用这一协议,我们对多种模型编辑技术进行了基准测试,并提出了几项发现,包括:尽管某些方法(如ROME和MEMIT)在有限范围内进行一致编辑方面表现良好,但它们在事实漂移方面比其他方法严重得多。最后,我们提供了一项定性分析,展示了长形式生成设置中常见的失败模式,包括内部一致性、词汇衔接和局部性问题。