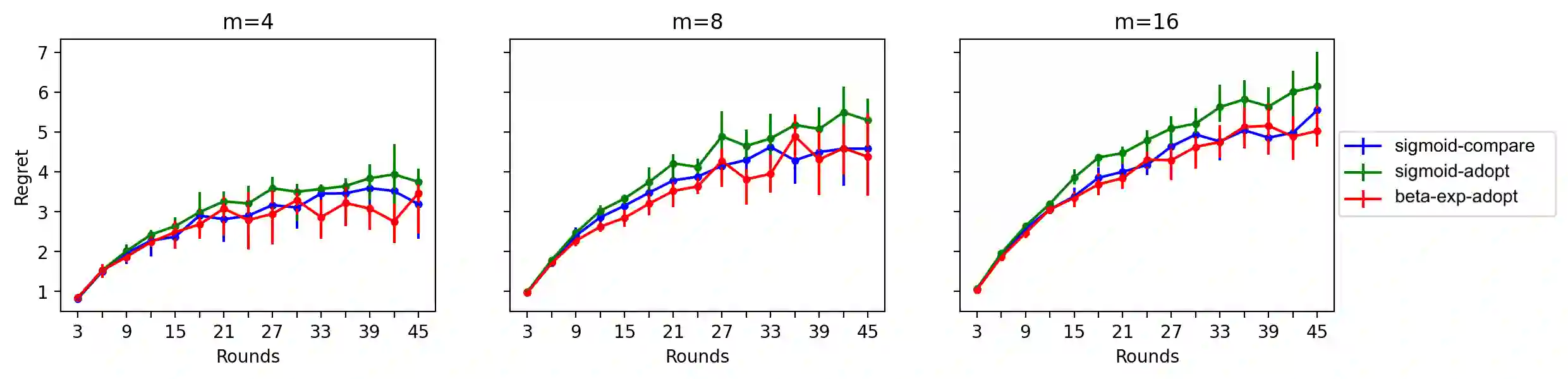
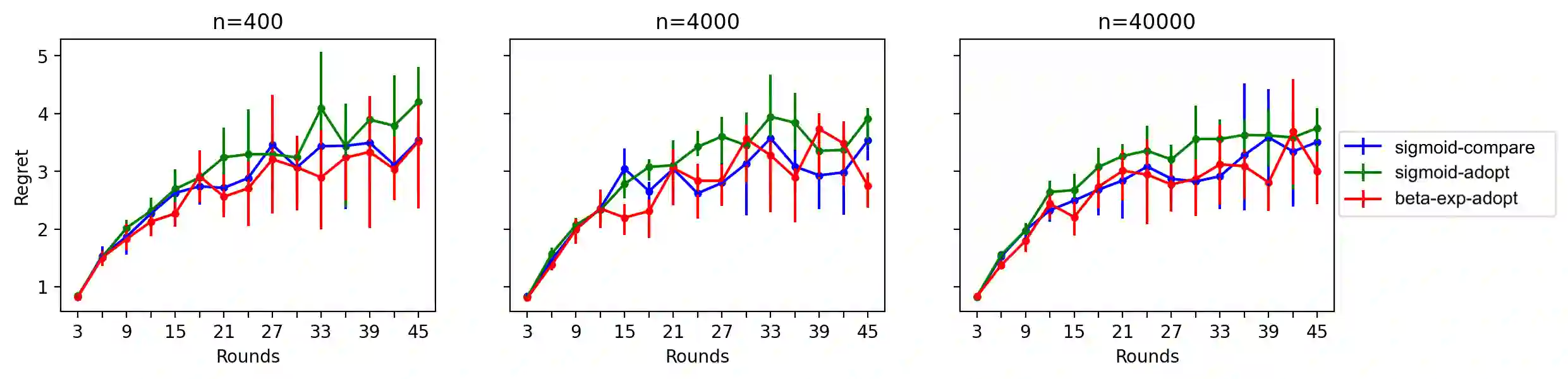
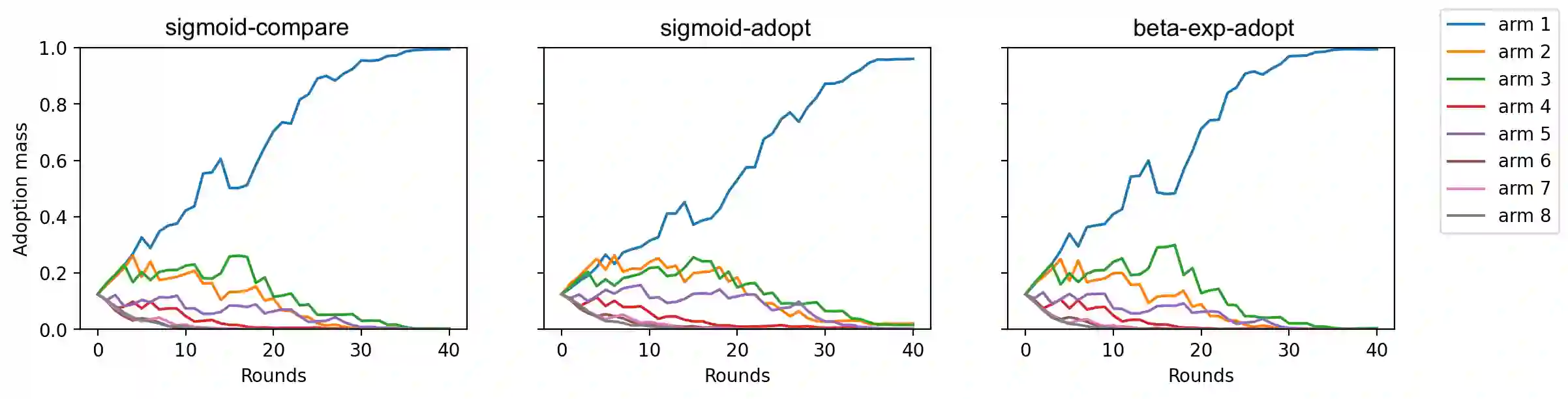
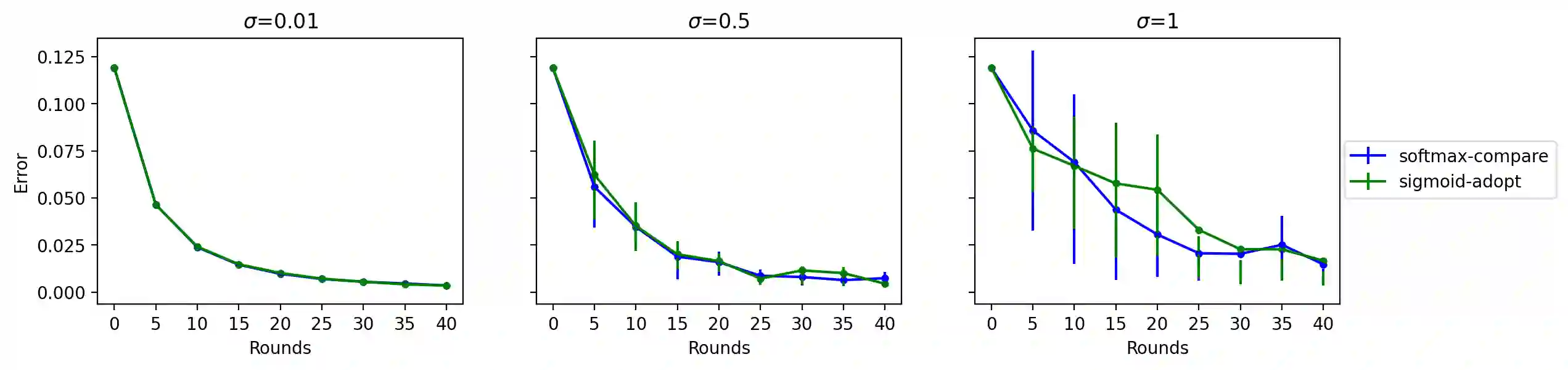
We study a cooperative multi-agent bandit setting in the distributed GOSSIP model: in every round, each of $n$ agents chooses an action from a common set, observes the action's corresponding reward, and subsequently exchanges information with a single randomly chosen neighbor, which informs its policy in the next round. We introduce and analyze several families of fully-decentralized local algorithms in this setting under the constraint that each agent has only constant memory. We highlight a connection between the global evolution of such decentralized algorithms and a new class of "zero-sum" multiplicative weights update methods, and we develop a general framework for analyzing the population-level regret of these natural protocols. Using this framework, we derive sublinear regret bounds for both stationary and adversarial reward settings. Moreover, we show that these simple local algorithms can approximately optimize convex functions over the simplex, assuming that the reward distributions are generated from a stochastic gradient oracle.
翻译:我们研究了分布式GOSSIP模型下的合作多智能体bandit问题:在每个轮次中,$n$个智能体各自从公共集合中选择一个动作,观察该动作对应的奖励,随后与单个随机选择的邻居交换信息,该信息将影响下一轮次的策略。我们在每个智能体仅拥有恒定内存的约束下,提出并分析了几类完全去中心化的局部算法。我们揭示了此类去中心化算法的全局演化与一类新型“零和”乘法权重更新方法之间的关联,并发展了一个通用框架来分析这些自然协议的群体级遗憾。利用该框架,我们为平稳和对抗性奖励设置推导出次线性遗憾界。此外,我们证明,若奖励分布由随机梯度预言机生成,这些简单的局部算法可以近似优化单纯形上的凸函数。